我今天上午花了大半天时间,把Seedance 2.0的技术报告又重新看了一遍。
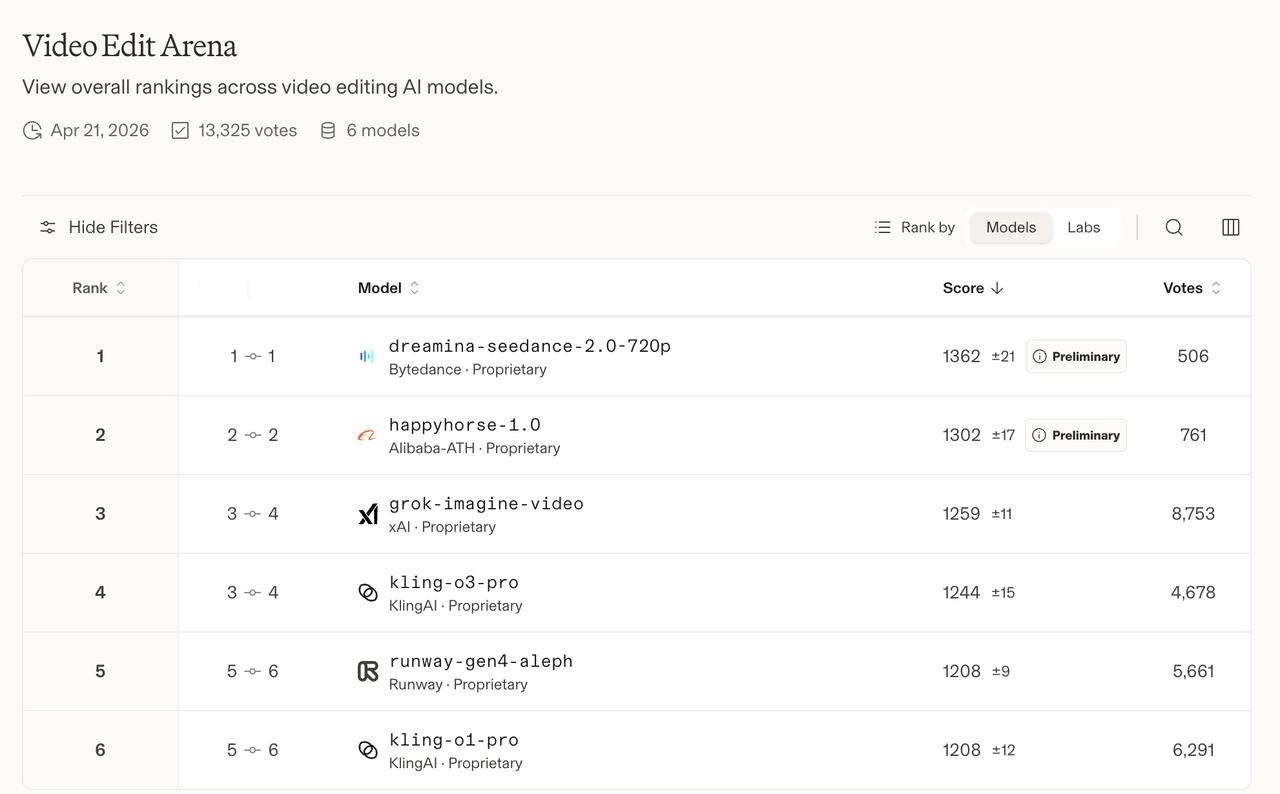
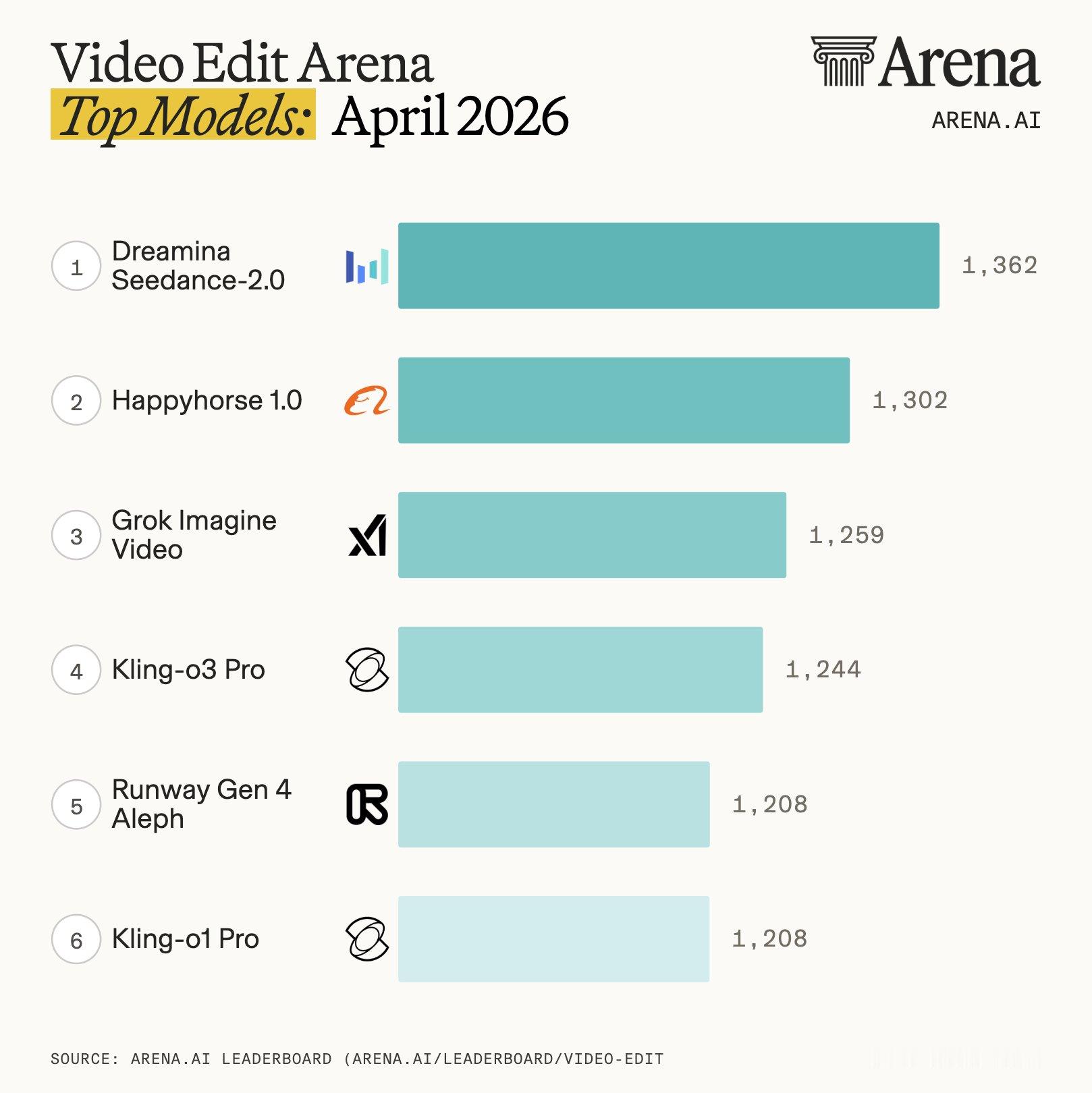
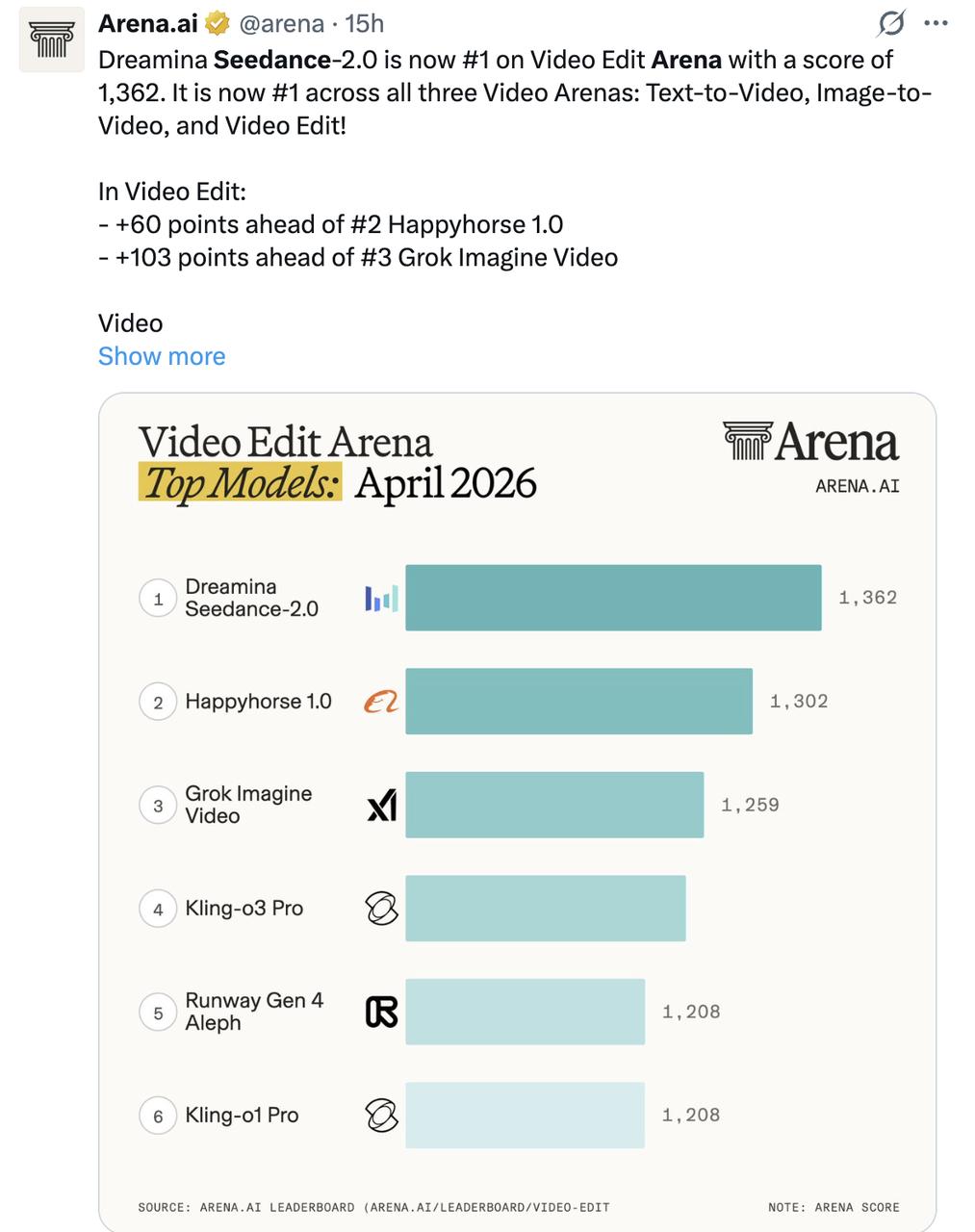
起因是昨天看到群里有人发Arena榜单,Seedance 2.0在文生视频、图生视频、视频编辑三个赛道上全部拿了第一。
要知道,Arena的评测机制是双盲对战。用户提交任意提示词,系统随机调两个匿名模型各生成一次。看完之后用户投票哪个更好,累积下来用Elo积分排名。
这套机制来自国际象棋的积分系统,越强的对手你打败了,涨分越多。长期跑下来,排名能比较客观地反映模型的综合实力,而不是某一项的专项能力。
所以这次Seedance 2.0登顶,非常值得关注一下——它在技术层面,到底做对了什么?
1想搞清楚Seedance 2.0的创新,得先说清楚这个领域的痛点。
做过AI视频创作的人都知道,想让AI生成一段像样的视频,光有提示词是远远不够的。你需要画面风格统一,保持人物一致性,音画匹配,还要多个场景之间有叙事逻辑。
这些需求单独拿出来还好说,但放在一起,就会各种打架。比如你改了角色的脸,背景风格就变了,或者你加了音乐,口型就对不上来。
为什么会这样?以前的模型基本都是分模块训练的,文字理解、图像处理、音频都是单独的模块,各自训练完再拼在一起。这种拼接结构的问题在于,信息在传递过程中会损耗,各个模块之间的对齐永远差那么一点。
最终导致,虽然你能生成视频,但你很难控制它。这个「控制权」,就是AI视频领域一直没有被真正解决的核心矛盾。
2所以,Seedance 2.0选择从根上改变这件事。
技术报告里最值得关注的一个设计,是统一多模态架构。
比如以前是各模块分开处理再拼合,Seedance 2.0换了一个思路:把文字、图片、音频、视频四种输入,一开始就放进同一个框架里统一处理,映射到同一个语义空间里。
比如,你是一个电影导演,想要指挥一场拍摄。你给摄影师看参考图,给音乐总监放背景音,跟演员说走位,跟剪辑讨论节奏。这些信息的格式都不一样,但因为所有人在同一个现场、随时可以沟通,最终呈现出来的结果是统一的。
Seedance 2.0干的事情就是把这个现场搬到了模型内部。官方说最多可以同时处理9张图片、3段视频、3个音频文件作为参考素材,这些输入在进入模型之后不是分开排队的,而是一起被理解、一起参与生成。
这个结构变化带来的直接效果,是控制权回到了创作者手里。
先说角色一致性。现在,你给它一张人物图,它能在整个视频里记住那个人的脸、服装和体型,多场景切换不会偷偷换人。这件事听起来简单,但之前的模型在这一点上经常翻车,创作者要花大量时间在后期修正。
再比如镜头控制。现在,推镜头、跟镜头、俯拍,你都可以直接描述,也可以给它一段参考视频让它学那个风格来做。
还有音画同步。技术报告里提到了一个双分支架构,一条流水线处理视觉,一条处理听觉,两条线在运行中实时交换信息、互相对齐。生成出来的视频里,口型、脚步声、环境音都是原生同步的。
而这里面分量最重的,是它的多镜头叙事能力。不只是生成一段视频,而是理解一个故事的前后逻辑,保持人物状态的连续性,让不同场景之间的氛围和风格能够衔接。
这一步,让AI视频从随机片段生成,迈向了真正意义上的内容创作。
3说完架构,还有一个绕不开的问题:数据训练。Seedance 2.0的训练数据体量估计在PB级别,1PB等于1024TB,是个很难直观感受到的数字。
但数据量不是核心,数据工程才是。原始的网络视频充满噪声,低分辨率、抖动镜头、音画不对,这些都得清洗和筛选。给每段视频打精确的场景、动作、情感、镜头类型标签,这套标注流水线的成本和复杂度,不比模型架构本身低。
所以Seedance 2.0能做到今天这个水平,是算法创新和数据工程两件事一起发力的结果,单靠其中一个走不到这里。
但数据这件事,也带来了现在最大的麻烦。原计划2月底上线的全球API,因为好莱坞内容公司发出版权警告而延期了。那些视频在互联网上是公开的,但版权属于原作者,用来训练商业模型的边界,法律上一直没有定论。
目前字节在国内通过火山引擎向企业用户有条件开放,国际市场还没有走通。
这个问题不只是字节一家的困境,整个AI视频生成行业都面临同样的处境,只是字节跑得最快,先撞上了。
4技术层面的分析说完了,但未来呢?这件事如果继续发展下去,视频创作的竞争核心会变成什么?
以前做视频最大的门槛就是技术,但现在这些正在被AI快速抹平。这对一部分人是威胁,但对另一部分人来说,又是一个很大的机会。
当然,Seedance 2.0今天的第一,不代表格局就此定了。这个赛道的竞争,才刚刚进入真正激烈的阶段。