翁荔陈丹琦公司发布首个产品大模型微调像写代码一样简单
Thinking Machines Lab发布首个产品:Thinker,让模型微调变得像改Python代码一样简单。
也算是终于摘掉了"0产品0收入估值840亿"的帽子。【图1】
联合创始人翁荔表示:GPU价格昂贵,并且设置基础设施非常复杂,使研究人员和从业者使用前沿模型进行具有挑战性,Tinker是提供高质量的研究工具、提高研究生产力的第一步。【图2】
大神卡帕西直接评价这个产品"很酷":
相比那种"上传数据,我们帮你训练"的传统模式,Tinker让研究者保留了90%的控制权,主要涉及数据、损失函数和算法本身,而把那些通常不想碰的硬骨头(基础设施、LLM本身的前向/后向传播、分布式训练)都包办了。【图3】
与此同时,还有消息称Thinking Machines Lab正在尝试"重新发明一个OpenAI",重建OpenAI在规模变大、变的官僚主义之前的那个版本。
创始人Murati 表示,Thinking Machines Lab将会是一家公开分享研究成果,给研究人员更多自由的公司。【图4】
什么是Tinker?
简单来说,Tinker是一个用于微调语言模型的灵活API。
让研究人员能够在实验中控制算法和数据,同时无需担心基础设施的管理。
这符合Thinking Machines Lab的使命:让更多人能够研究前沿模型,并根据自身需求进行定制。
Thinker首批主要提供Qwen3和Llama3系列模型的支持,从小模型切换到大模型,只需在Python代码中修改一个字符串就行。【图5】
Thinker的API提供了forward_backward和sample这样的底层训练步骤,同时仍自动处理调度、扩展和错误恢复。【图6】
还使用LoRA让多个训练任务共享相同的 GPU,降低成本并让更多实验并行运行。【图7】
除了云托管服务之外,他们还开源了一个Tinker Cookbook库,里面有各种现成的后训练方法实现。【图8】
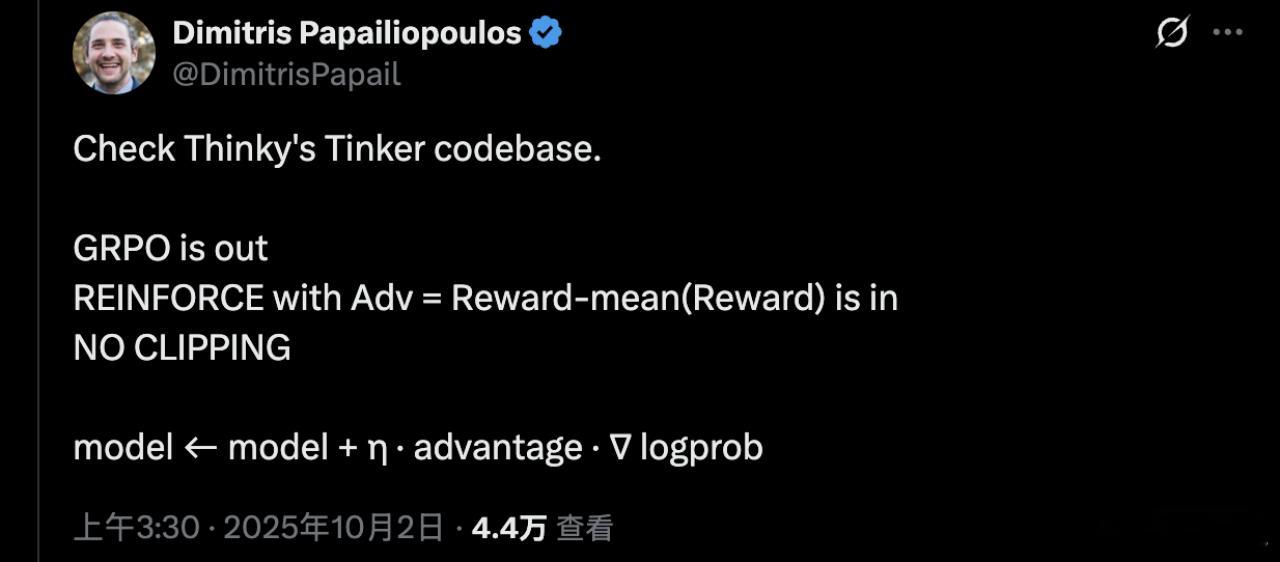
有微软研究员检查了Tinker的代码库,发现了更多细节:
没有用DeepSeek提出的GRPO方法,而是使用更经典的REINFORCE算法,配合优势函数,没有梯度裁剪。
简单概括其梯度更新策略为:
新参数 = 原参数 + 学习率 × 优势值 × 对数概率的梯度【图9】
Tinker受到了业界的密切关注。AI基础设施公司Anyscale的CEO Robert Nishihara等beta测试者表示,尽管市面上有其他微调工具,但Tinker在"抽象化和可调性之间取得了卓越的平衡"
来自普林斯顿、斯坦福、伯克利和Redwood Research的研究团队则已经用Tinker搞出不少成果。【图10】
大神卡帕西还在评论中特别指出,社区还在探索微调相比直接prompt大模型的优势在哪。
从早期迹象看,微调不只是给大模型的输出换个风格,更多是缩小任务范围。特别是当你有训练样本数量很大时,与其给大模型构建复杂的few-shot prompt,不如直接微调一个小模型专门处理特定任务。
越来越多的AI应用变成了更大规模的流水线,其中许多大模型在流程中协作,其中一些环节适合用提示,但更多环节用微调可能会更好。
Tinker让微调变得简单,可以在任意环节中实验出最佳方案。【图11】