[CV]《Separating Knowledge and Perception with Procedural Data》A Rodríguez-Muñoz, M Baradad, P Isola, A Torralba [MIT] (2025)
分离知识与感知:借助程序化数据实现视觉模型的全新范式
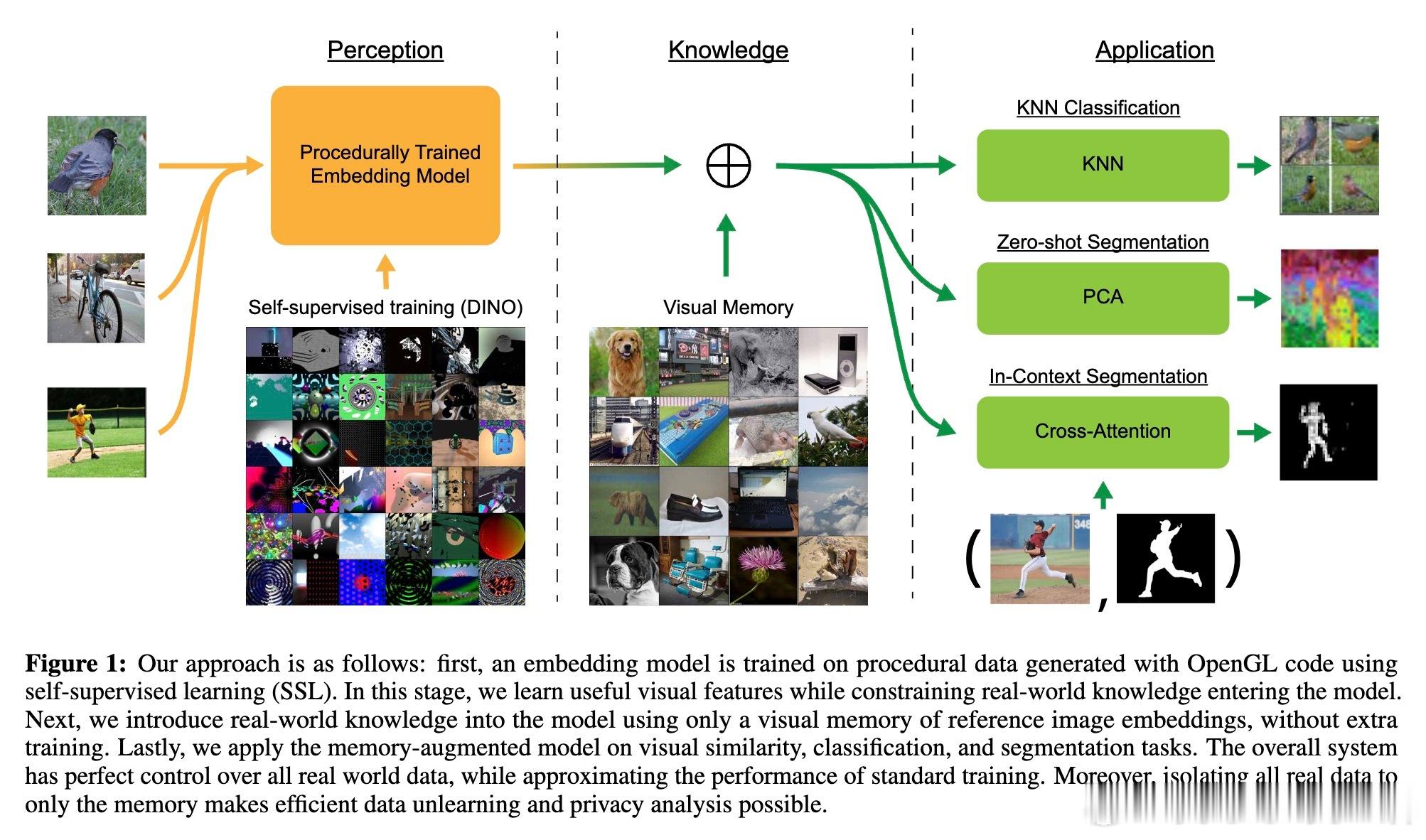
• 训练策略:仅用程序化数据(基于OpenGL代码生成)训练视觉Transformer嵌入模型,避免真实世界数据的偏见和隐私泄露,确保感知与知识的彻底分离。
• 视觉记忆机制:通过存储参考图像的嵌入向量数据库,利用k近邻检索实现分类、语义分割与视觉相似性任务,无需额外训练即可适配真实世界数据。
• 关键性能表现:
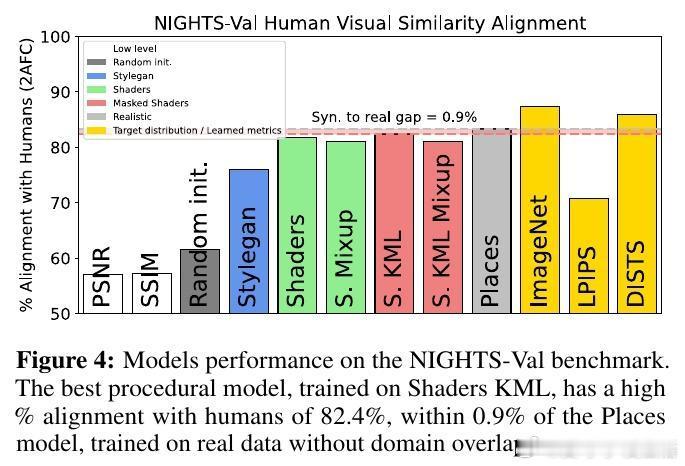
– 在NIGHTS视觉相似性任务上,程序化模型性能仅比真实数据训练的Places模型低0.9%。
– 在CUB200和Flowers102细粒度分类任务上,程序化模型分别领先Places模型8%和15%。
– 在ImageNet-1K分类中,程序化模型性能与Places模型相差不足10%。
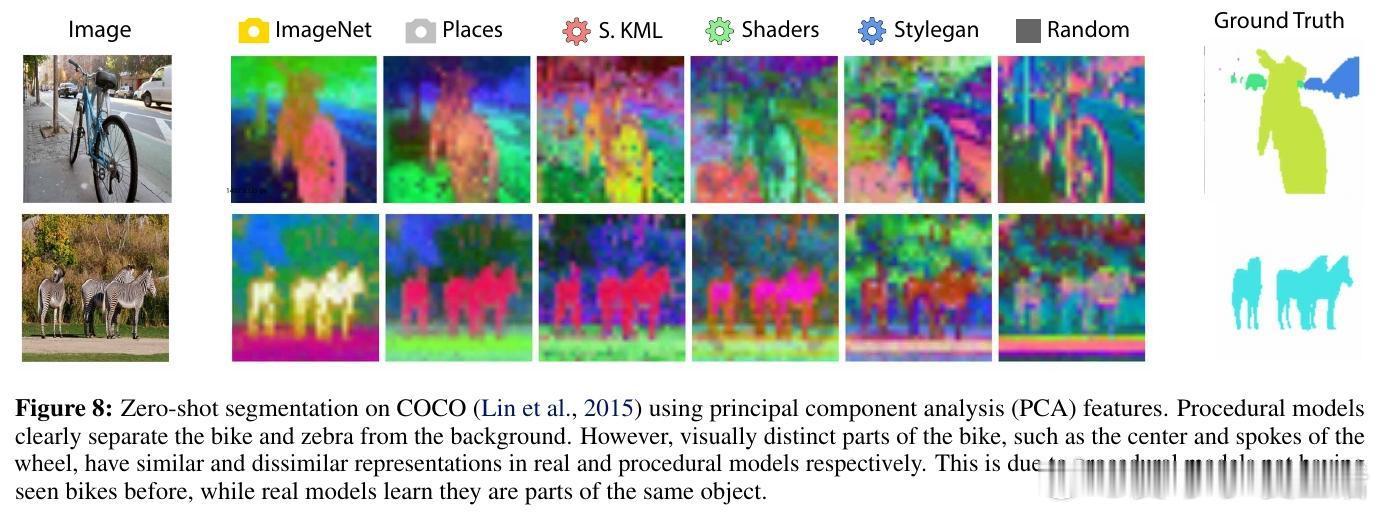
– 实现强大的零样本语义分割,COCO任务的R²指标与真实数据训练模型相差不超过10%。
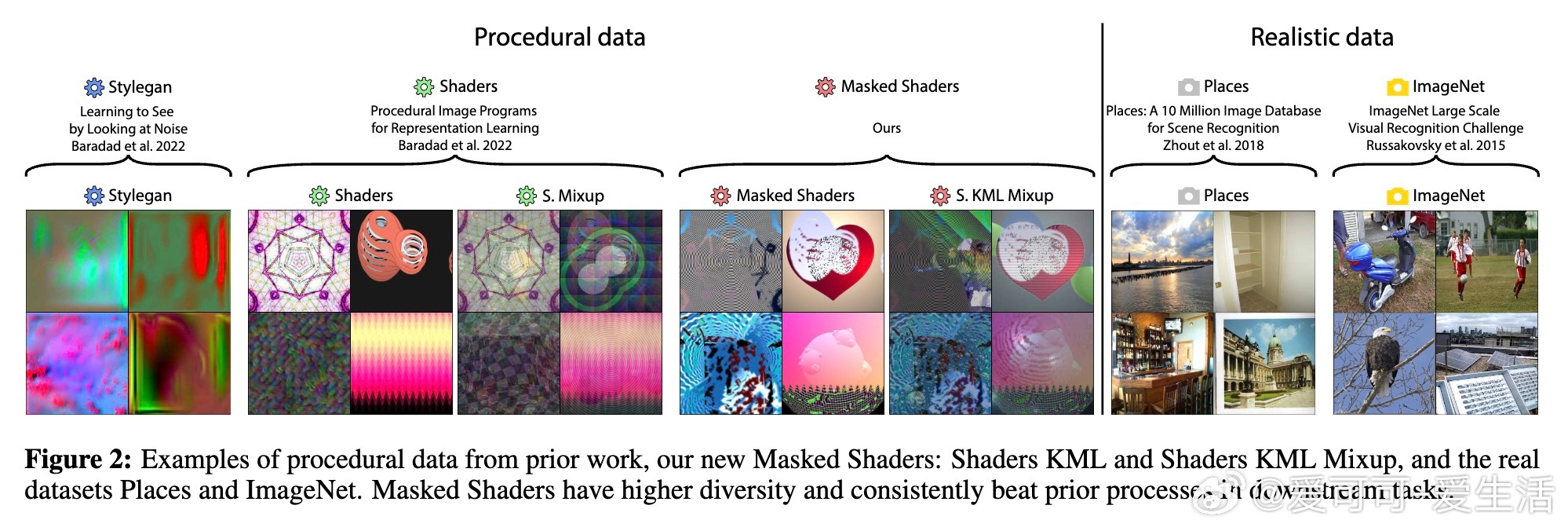
• 新颖数据生成方式:提出Shaders KML及Shaders KML Mixup两种程序化数据生成流程,显著提升嵌入质量和泛化能力,超越先前工作。
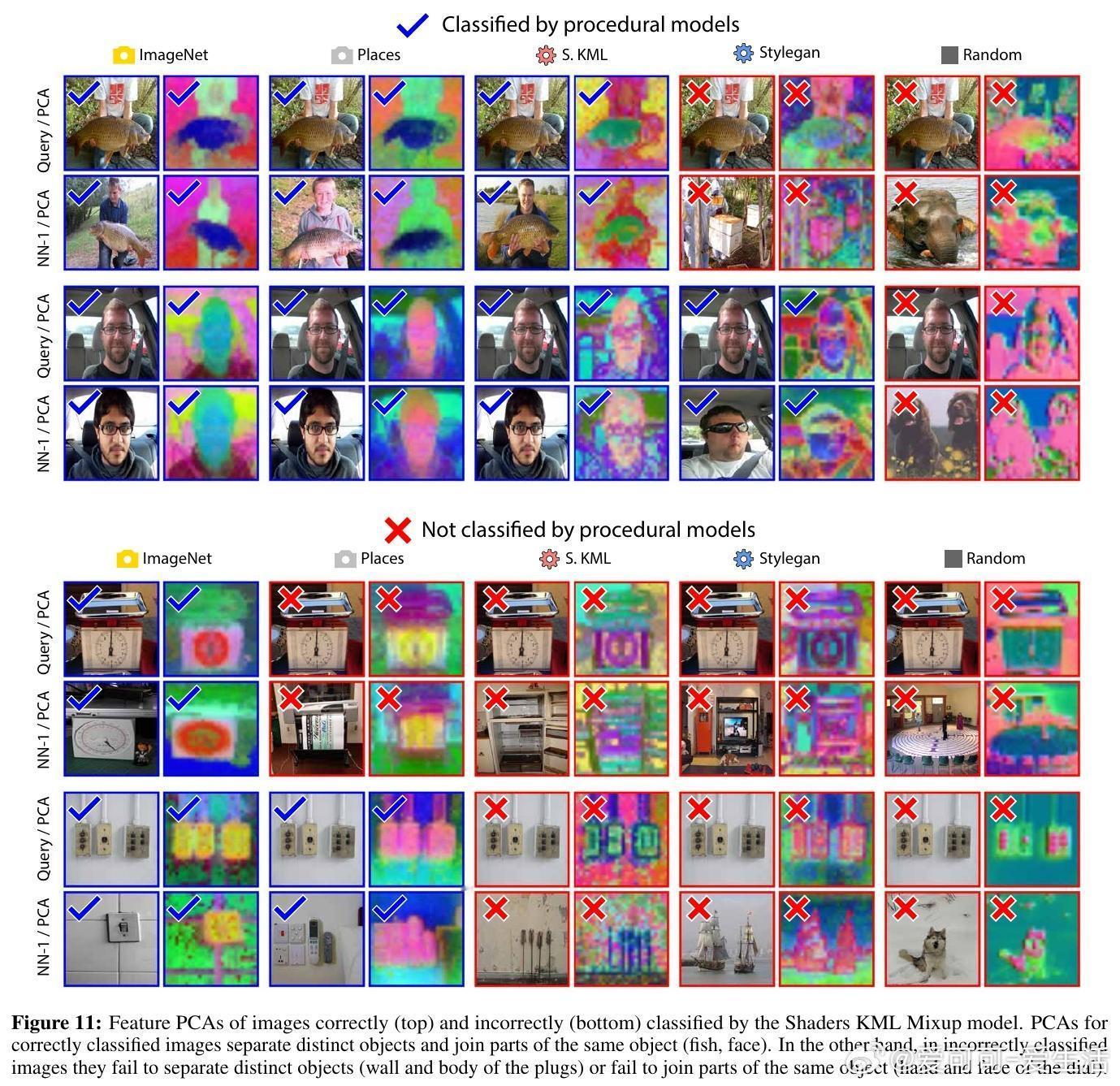
• 限制分析:程序化模型对同一对象不同部位的表征较为离散,导致视觉记忆中检索误差,解释性能差距来源。
• 隐私和可控性优势:真实数据仅存在于视觉记忆中,支持高效数据“去学习”和差分隐私保证,极大便利敏感数据处理和法规合规。
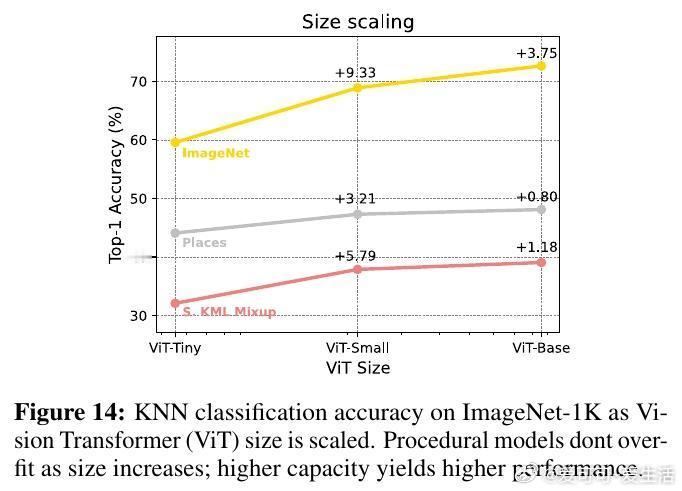
• 规模与效率:训练程序化模型成本远低于传统方法,且模型容量扩展提升性能无过拟合风险;视觉记忆检索通过高效库实现实时响应,存储成本远低于GPU硬件成本。
• 认知启示:当前视觉模型(真实或程序化)均未展现人类视觉的整体知觉(Gestalt)特性,提示未来研究方向。
本研究为构建透明、高效、隐私友好的视觉AI系统提供了坚实基础,尤其适合需严格数据监管的场景。程序化数据训练结合视觉记忆的新范式,重新定义了“知觉”与“知识”的边界。
🔗 arxiv.org/abs/2508.11697
计算机视觉程序化数据视觉记忆零样本学习隐私保护自监督学习