[LG]《EvolKV: Evolutionary KV Cache Compression for LLM Inference》B Yu, Y Chai [University of Chinese Academy of Sciences & ETH Zurich] (2025)
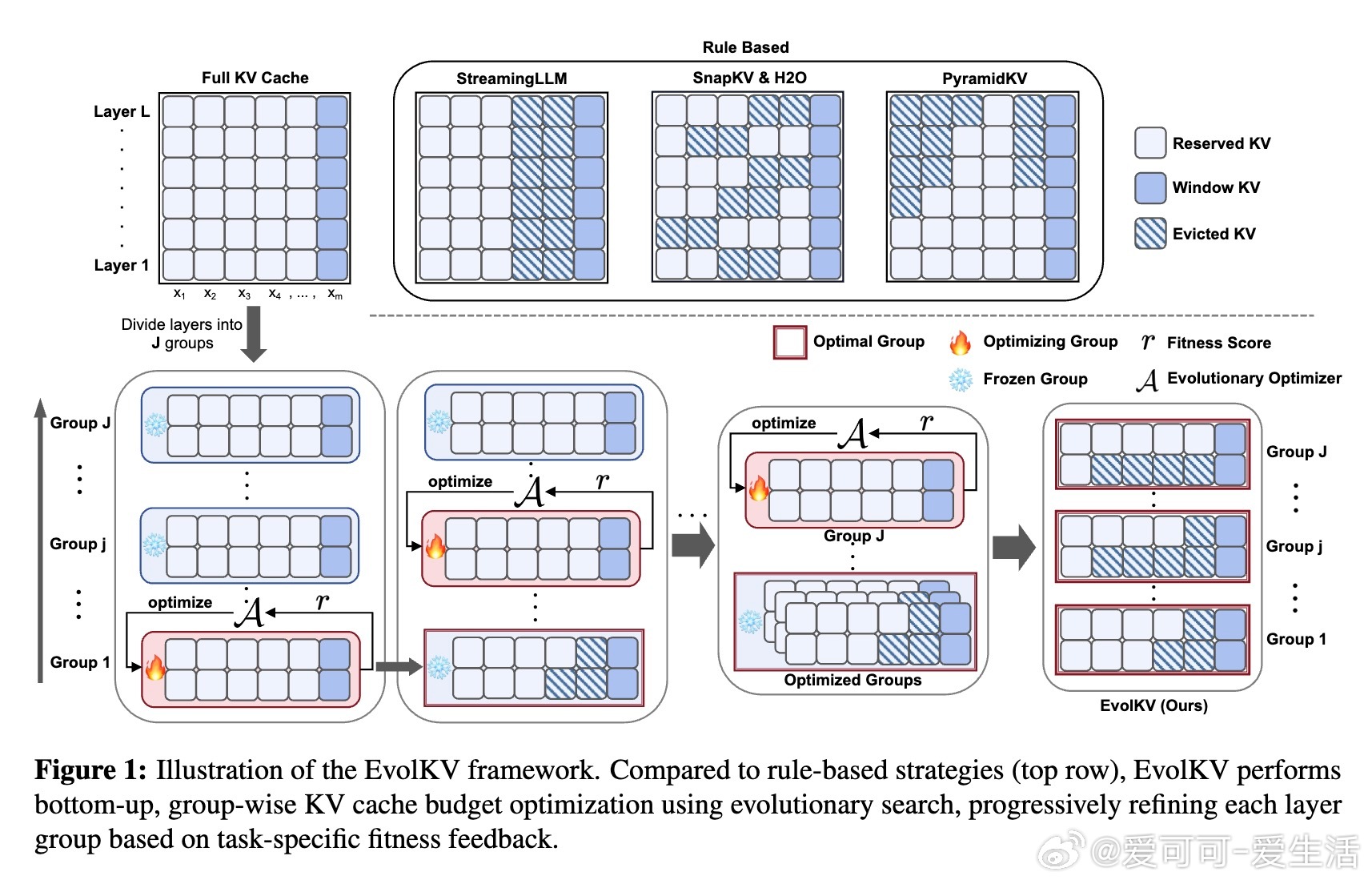
EvolKV:首个基于进化算法的LLM KV Cache层级压缩框架,打破传统启发式分配限制,实现任务驱动的动态缓存预算优化。
• 重新定义KV Cache分配为多目标优化问题,兼顾内存效率与下游任务性能,采用CMA-ES进化策略,基于任务反馈迭代调整各层缓存预算。
• 采用层级分组机制(最佳组大小为8层)缩减搜索空间,提高算法稳定性与优化效率,支持多种性能指标(准确率、F1等),无需模型微调或架构改动。
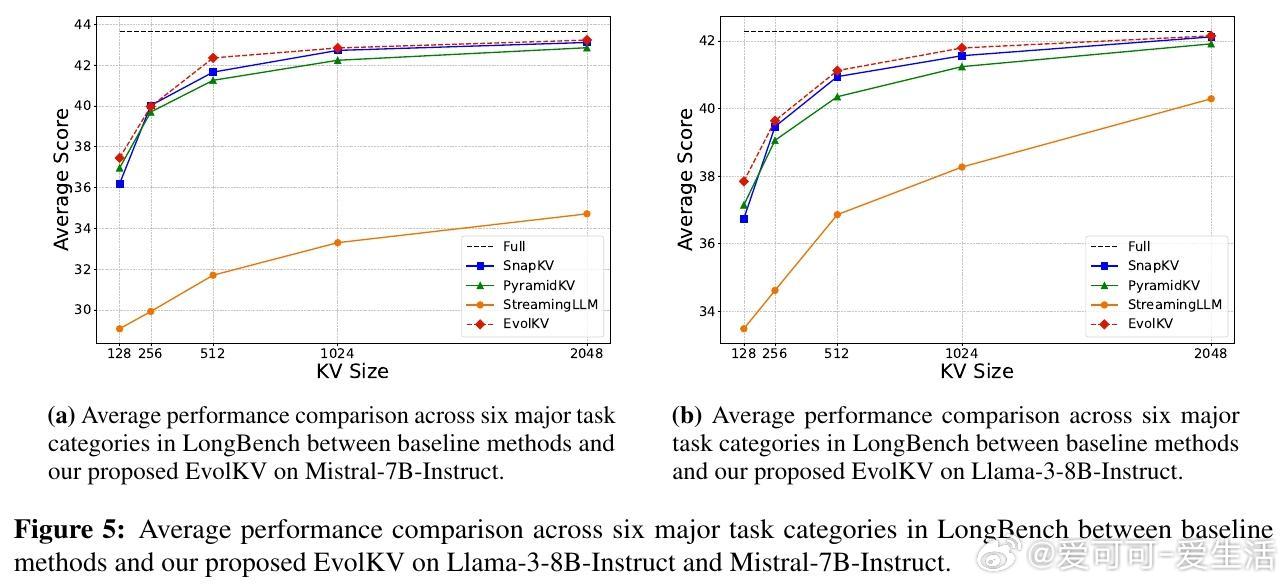
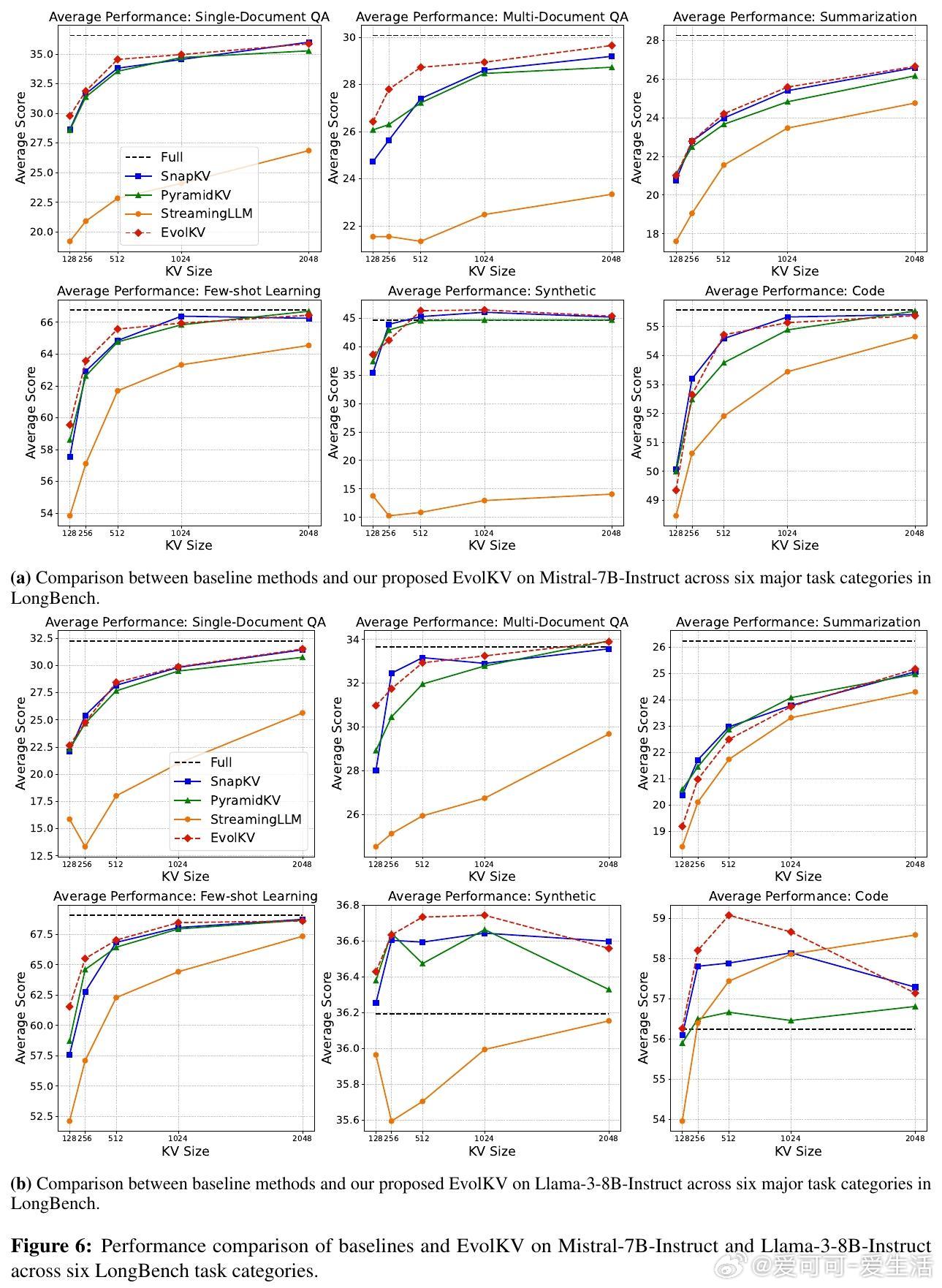
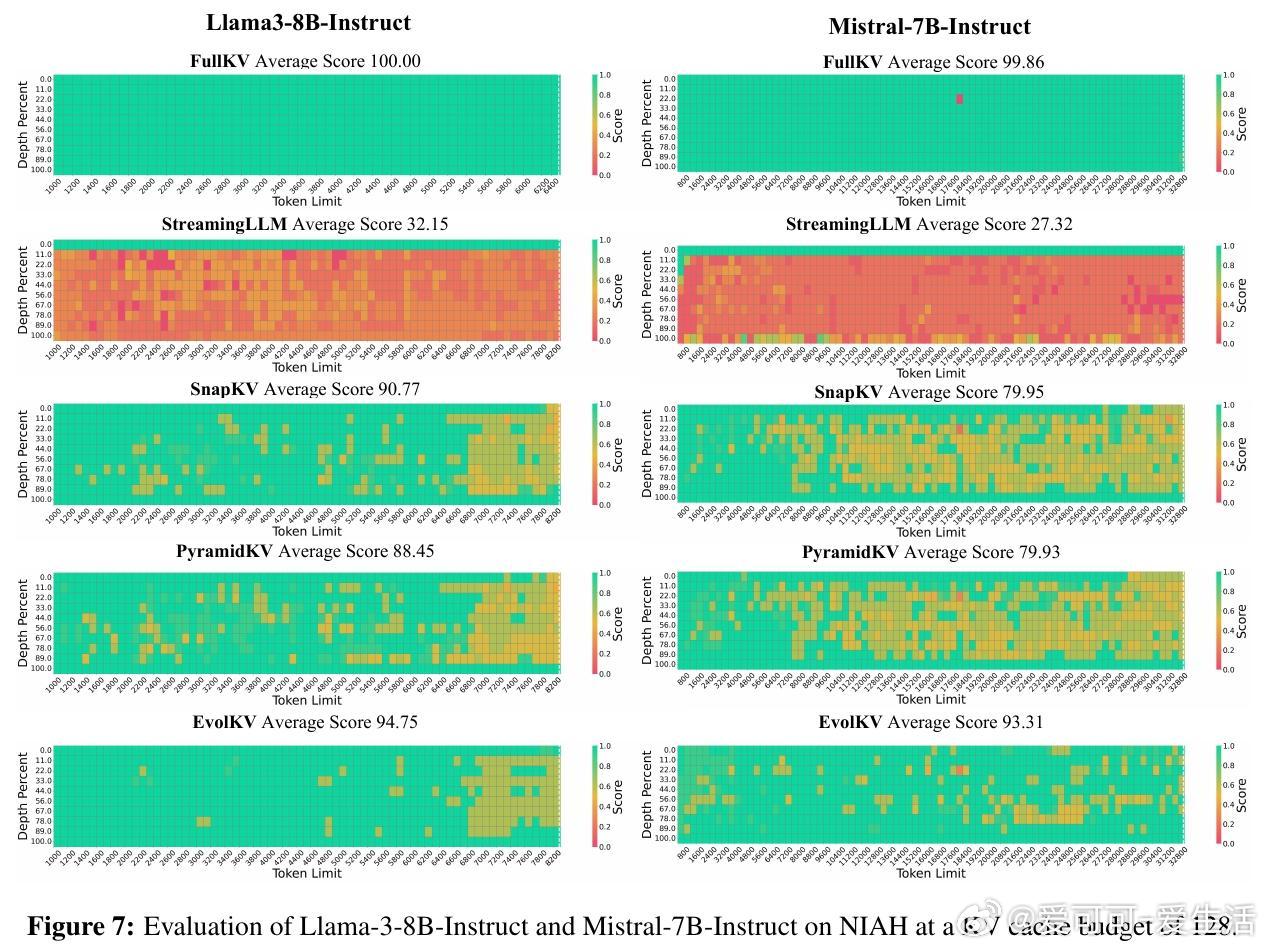
• 在Mistral-7B-Instruct和Llama-3-8B-Instruct两个模型及11个任务上验证,覆盖长上下文检索、推理及数学题,显著领先PyramidKV、SnapKV、StreamingLLM等基线,最高提升7个百分点准确率。
• 低至1.5%缓存预算下,EvolKV在代码补全任务上超越全缓存性能,揭示非均匀、非金字塔式缓存分布对性能贡献的重要性。
• 优化结果具备强泛化能力,训练集外数据同样表现优异,支持预算从低到高平滑扩展,适配多模型系列及复杂长上下文任务。
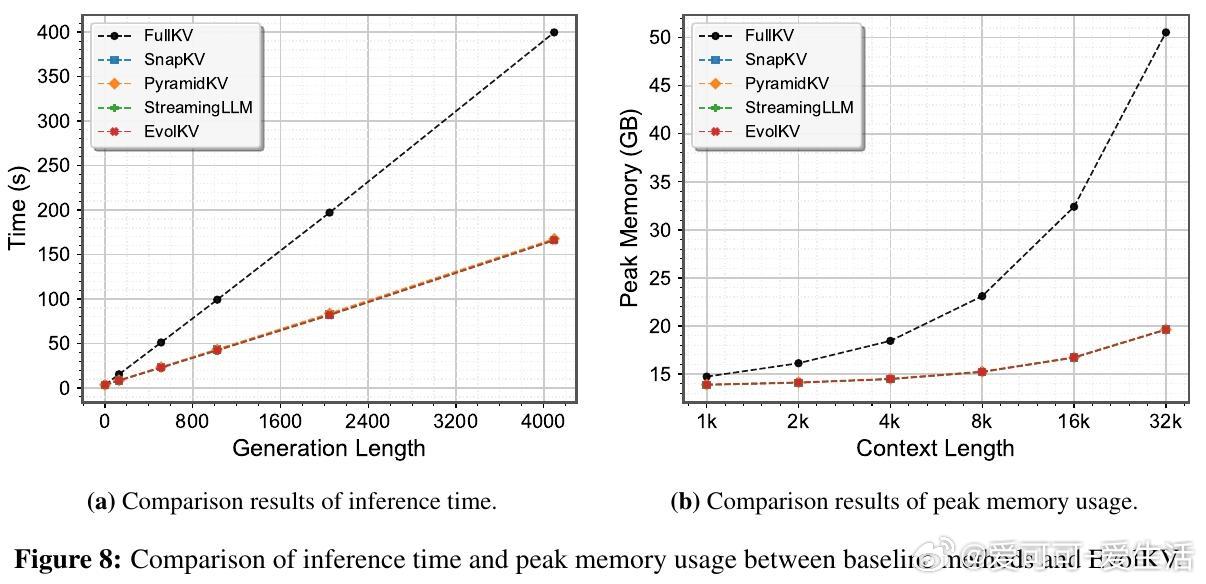
• 推理时间和峰值内存消耗与现有压缩方法相当,远低于全缓存方案,具备极佳的实用部署价值。
心得:
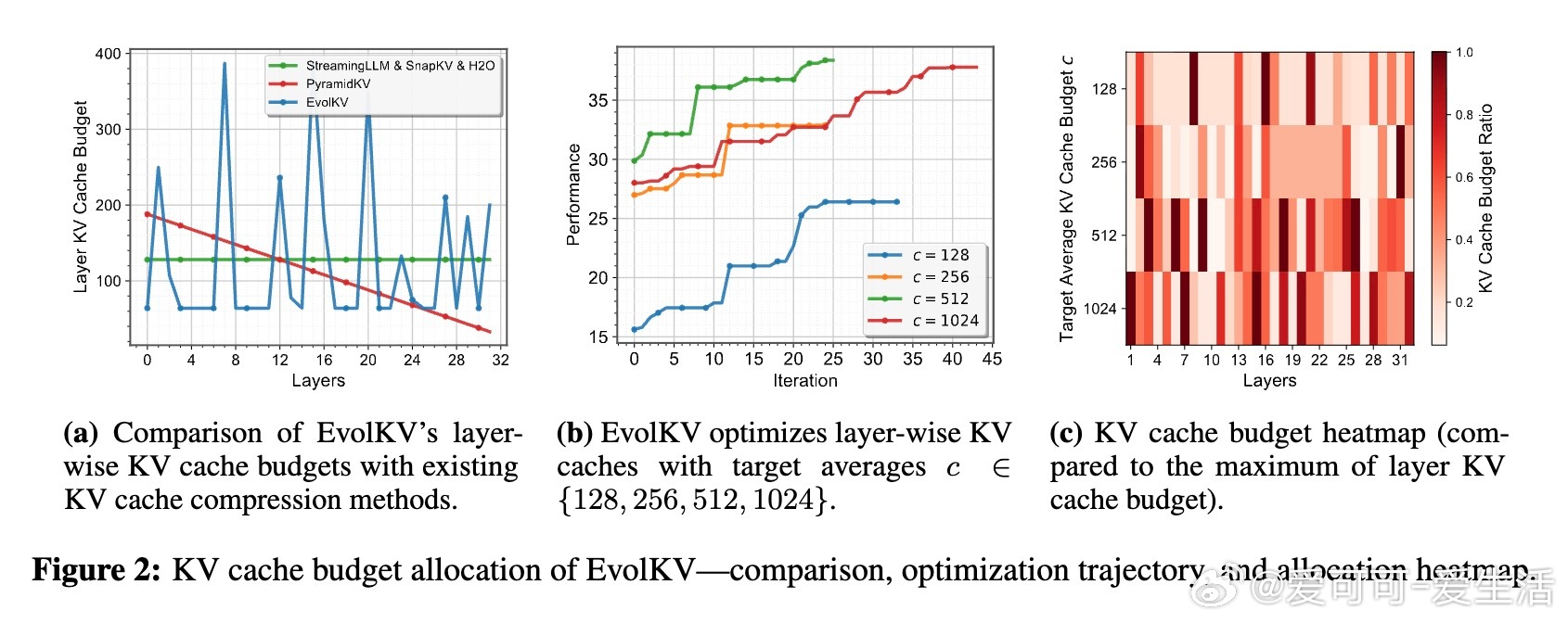
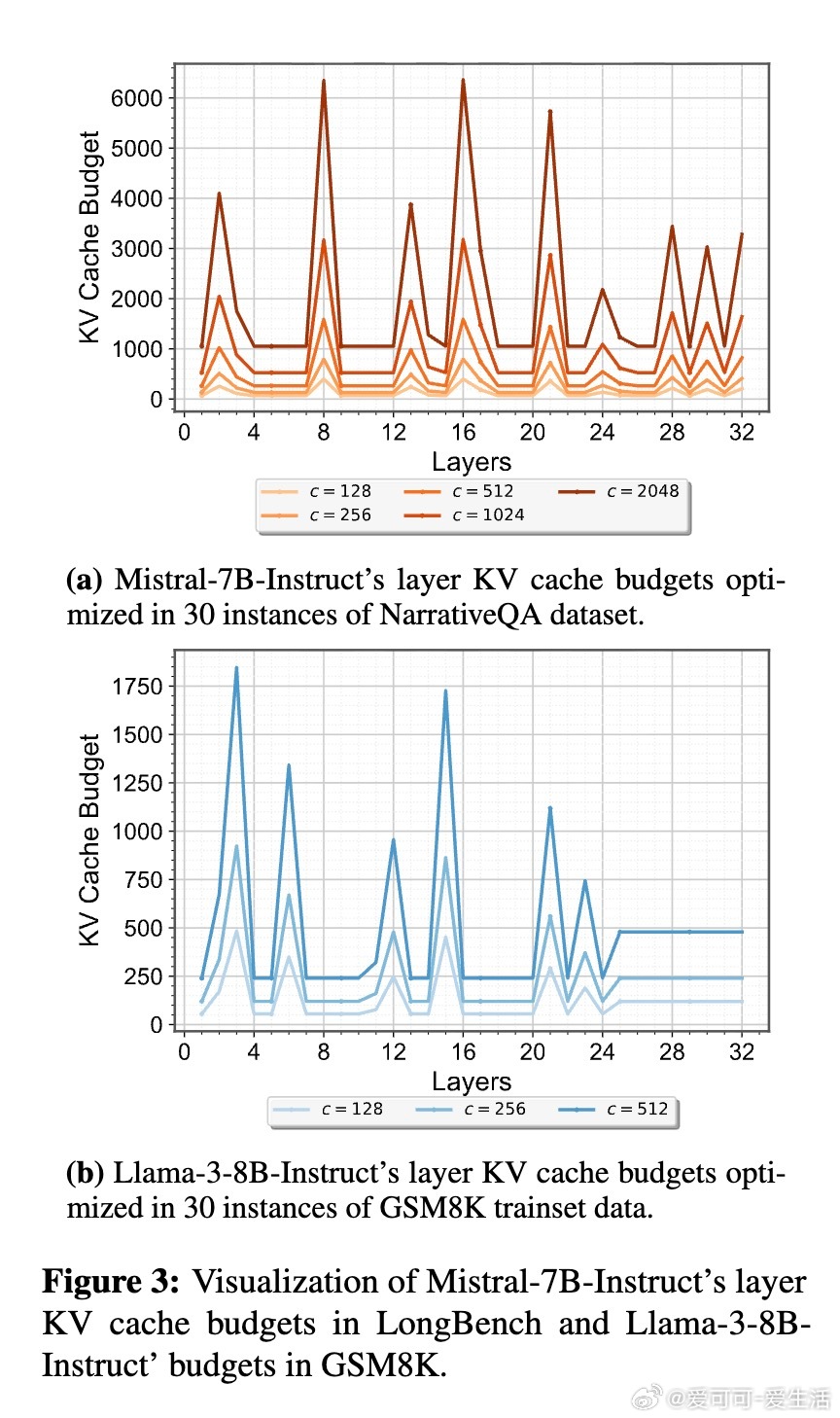
1. KV Cache需求在不同层存在显著异质性,固定或金字塔式分配忽视了层间功能差异,任务驱动的动态分配更贴合模型实际信息处理机制。
2. 通过进化算法结合下游任务反馈,可有效探索复杂的非线性预算分配空间,避免人工规则的局限,提升长上下文推理能力。
3. 低预算下的非均匀缓存策略不仅节省资源,还可能激发模型更优表现,突破传统认为“更多缓存必然更好”的认知。
了解更多🔗arxiv.org/abs/2509.08315
人工智能大模型缓存压缩进化算法长上下文推理模型优化