1M上下文的GLM5.2基本可以保证我们这种基于PR的开发全程无需压缩,这点非常重要,因为一压缩就会损失一部分上下文精度,尤其是在Debug阶段反反复复跟Agent确认修复点时,很容易在后续的修复里出错;其次不压缩也会快很多,配合好缓存还会更省钱。这次明显感觉到GLM5.2的首token速度和每秒输出速度都快很多,而速度也越来越重要——我们的任务正在越来越长,等待的时间也越来越久,更快的速度会让体验真的好非常多。
这次提升更明显给了用户更好的信任和信心感,在我们自己的通用开源Agent Proma里并行了几个任务,分别用DeepSeek v4 Pro、Claude Opus 4.6和4.8以及GLM5.2同时解决一些Bug,GLM5.2在速度和准确性上比DeepSeek v4 Pro要好;在速度和处理偏好上比Claude Opus 4.6和4.8更好一点,通用任务能力上我觉得相差不大(这更多取决于用户自己的知识和表达,影响可能还要更大)。
1M上下文的好不必多说,如果你跟我一样经常在Agent里盯着上下文小心翼翼,肯定能感觉到1M会让你放松很多;另一个很容易被忽略的是1M上下文下的遵从能力,尤其是长度达到500K以上时,是否还能正常记起更早的上下文并遵从。
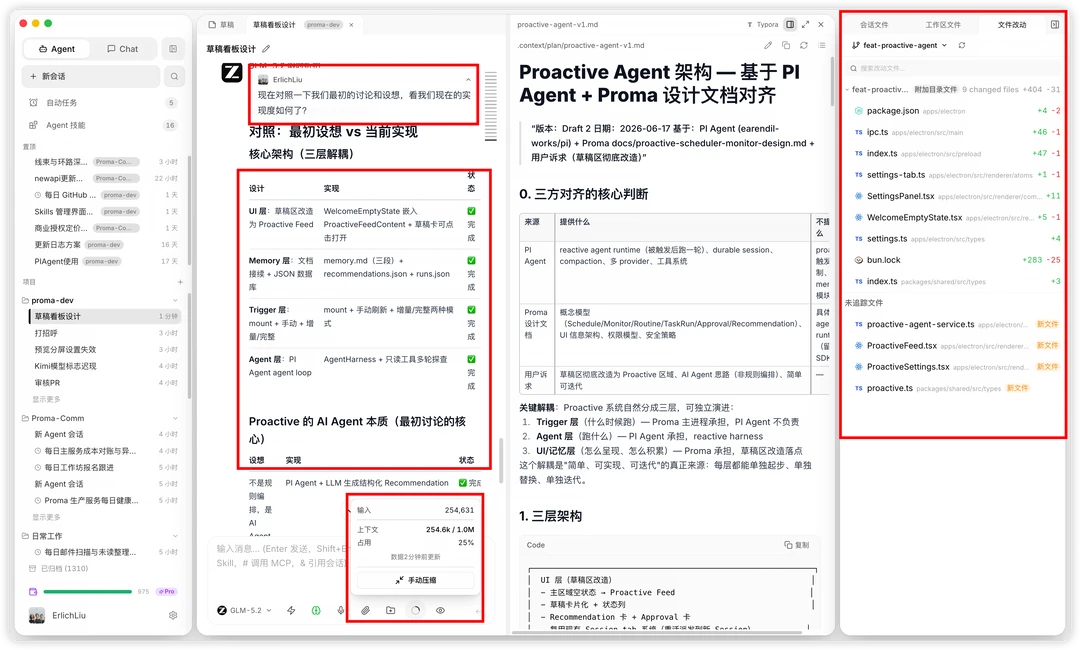
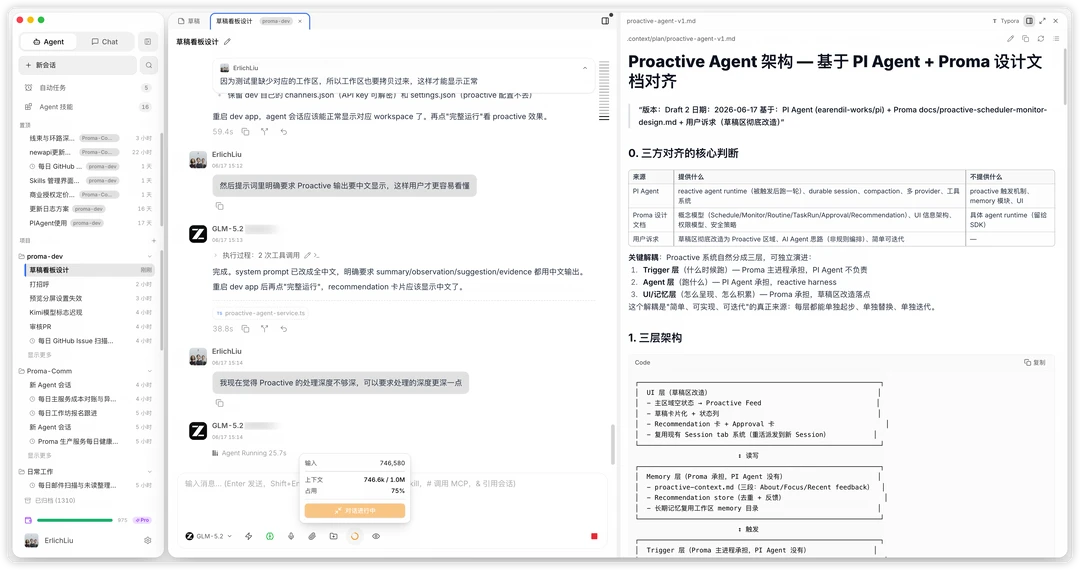
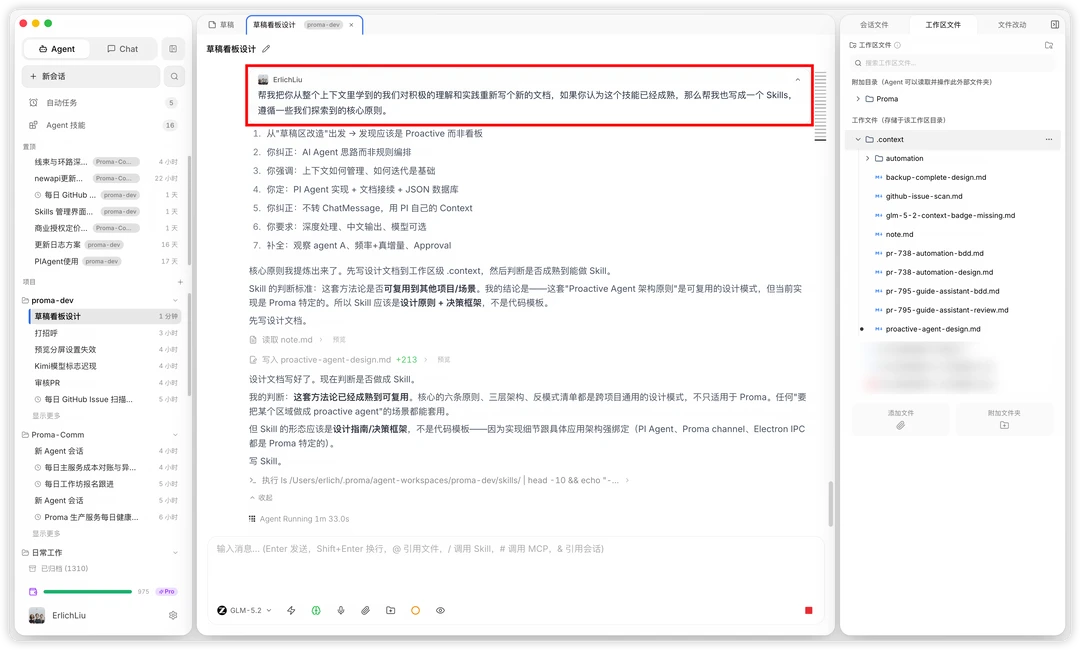
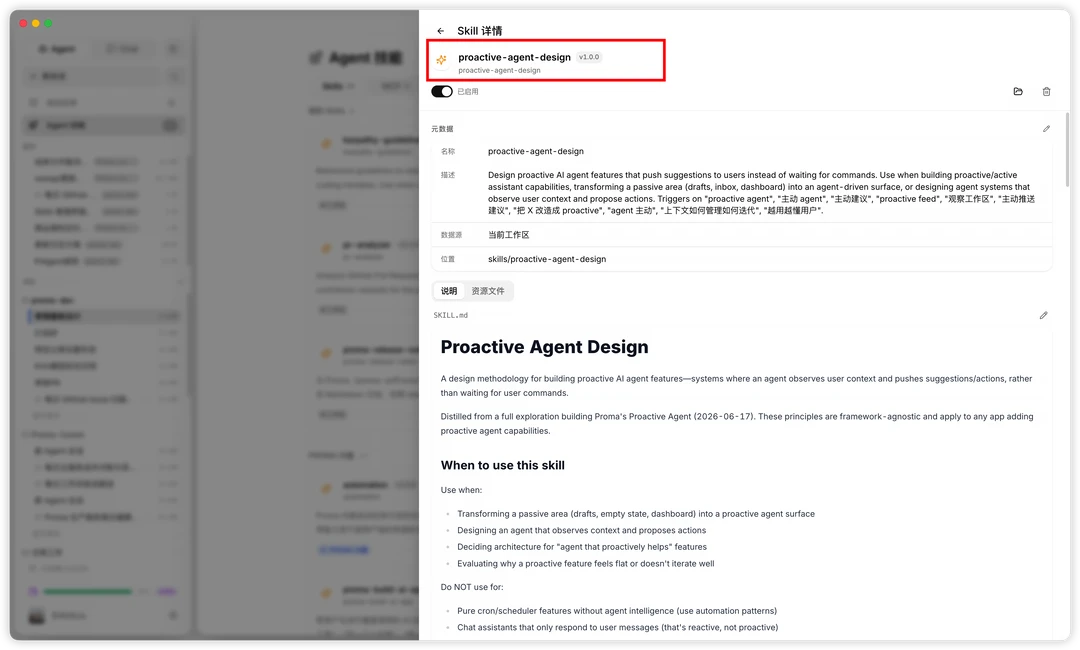
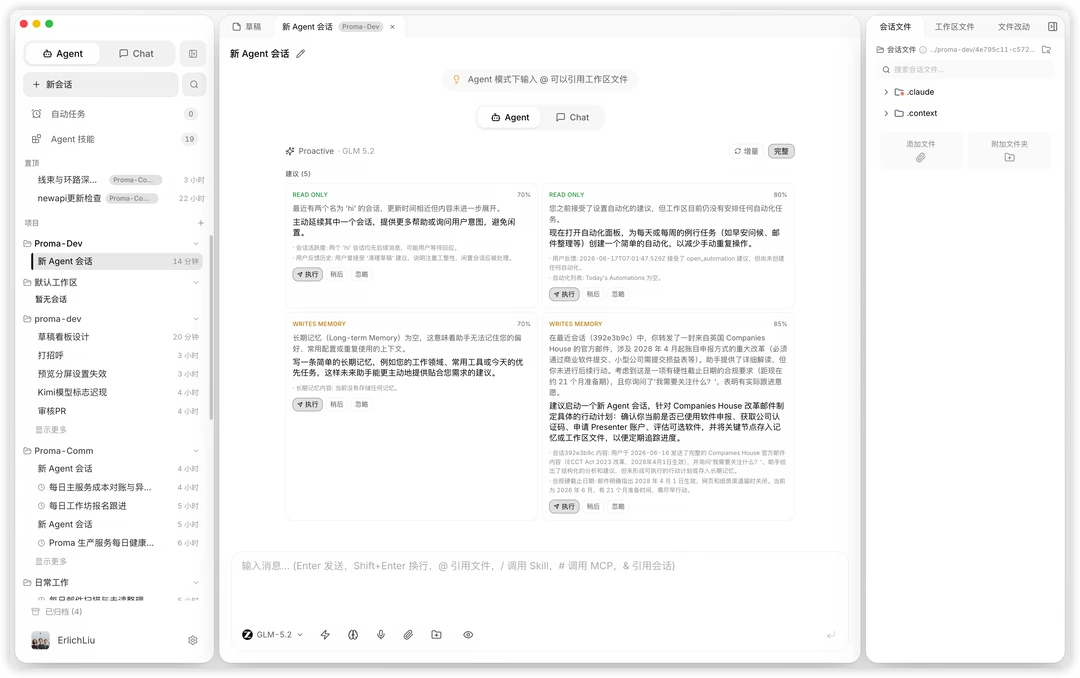
我用GLM5.2做了一次Proma完整的Proactive Demo开发,截图里可以看到任务执行了大概几十轮,上下文占用达到250K左右,仍能主动使用最初的讨论内容,这在实际开发里非常有价值。这个PR本身很重要也很大,我们尝试继续在这个会话下开发,甚至上下文打到700K以上仍能稳定完成迭代;并且在本次开发结束前,我希望GLM5.2帮我把一些洞察留下来,还整理了文档和Skills,这也非常考验长上下文能力;最后给大家展示一个几个小时就能跟GLM5.2一起从0开始嵌入PI后的初版Proactive功能吧!