 RAG 是智能体的必经之路?别被这个叙事绑架了当你的 Agent 需要回答"我们公司 Q3 营收是多少"这个问题时,你会怎么做?按照行业默认剧本,你需要把公司财报拆成小块,送进嵌入模型生成向量,存入 Pinecone 或者 Chroma,然后用户提问时做一次相似度检索,把最相关的几段文本塞回 Prompt 交给大模型——这就是 RAG。
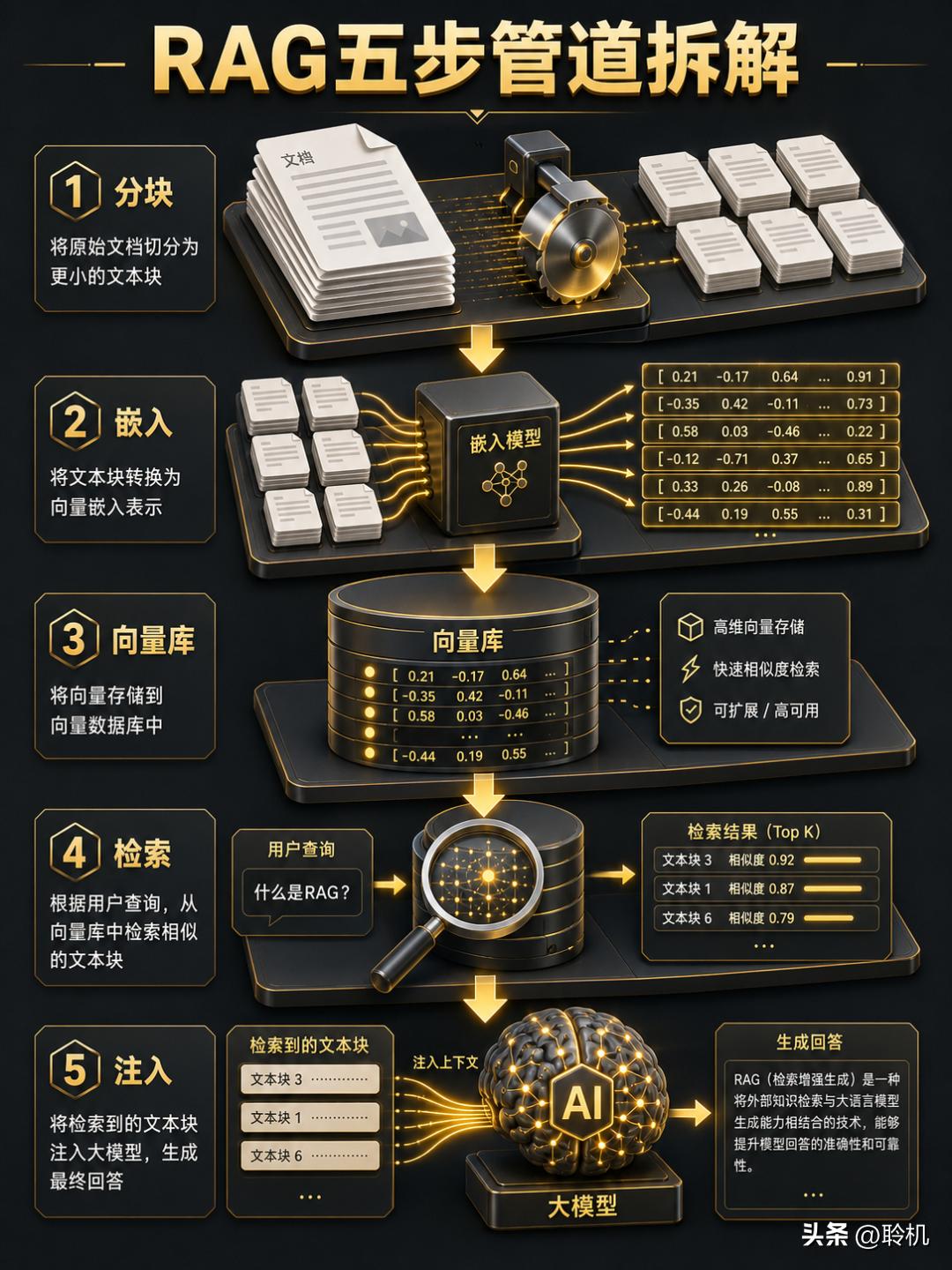
RAG 是智能体的必经之路?别被这个叙事绑架了当你的 Agent 需要回答"我们公司 Q3 营收是多少"这个问题时,你会怎么做?按照行业默认剧本,你需要把公司财报拆成小块,送进嵌入模型生成向量,存入 Pinecone 或者 Chroma,然后用户提问时做一次相似度检索,把最相关的几段文本塞回 Prompt 交给大模型——这就是 RAG。但这个过程太重了。文档分块选 512 还是 1024?嵌入模型选 text-embedding-3-large 还是 BGE?向量数据库选 Pinecone 还是本地 FAISS?相似度用余弦还是 L2?要不要加重排序?要不要做查询改写?每一个问题背后都是一整周的调试。你只是想让 Agent 回答一个问题,却先花了三周搭管道。
所以问题来了:RAG 真的是绕不过去的坎吗?必须得用吗?答案是——不是。而且这个"不是"有非常具体的技术理由。
先拆清楚:RAG 到底在干什么要把这个问题说透,得先把 RAG 这个概念从神坛上拉下来。
大模型有一个硬限制:训练完成的那一刻,它脑子里的知识就凝固了。它不知道你公司的财报数据,不知道你知识库里的内部文档,不知道昨天刚发的 API 文档。Karpathy 把大模型比作一个新操作系统的内核进程——而大模型的 context window(上下文窗口)就像 RAM,context window 里装的信息就像内存里加载的文件。
RAG 解决的核心问题只有一个:把外部知识塞进大模型的上下文窗口。
LangChain 在 Deconstructing RAG 一文中把 RAG 管道拆成了五个环节:查询变换(Query Transformation)、路由(Routing)、查询构造(Query Construction)、索引(Indexing)、后处理(Post-Processing)。每个环节里又藏着十几二十个参数等你调。chunk size(分块大小)这一个参数,OpenAI 在自己的 RAG 策略评测中就发现"简单的调整就能带来显著的性能提升"——这意味着如果不调,你的 RAG 就在亏损运行。
这就是你讨厌 RAG 的原因。你讨厌的不是"检索外部知识"这个动作,而是围绕这个动作搭建的那整套笨重的工程管道。这种工程负担有一个名字——"RAG 工程税"。
打个具体的算术:一个三人的工程团队,搭建一套生产级 RAG 系统,光是选型、原型、调参、压测,保守估计两到四周。上线之后还得持续维护——文档更新了要重新嵌入,嵌入模型升级了要全量重算向量,检索质量不好要反复调试 chunk size 和 overlap 比例。每一个环节都是真金白银的人力成本,而且这些问题在 demo 数据上永远不会暴露,一上真实数据就翻车。
 不用 RAG,还有三条路
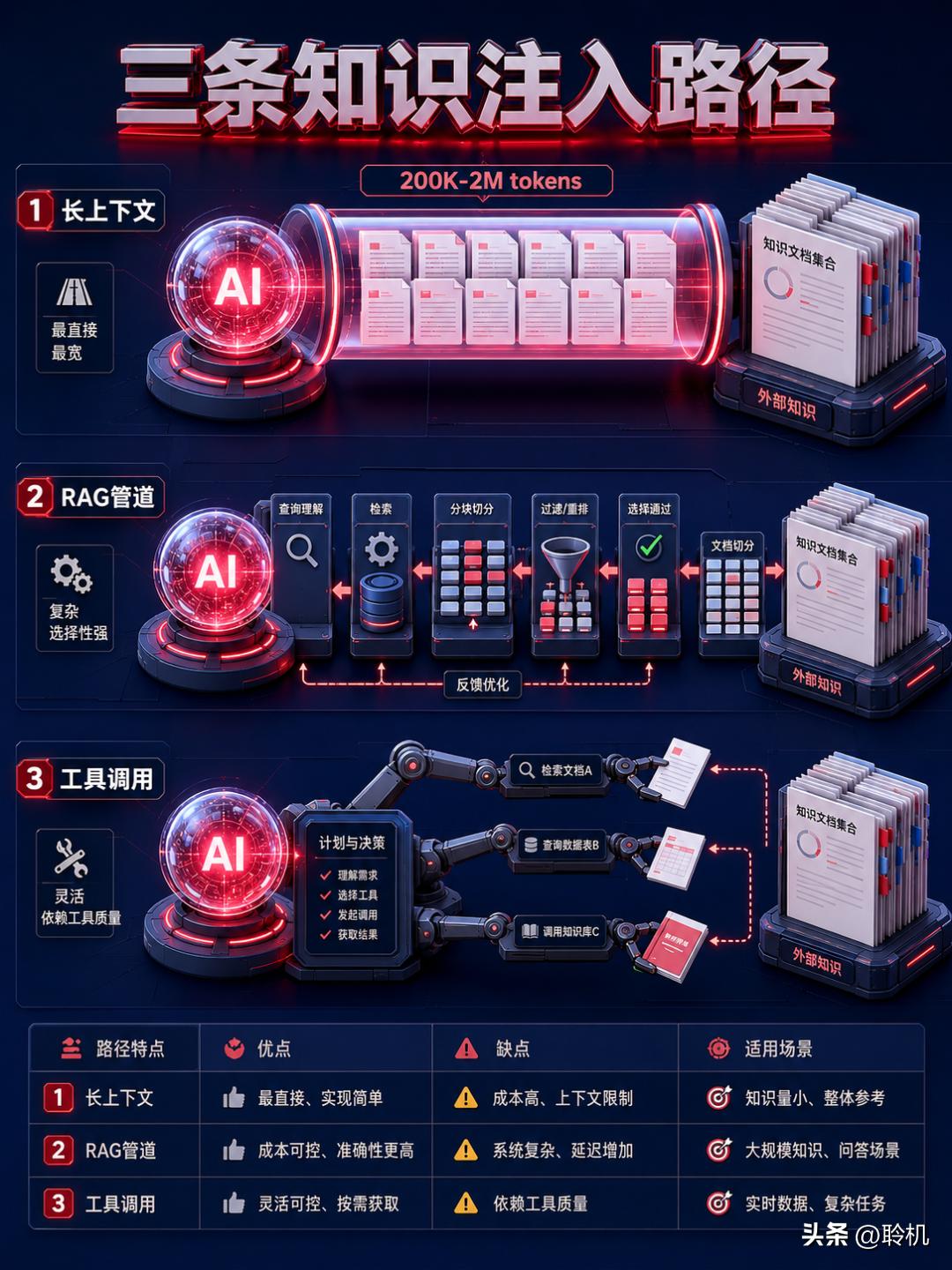
不用 RAG,还有三条路既然 RAG 的本质是"把外部知识注入大模型的上下文窗口",那这个动作就不止一种做法。除掉 RAG 这条路,至少还有三条:
第一条:直接塞进上下文窗口(Long Context)
Claude 2.1 给了 200K token 的上下文窗口——大约 15 万字,500 页材料。Gemini 1.5 Pro 更夸张,直接给到 200 万 token。如果你的知识库总共就几万字的技术文档,为什么要搞向量数据库?直接全部塞进 context window 就行了。
Claude 在官方博客里原话是这么说的:用户现在可以把整个代码库、财报 S-1 文件、甚至《伊利亚特》《奥德赛》这样的长篇文学作品整个丢进去。上传文档,直接对话,没有嵌入,没有向量,没有检索管道。
第二条:让 Agent 自己用工具(Tool Use)
Claude 2.1 同时发布了 Tool Use(工具调用)功能。你可以给大模型定义一组工具——数据库查询 API、网页搜索接口、内部知识库检索函数——然后大模型自己决定什么时候调用哪个工具。
这个思路和传统 RAG 有本质区别。传统 RAG 是"每次查询都先检索再说",不管有没有必要。而 Agent 工具调用是"大模型判断需不需要检索,需要的时候才去查"。这就是 Self-RAG 论文(arXiv:2310.11511)提出的核心思想:模型通过 self-reflection tokens(反思标记)自适应地决定何时检索、检索结果是否相关、生成内容是否被证据支持。
实验结果很硬:Self-RAG 的 7B 和 13B 参数模型在开放域问答、推理和事实验证任务上显著超过了 ChatGPT 和带检索增强的 Llama2-chat。
第三条:结构化数据用 Text-to-SQL
如果你的知识存储在关系型数据库里,那就更没必要搞向量 RAG 了。直接让大模型把自然语言转成 SQL 查询,数据库返回精确结果。LangChain 已经提供了开箱即用的 Text-to-SQL 模板,连本地 LLM 都能跑。pgvector 扩展甚至让你在同一个 PostgreSQL 里同时做结构化查询和语义搜索。
这种方案的优势在于精确性。向量检索是模糊匹配,问你"营收多少",它可能给你一段提到营收但不是核心数据的文本片段。而 SQL 查询直接返回数字。
 200 万 token 的甜蜜陷阱
200 万 token 的甜蜜陷阱看到这里你可能想:那直接用长上下文不就行了?为什么还要 RAG?
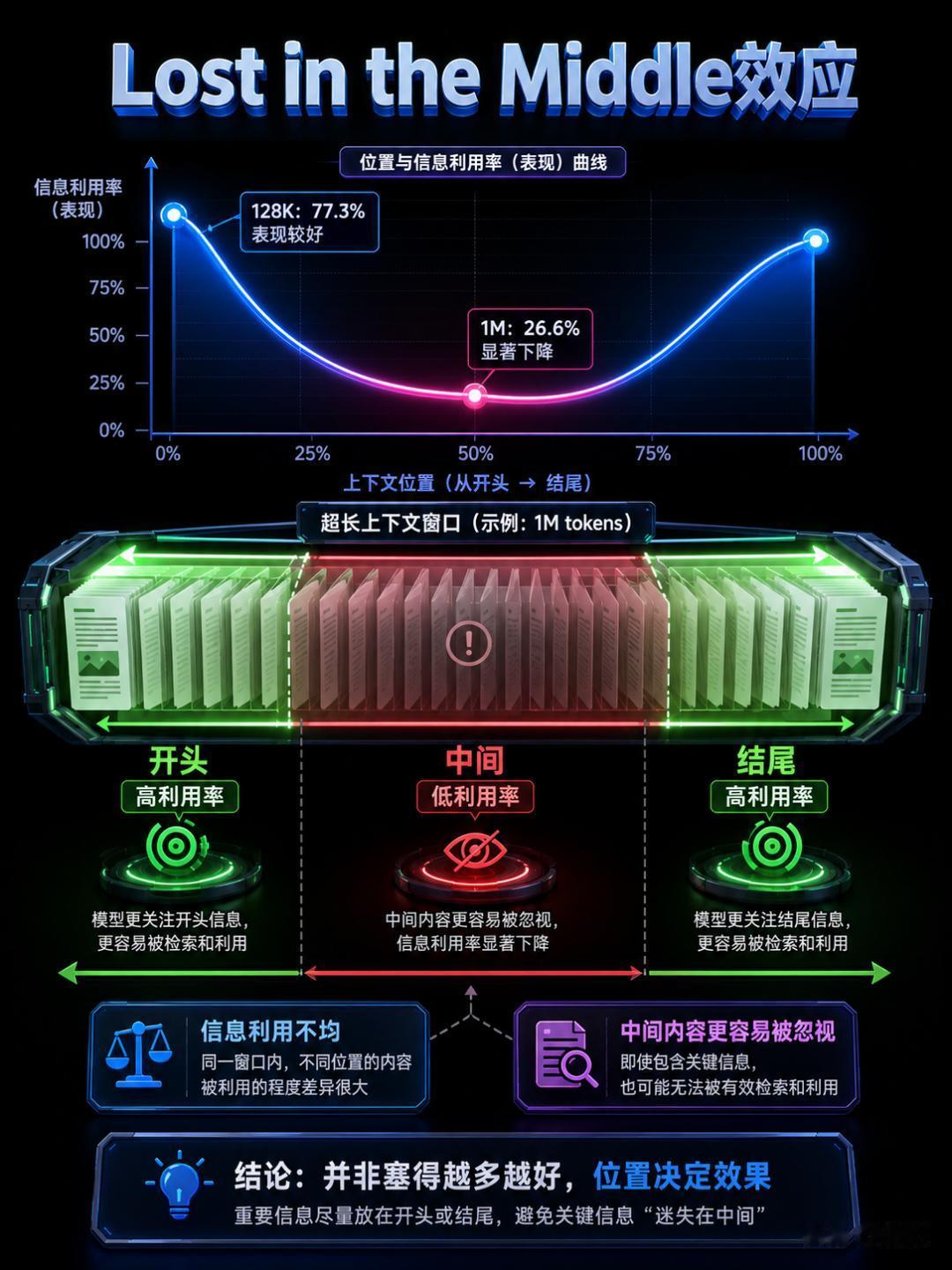
因为长上下文有一个致命的硬伤,学术界叫它 "Lost in the Middle"(迷失在中间)。
斯坦福大学的 Nelson F. Liu 等人在 TACL 2023 发表的论文中发现了一个反直觉的现象:当相关信息出现在上下文的开头或结尾时,模型表现最好;但当相关信息被夹在长文本的中间位置时,模型的利用率显著下降——即使这些模型声称支持超长上下文。
更扎心的是 Databricks 在 2024 年 8 月发表的那篇研究。他们跑了超过 2000 次实验,测了 13 个主流模型(GPT-4o、Claude-3.5-Sonnet、Llama-3.1-405b 等),结论是:
Llama-3.1-405b 在 32K token 之后性能开始下降GPT-4 在 64K token 之后开始下降只有极少数模型能在所有数据集上保持稳定的长上下文性能Gemini 自己的数据也印证了这一点:在 MRCR v2 的 8-needle 长上下文测试中,128K 平均得分 77.3%,但拉到 1M(100 万 token)时,逐点得分直接掉到 26.6%。
这意味着什么?宣称支持 200 万 token 的上下文窗口,和有效利用 200 万 token 的上下文,是完全不同的两件事。你把一整本书塞进去了,模型可能只认真读了开头和结尾,中间几百页大概率在被忽略。
还有一个更现实的问题:成本。200 万 token 每次调用的费用,和你精准检索 5 个 512 token 的文档块,价格差距是几十甚至上百倍。在高并发的生产环境中,这个成本差距直接决定了你的产品能不能活下来。
 Agent 工具调用:正在发生的选项迁移
Agent 工具调用:正在发生的选项迁移如果说长上下文是"简单粗暴但有限制"的替代方案,那 Agent 工具调用就是正在发生的更深层的变化。
回到 Anthropic 的 Tool Use 发布公告:Claude 现在可以"编排(orchestrate)开发者定义的函数或 API,搜索网络资源,从私有知识库检索信息"。注意这里的用词——编排。不是被动地等用户触发检索,而是大模型主动判断需要什么信息,然后调用对应工具去获取。
这跟传统 RAG 的差别在哪?
传统 RAG 是一个固定的管道:用户问什么 → 嵌入查询 → 向量检索 → 返回 Top-K → 生成回答。这个流程不管你的问题是简单还是复杂,不管你需不需要外部信息,都会执行。
而 Agent 工具调用的模式是:大模型先理解你的问题,判断需要哪些信息,然后有选择地调用工具。如果问题它自己能答,就不调用任何工具。如果需要查数据库,就调 SQL 工具。如果需要实时信息,就调 Web 搜索。如果需要检索内部文档,就调向量检索工具。
LangChain 在 Self-Reflective RAG 博客中描述了这种"认知架构"的演化:从简单的 Chain(链式),到 Routing(路由),再到 State Machine(状态机)——支持循环和反馈的状态机架构,才是 Agentic RAG 的真正形态。
比如 Corrective RAG(CRAG):先用一个轻量级评估器检查检索质量,如果检索结果不靠谱,就改写查询,甚至直接去 Web 搜索补充。Self-RAG 则通过 ISREL 标记判断段落是否相关,通过 ISSUP 标记判断生成内容是否被段落支撑,通过 ISUSE 标记评估回答的有用程度。
这些方案本质上都在做一件事:把"要不要检索""检索什么""检索结果好不好"这些决策权,从固定的工程管道移交给了大模型自己。你不再需要一个写死的 RAG pipeline——你需要的是给 Agent 一组好用的工具。
那到底什么时候必须用 RAG?说了这么多替代方案,RAG 并没有被消灭。在以下场景里,RAG 仍然是不可替代的:
第一,知识体量超出上下文窗口。 如果你有一个包含 50 万份文档的企业知识库,总量可能达到数亿 token。就算 Gemini 给你 200 万 token 的窗口,也只能装下极小一部分。这种场景下,你需要某种形式的检索来缩小范围——不管是向量检索还是关键词检索。Databricks 的实验数据显示,在某些数据集上,检索召回率要一直到 96K-128K token 才会饱和。
第二,多用户访问控制。 你的 Agent 服务 1000 个用户,每个用户只能看到自己有权限的文档。长上下文方案需要为每个用户动态加载不同文档,这在工程上更复杂。而向量数据库可以配合 metadata 过滤,精确控制每个用户的检索范围。
第三,成本敏感的高并发场景。 每次请求塞 200 万 token 和每次请求检索 5 个 512 token 的文档块,成本差距是数量级的。在生产环境中,这个差距就是生与死的区别。
第四,需要精确的来源引用。 合规、法律、医疗场景下,你需要知道模型回答的每一个事实来自哪份文档的哪一段。RAG 天然支持这种追溯。
但即使在这些场景里,RAG 的形态也在变。Anthropic 在 2024 年提出的 Contextual Retrieval(上下文检索)方案就是一个信号:在嵌入每个文档块之前,先用 LLM 加一段上下文前缀(比如"这段内容来自 A 公司 2024 Q3 财报的营收增长章节"),再用 BM25(传统关键词匹配)加上嵌入向量做混合检索,最后加重排序。这一套组合拳把检索失败率降低了 49%。
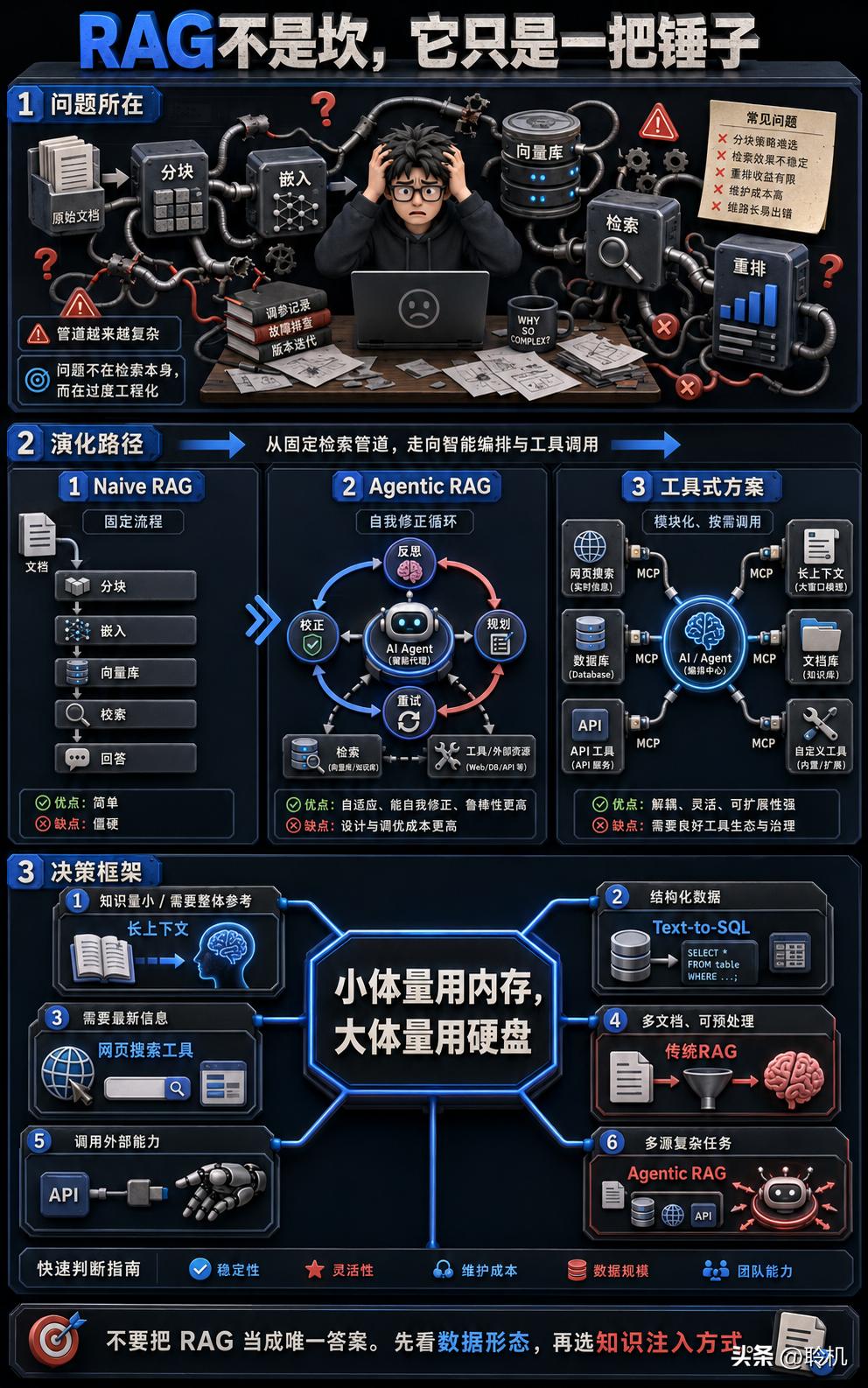
RAG 没有死,但 Naive RAG(朴素 RAG)——那种随便切几块、嵌个向量、查个 Top-5 的做法——确实该淘汰了。行业正在从"Pipeline RAG"(固定管道式检索)向"Agentic RAG"(Agent 驱动的自适应检索)迁移,而后者在工程复杂度和灵活性上都远优于前者。
一张选择矩阵:你到底该用什么说了这么多,落到实操上。下次你构建 Agent 面临知识注入问题时,用这个框架快速判断:

你的场景
推荐方案
为什么
文档总量 < 200K token
直接塞进上下文
省掉整个 RAG 管道,零维护成本
结构化数据(数据库表格)
Text-to-SQL
精确查询,比向量检索更准
需要实时信息
Web 搜索工具
本地知识库永远比互联网慢
少量 API 可获取的数据
Agent 工具调用
LLM 自主决定何时查询
海量非结构化文档(>200K token)
RAG(但用 Contextual Retrieval)
唯一能处理超大体量的方案
需要多来源、多步骤推理
Agentic RAG(工具+检索混合)
Agent 自主编排各类信息源
核心判断逻辑其实很朴素:你的知识体量决定了你是否需要检索。小体量用内存(上下文窗口),大体量用硬盘(向量数据库+检索)。就像你的电脑,不会为了打开一个 10KB 的文本文件去走磁盘 I/O,但也不会把 500GB 的数据库全部加载到内存。
别问"要不要用 RAG",问"你的知识需要什么注入策略"回到最开始那个问题:RAG 是绕不过去的坎吗?
如果你问的是"要不要做知识检索和注入"——那大概率是的。大模型的参数化知识有截止日期,你需要某种方式把外部信息喂给它。
但如果你问的是"要不要搭建传统 RAG 管道"(文档分块 → 嵌入向量 → 向量数据库 → 相似度检索)——那答案取决于你的场景。
当 Claude 给你 200K token 窗口,Gemini 给你 200 万 token 窗口,当 Tool Use 让 Agent 自己决定何时检索,当 MCP 协议开始标准化 Agent 与数据源的连接——传统 RAG 管道在很多场景下已经变成了一种过度工程。
未来正在往什么方向走?大模型正在变成一个越来越聪明的"内核进程",它的 context window(RAM)在变大,它的 tool use 能力在变强。RAG 正在从"你必须搭建的固定管道"变成"Agent 可以调用的工具之一"。MCP 协议的出现更是加速了这个进程——它让 Agent 连接外部数据源的方式标准化了。以前你要给 Agent 接一个内部知识库,得自己写检索逻辑、处理认证、维护连接。现在通过 MCP,数据源暴露成标准接口,Agent 想用就用,不想用就忽略。知识检索变成了一个标准化的、即插即用的工具,而不是你需要从零搭建的工程系统。
所以你的下一步该干什么?别急着搭 RAG。先问自己三个问题:我的知识有多大?我的用户有多少?我需要多高的精确度?然后对着那张选择矩阵找答案。你可能会发现,很多场景下,不搭 RAG 管道反而是更正确的工程决策。
RAG 不是坎,它只是你工具箱里的一把锤子。不是所有问题都是钉子。
记住一个简单的判断:能塞进上下文的就别搭管道,结构化数据就别用向量,实时信息就别存本地。只有在知识体量真正超过模型上下文窗口、并且无法通过工具调用解决的时候,RAG 才是你最好的朋友。而到了那个时候,也请用 Contextual Retrieval 加 BM25 混合检索加重排序的完整方案,而不是随便切几块就丢进向量库的偷懒做法。