《Understanding the 4 Main Approaches to LLM Evaluation (From Scratch)》
如何科学评估大型语言模型(LLM)?这看似简单的问题,背后其实包含复杂且多元的方法。本文总结了4种主流LLM评测方式,结合实操代码示例,助你理清思路,深入理解各方法优劣。
---
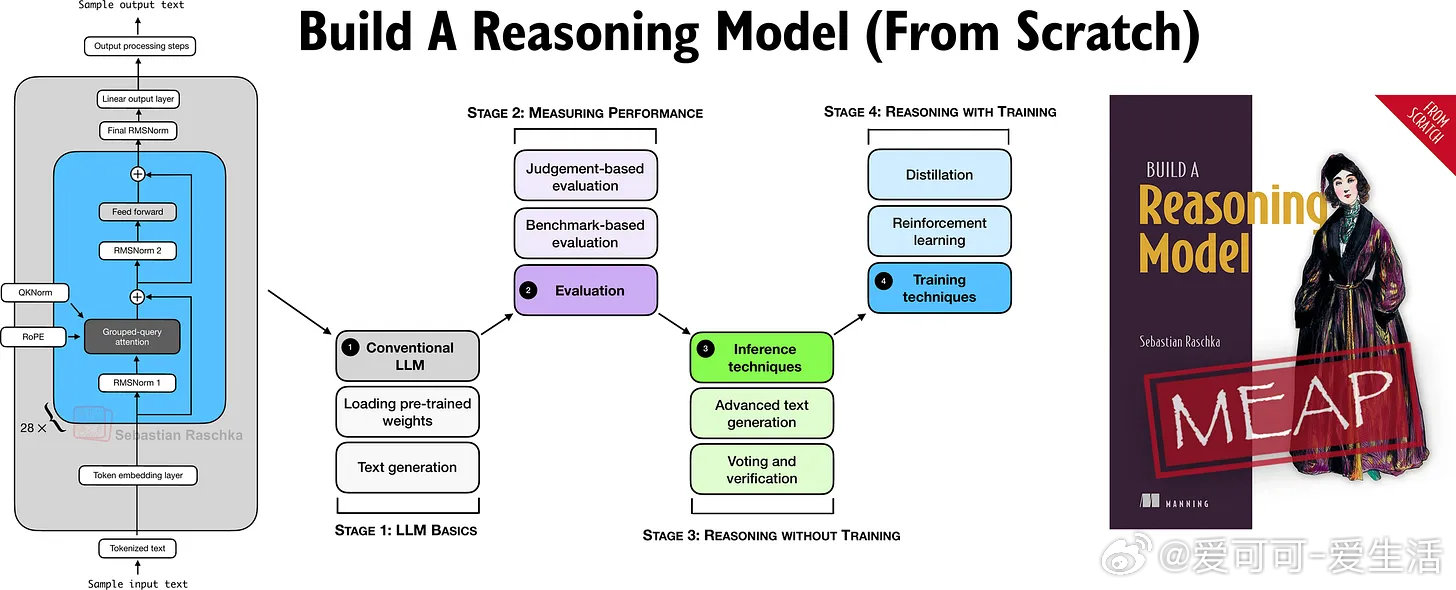
4大主流LLM评测方法
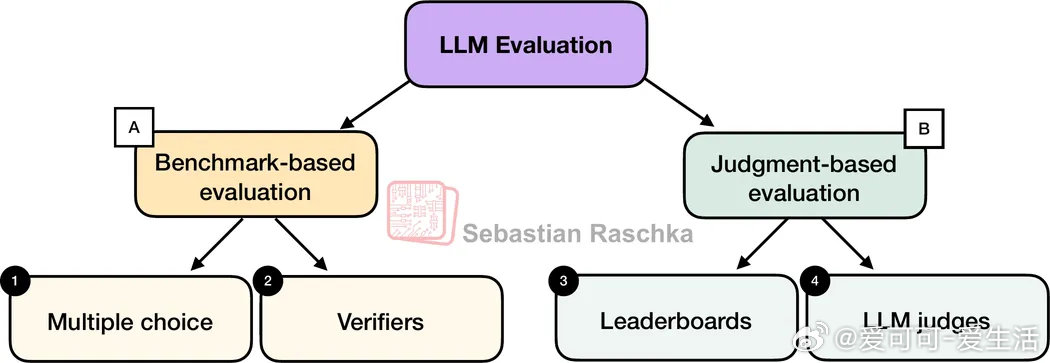
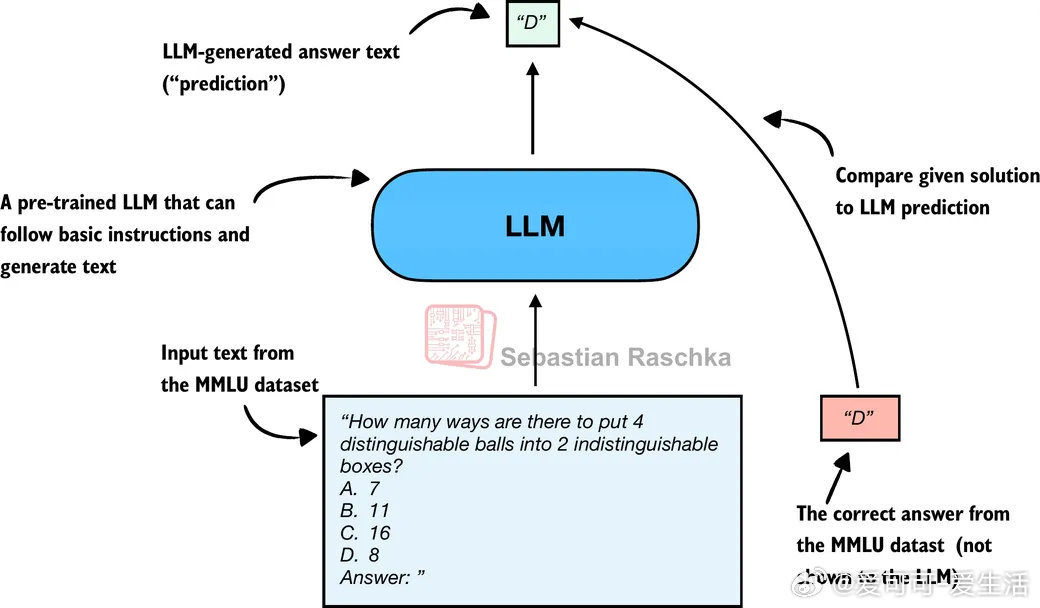
1. 选择题基准测试(Multiple Choice)
以MMLU数据集为例,通过判断模型选择的答案字母是否正确,量化知识回忆能力。优点是快速、标准化,缺点是无法衡量模型的自由表达和推理能力,只能检测知识遗忘或记忆情况。
2. 验证器(Verifiers)
允许模型生成自由文本答案,再通过外部工具(如数学计算器、代码解释器)验证结果准确性。适合数学、代码等可确定性领域,能检测推理过程,但实现复杂且受限领域。
3. 排行榜(Leaderboards)
通过用户或另一个LLM的偏好投票,基于答案风格和实用性排序模型。常用Elo评分系统或Bradley-Terry模型对投票结果建模。优点是更符合真实使用场景,缺点是费时、受用户偏好和投票策略影响较大。
4. LLM裁判(LLM-as-a-Judge)
用强大LLM结合预设评分规则,对模型回答进行打分。可扩展、自动化,能处理自由文本答案,但高度依赖评分模型和评分标准,且结果可能存在偏差。
---
评测方法对比总结
- 多选题 优点:快速、标准化、易量化 缺点:只能测知识回忆,缺乏实际应用表现
- 验证器 优点:标准客观、适合自由回答、能评估推理步骤 缺点:仅限可验证领域,工具依赖性强
- 排行榜 优点:贴近用户体验、涵盖风格和帮助度 缺点:人力成本高、非正确性评价、受偏见影响
- LLM裁判 优点:可扩展、自动化、多任务适用 缺点:依赖裁判模型和规则,结果不够稳定
---
评测实践建议
- 结合多种方法,根据应用场景选用合适策略。例如法律领域可以先用MMLU做知识检测,再用LLM裁判评估回答质量,最后用排行榜收集用户偏好反馈。
- 关注评测数据的独立性,避免模型因训练时见过测试集而产生虚假高分。
- 理解每种方法的局限性,避免单一指标误导决策。
- 探索推理能力的多维度评价,如过程奖励模型(Process Reward Models)可评估推理中间步骤质量,助力模型训练。
---
额外思考
模型评测不仅是技术问题,更是产品和业务需求的反映。理想的评测体系应覆盖知识、推理、表达、用户体验等多个维度。LLM发展迅速,评测方法也在不断演进,掌握核心原理和思路,才能更好地适应未来挑战。
---
完整内容和代码示例详见:
magazine.sebastianraschka.com/p/llm-evaluation-4-approaches