[LG]《Expected Attention: KV Cache Compression by Estimating Attention from Future Queries Distribution》A Devoto, M Jeblick, S Jégou [NVIDIA & Sapienza University of Rome] (2025)
《Expected Attention:基于未来查询分布估计实现KV缓存压缩》新突破!
🔑背景痛点:
大型语言模型(LLM)推理时,Key-Value(KV)缓存占用巨大内存,限制了长上下文处理能力。现有基于注意力得分的压缩方法难以获得未来令牌的注意力分数,且现代实现如Flash Attention不存储完整注意力矩阵,导致无法访问过去的注意力分数。
💡创新点:
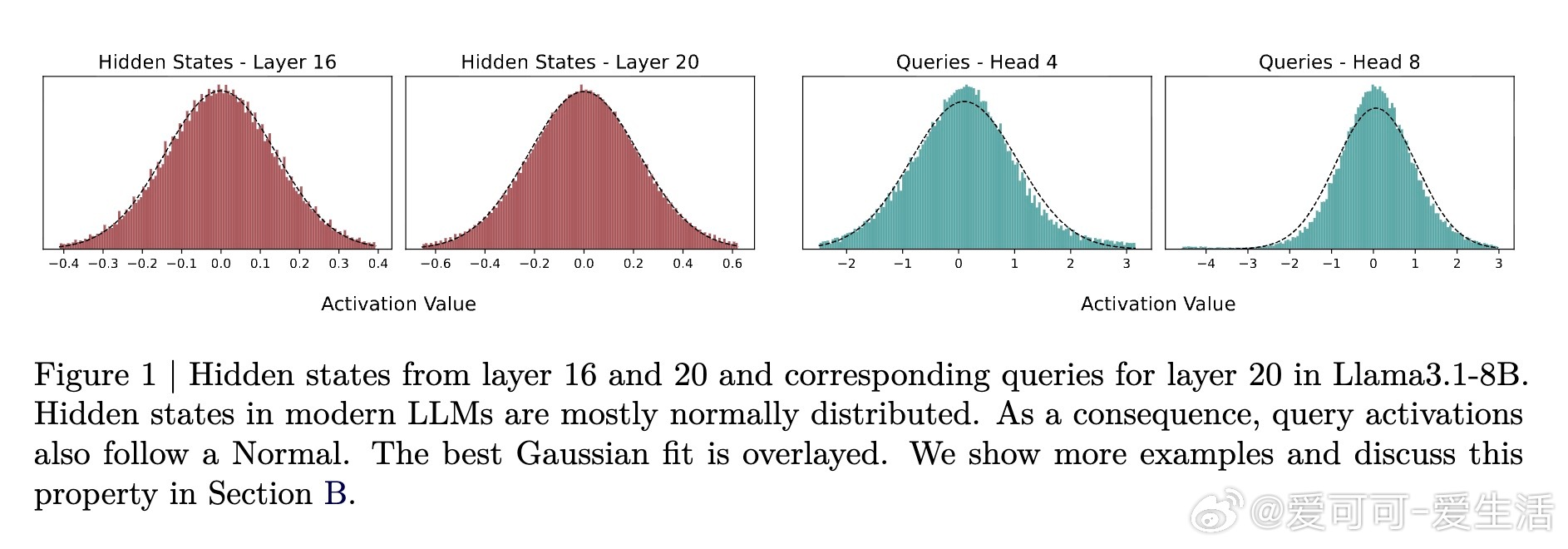
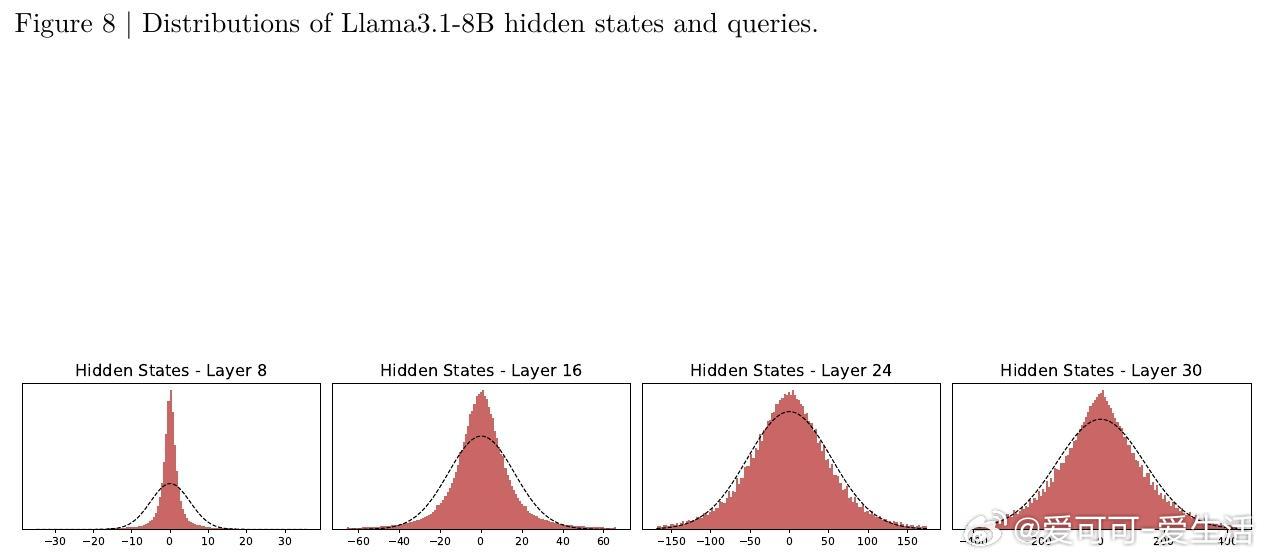
论文提出了“Expected Attention”方法,一种无需训练的KV缓存压缩技术,通过估计未来查询的注意力分布,计算每个KV对的重要性分数。该方法基于LLM激活的高斯分布特性,闭式计算预期注意力得分,从而有原则地排名并剪枝KV对,实现高效压缩而不损失模型性能。
⚙️方法亮点:
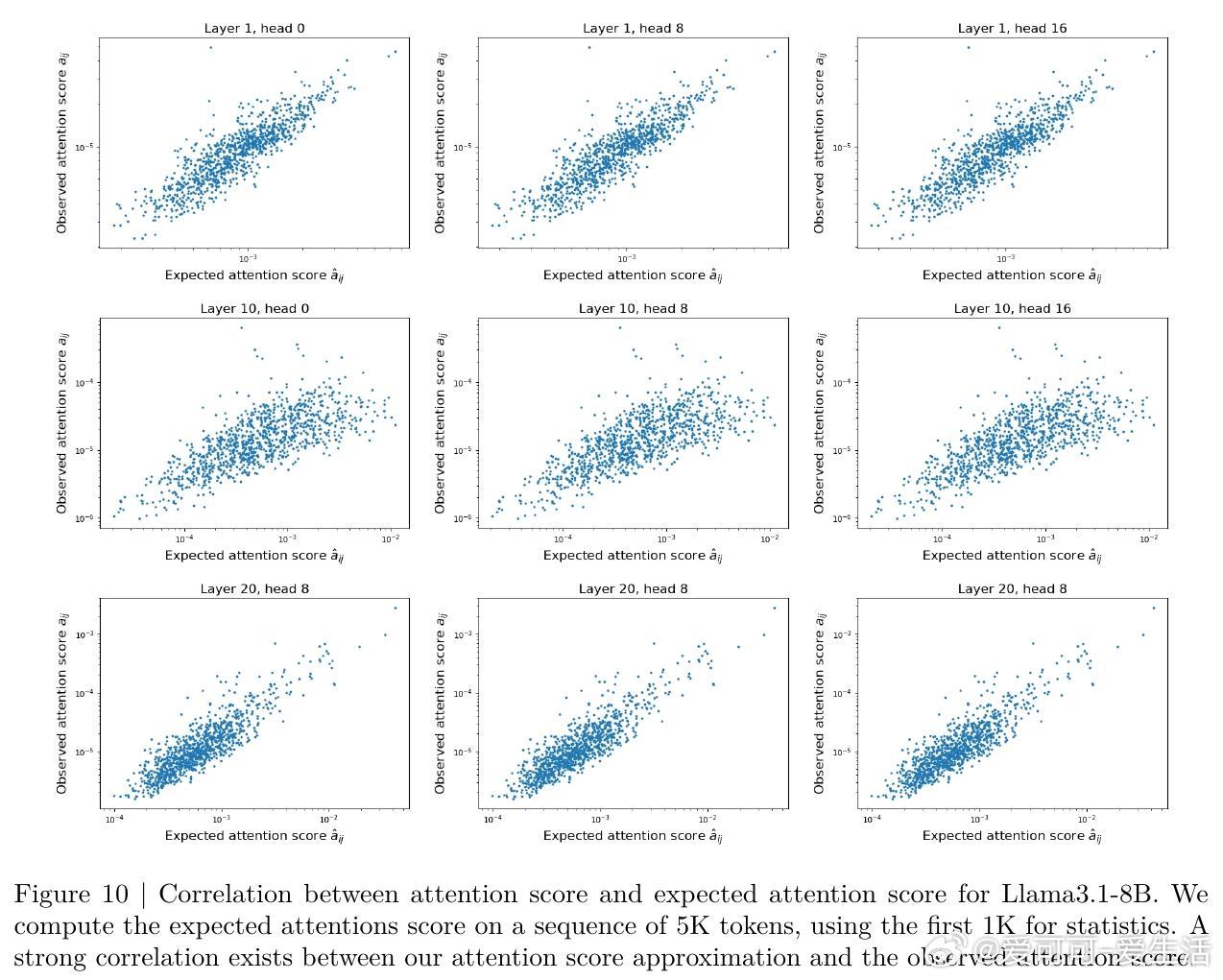
- 利用未来查询的分布均值和协方差估计未生成查询的注意力分值;
- 结合注意力权重和变换后的值向量大小,量化KV对对输出的贡献;
- 适用预填充和解码阶段,兼顾推理全流程;
- 可针对不同注意力头自适应压缩,保留关键信息。
📊实验成果:
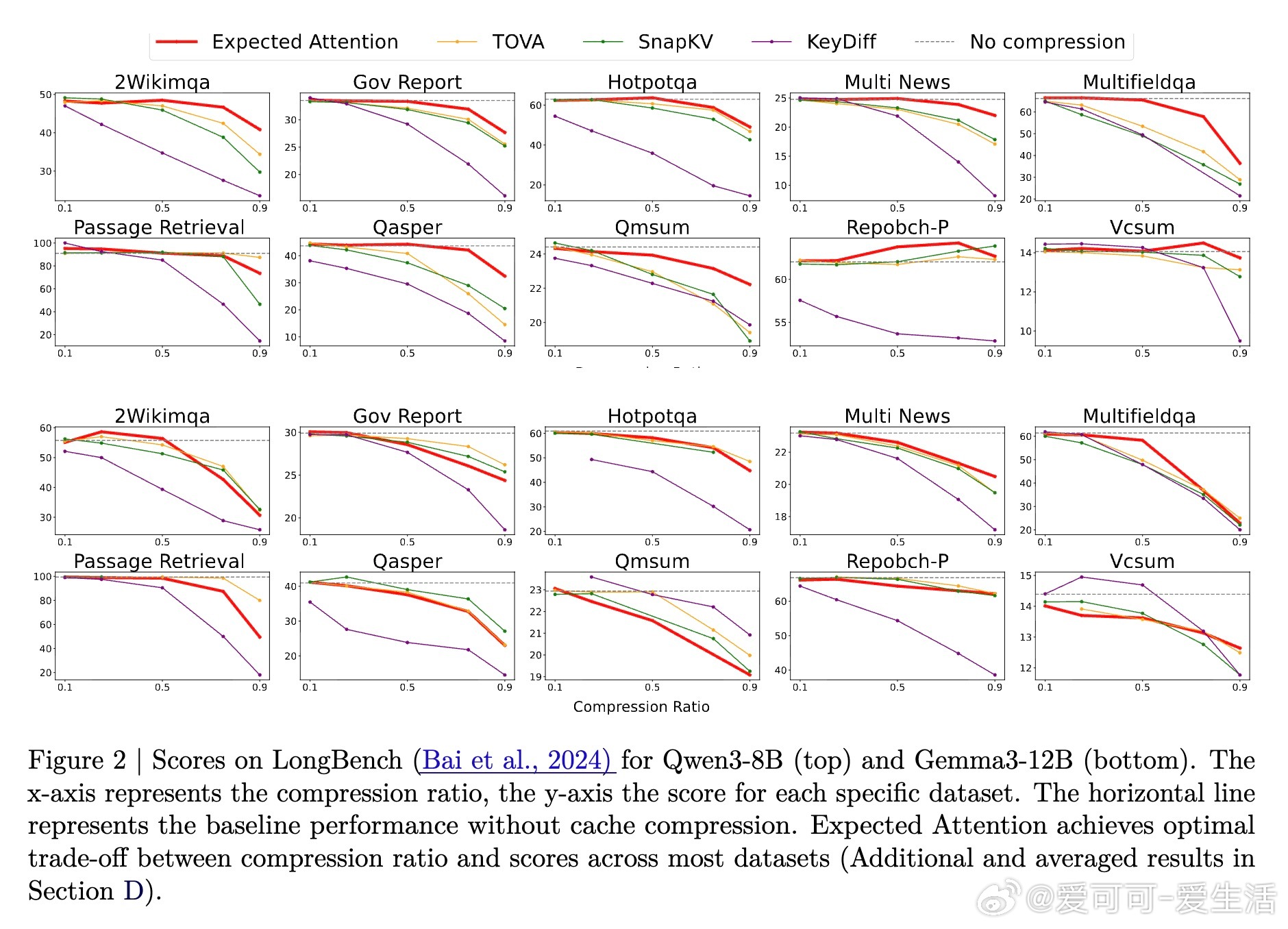
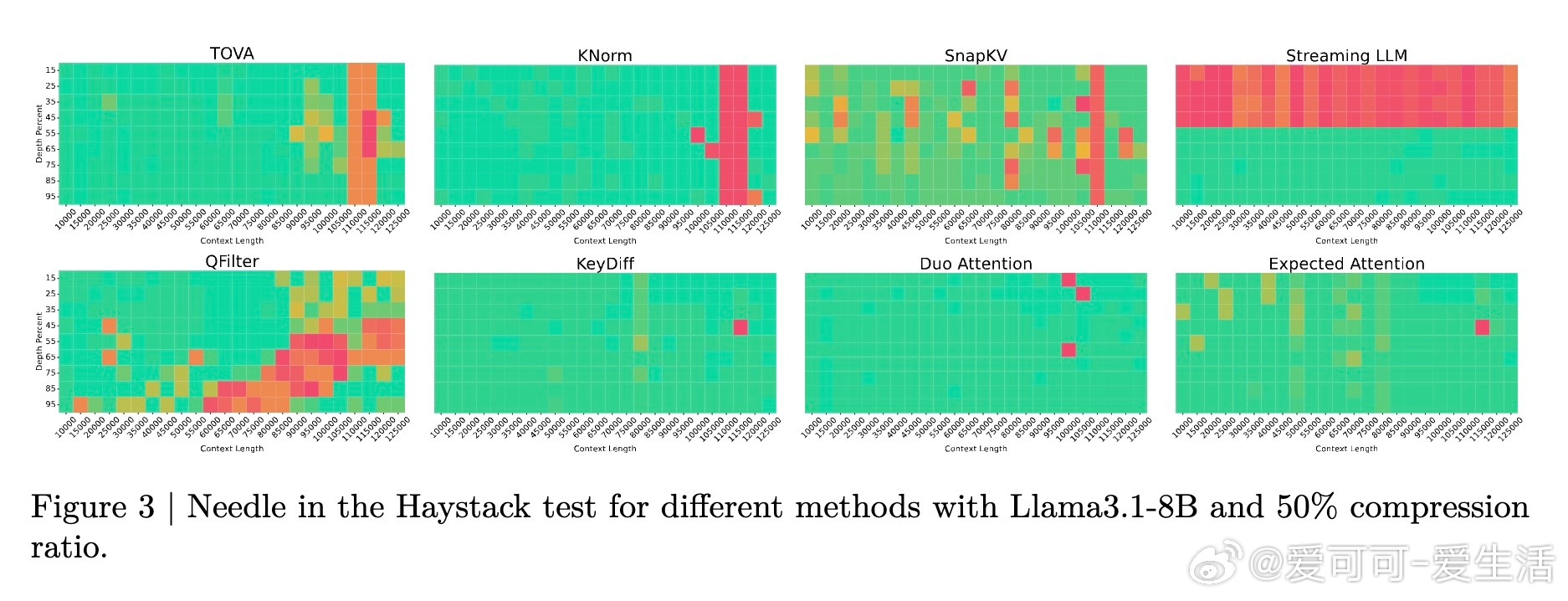
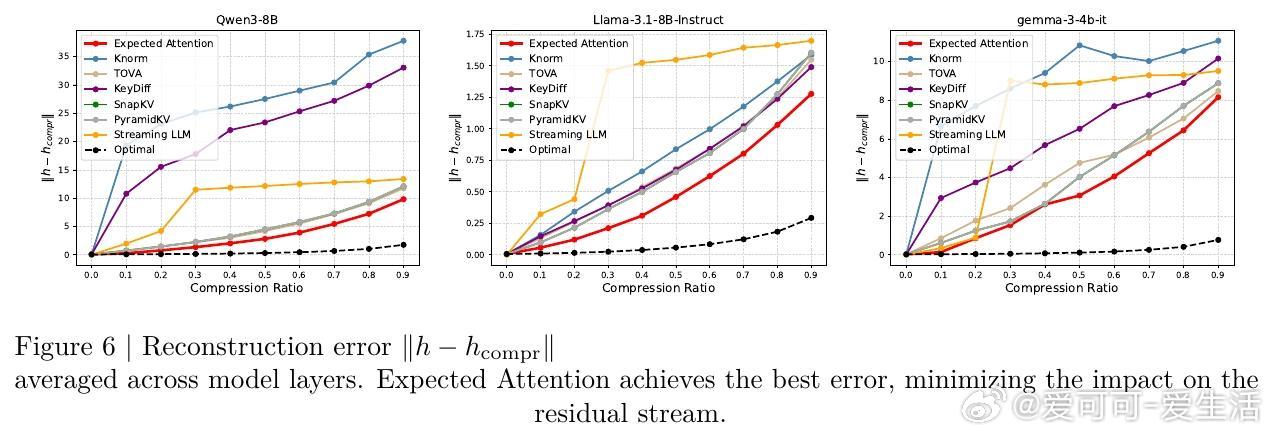
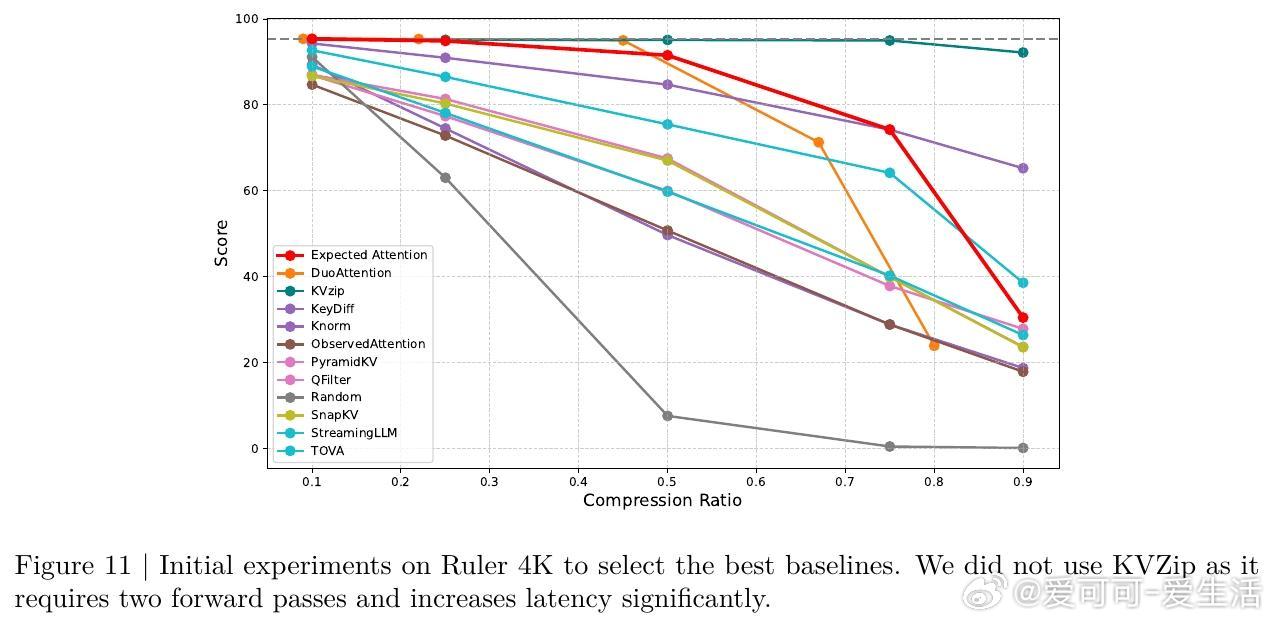
- 在多模型(Llama3.1-8B、Qwen3-8B、Gemma3-12B等)及多任务基准(LongBench、Ruler、Needle in a Haystack等)上,Expected Attention压缩效果优于多种领先方法;
- 在推理解码阶段,尤其适用于链式推理生成,支持高压缩率下保持数学推理准确率;
- 压缩率最高可达60%,显著降低内存占用,减轻硬件压力。
🔧工具发布:
论文团队开源了KVPress库,集成超过20种KV缓存压缩技术,支持快速实现与公平评测,助力研究社区发展。
⚠️局限与未来:
- 训练自由但性能略逊于部分可训练压缩方法;
- 需手动设定压缩比例,未来可探索自适应压缩策略;
- 当前PyTorch实现非部署级优化,期待后续高效CUDA版本。
总结:
Expected Attention通过创新地利用未来查询分布,提供了一条无需训练即可实现KV缓存高效压缩的实用路径,显著缓解了LLM长上下文推理的内存瓶颈,推动了大模型高效推理技术的发展。
👉论文详读:
大模型 KV缓存压缩 长上下文 Transformer AI推理优化 ExpectedAttention KVPress