[LG]《MDPO: Overcoming the Training-Inference Divide of Masked Diffusion Language Models》H He, K Renz, Y Cao, A Geiger [University of Tübingen] (2025)
MDPO:破解Masked Diffusion Language Models训练与推理不匹配的难题
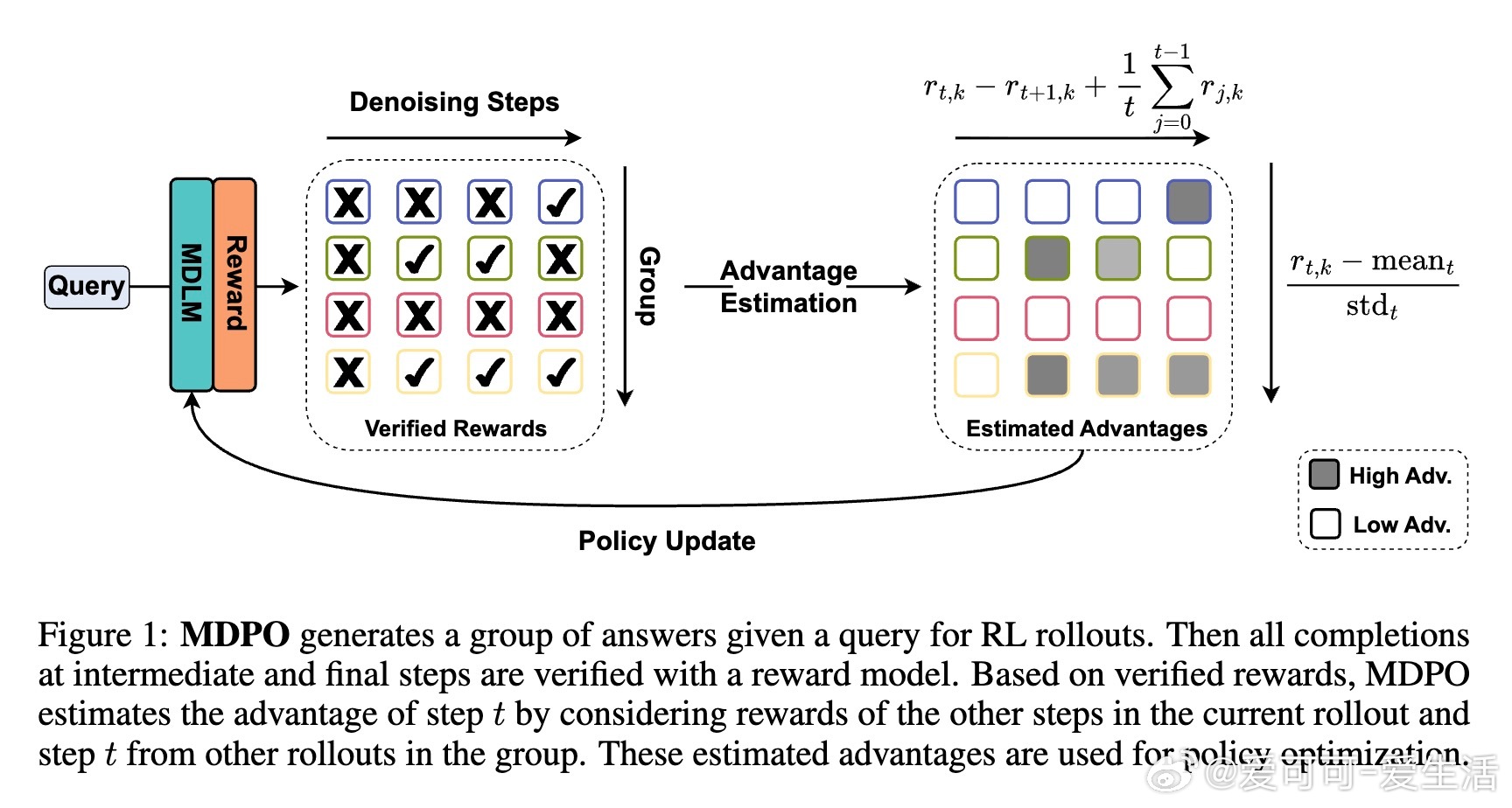
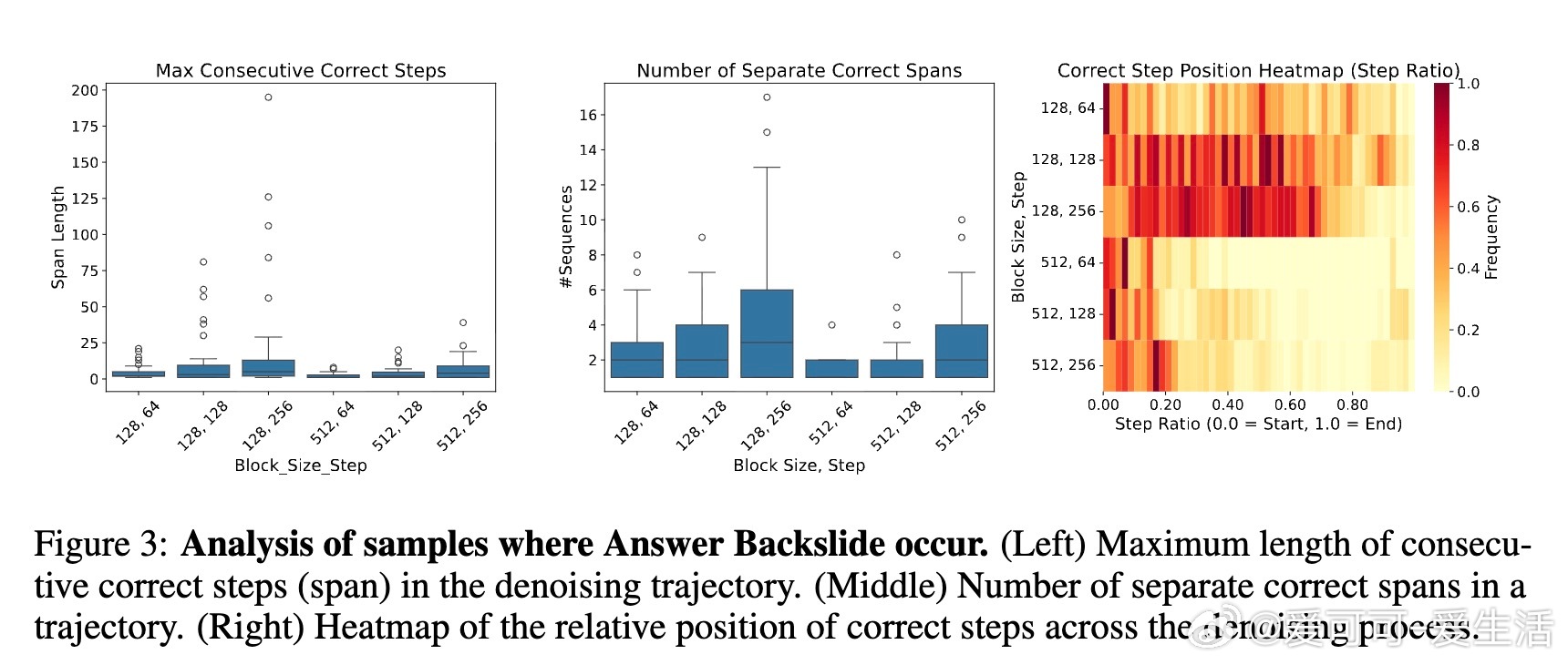
• 现象捕捉:Masked Diffusion Language Models(MDLMs)推理时按置信度逐步揭示序列结构,训练时却随机掩码,导致训练-推理不匹配(training-inference divide),引发“Answer Backslide”——中间正确答案被错误“精炼”成最终错误。
• 创新方案:将去噪过程视为多步决策,提出Masked Diffusion Policy Optimization(MDPO),利用强化学习和中间奖励,按照推理的逐步揭示策略显式训练模型,实现训练与推理一致。
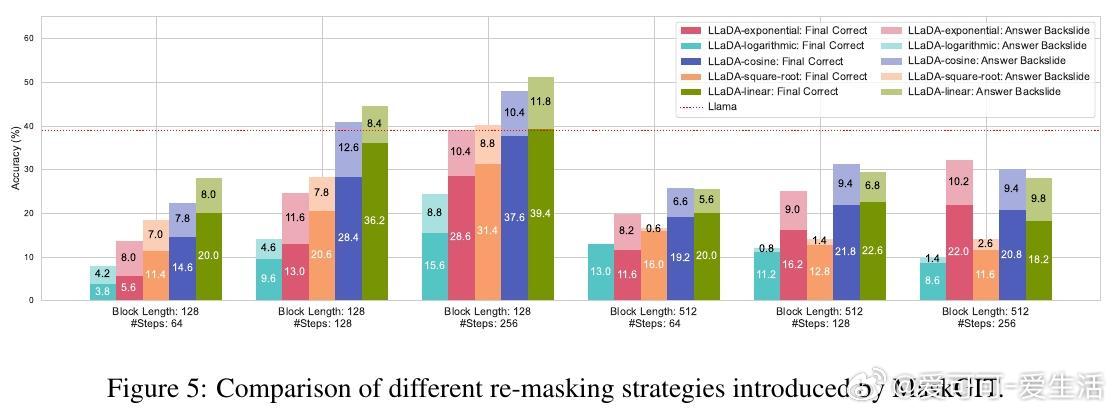
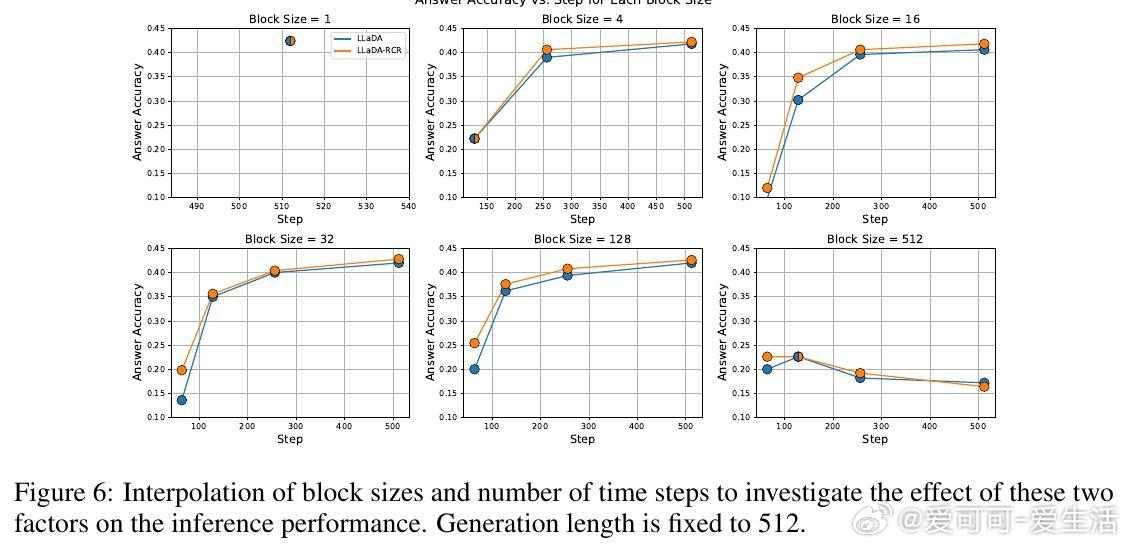
• 置信度动态重掩码(Running Confidence Remasking, RCR):跟踪每个位置预测的最高置信度,动态决定是否重掩码,突破传统低置信度掩码冻结预测的限制,允许模型灵活修正早期预测错误,进一步提升生成质量。
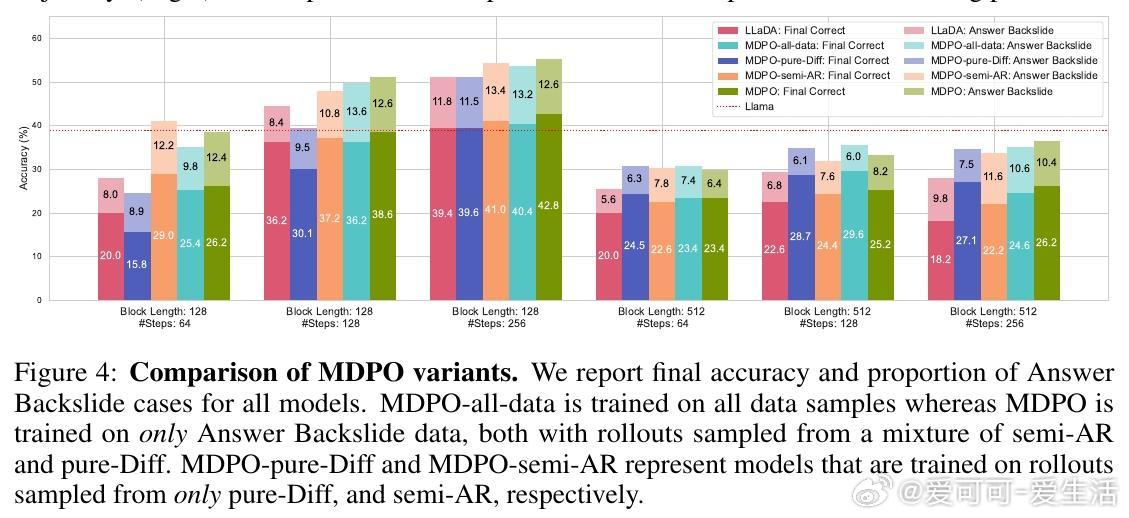
• 经验表现:MDPO以60倍更少梯度更新达到或超越现有最优,MATH500任务提升9.6%,Countdown任务提升54.2%;RCR作为无训练开销的插件,单独或结合MDPO均显著提升效果。
• 核心洞察:MDLMs生成完整文本的特性支持基于中间结果的奖励设计,强化学习在文本扩散模型中可有效优化生成路径,破解了迭代去噪路径学习的核心瓶颈。
• 应用前景:揭示训练-推理差异对MDLMs性能的深远影响,为未来利用LLM自评估等现代验证机制拓展强化学习方法奠定基础。
论文🔗 arxiv.org/abs/2508.13148
详情请见项目主页🔗cli212.github.io/MDPO/ 和代码库🔗github.com/autonomousvision/mdpo
自然语言处理扩散模型强化学习语言模型机器学习