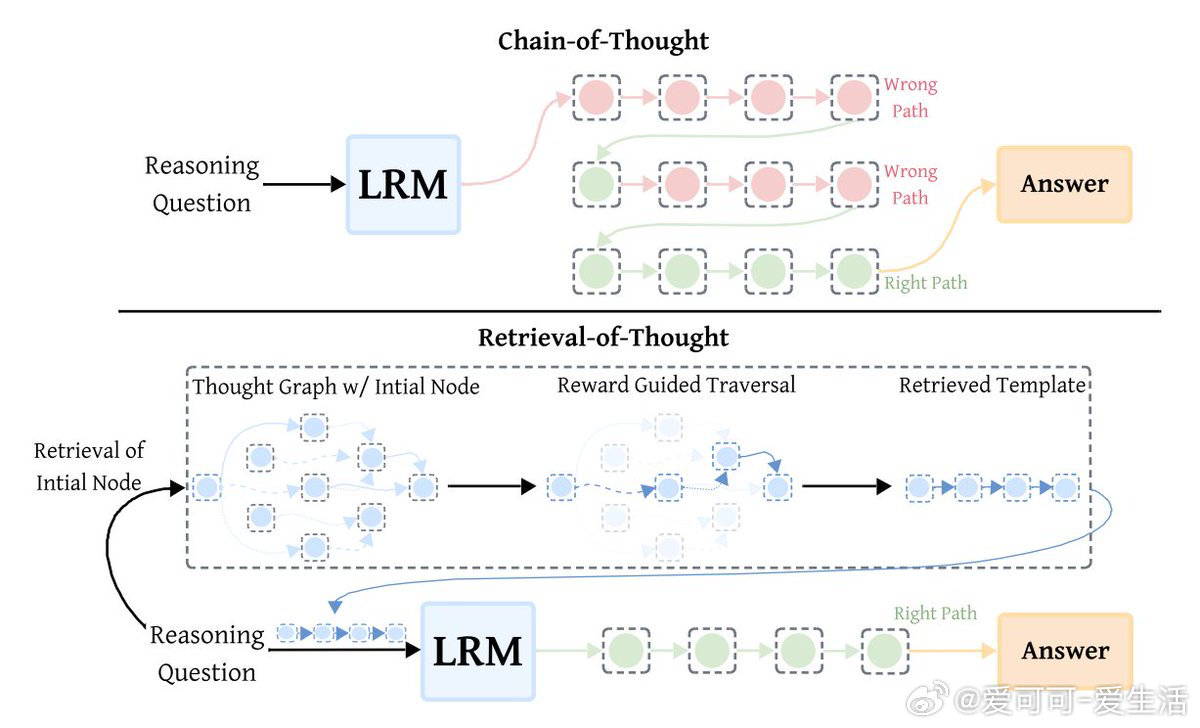
Retrieval-of-Thought(RoT)是一种创新的推理加速技术,通过复用之前的推理步骤作为模板,极大提升模型效率。其核心是构建一个“思维图谱”,将推理步骤以节点形式存储,既体现步骤顺序,也反映语义关联。
RoT带来显著优势:
- 输出token减少40%
- 推理速度提升82%
- 成本降低59%
同时保持推理准确性无损。
工作原理分四步:
1️⃣ 构建思维图谱
收集3,340个推理模板,将每一步作为图中节点,附加主题标签(如代数、几何)。通过顺序边连接步骤,语义边连接类似步骤,形成丰富的推理片段记忆库。
2️⃣ 确定起点
针对新问题,筛选相关标签节点(如几何问题只选“几何”节点),基于语义相似度和起始有效性评分,选出最优起点。
3️⃣ 奖励引导扩展
沿图谱按语义匹配和推理流畅度评分,逐步扩展推理模板,直到相关性不足、长度超限或无后续步骤为止。
4️⃣ 模板融入推理
将生成的模板嵌入模型提示中,通过特殊的标签引导模型跟随复用的推理路径,无需额外微调。
为何RoT表现这么好?
- 动态构建上下文相关的推理模板,灵活适应不同问题
- 奖励引导遍历算法确保高质量组合推理步骤
- 轻量思维图谱+嵌入模型仅占1.7GB,便于部署
- 尤其提升小模型表现,因为它们更擅长跟随指令
这意味着,RoT不仅优化了推理速度和成本,还为更智能、更经济的AI推理开辟了新路径。
详细论文👉 arxiv.org/abs/2509.21743
原推文链接👉 x.com/TheTuringPost/status/1974228574598205736
---
思考延展:
RoT的思维图谱方法,类似人类通过积累经验构建知识网络,未来或成为AI推理范式的关键升级。动态模板搭建与奖励引导遍历,兼顾灵活性和效率,值得在多模态推理、复杂决策系统中深入探索。小模型获益更大,也为普及AI推理带来可能,降低大规模模型依赖和计算门槛。