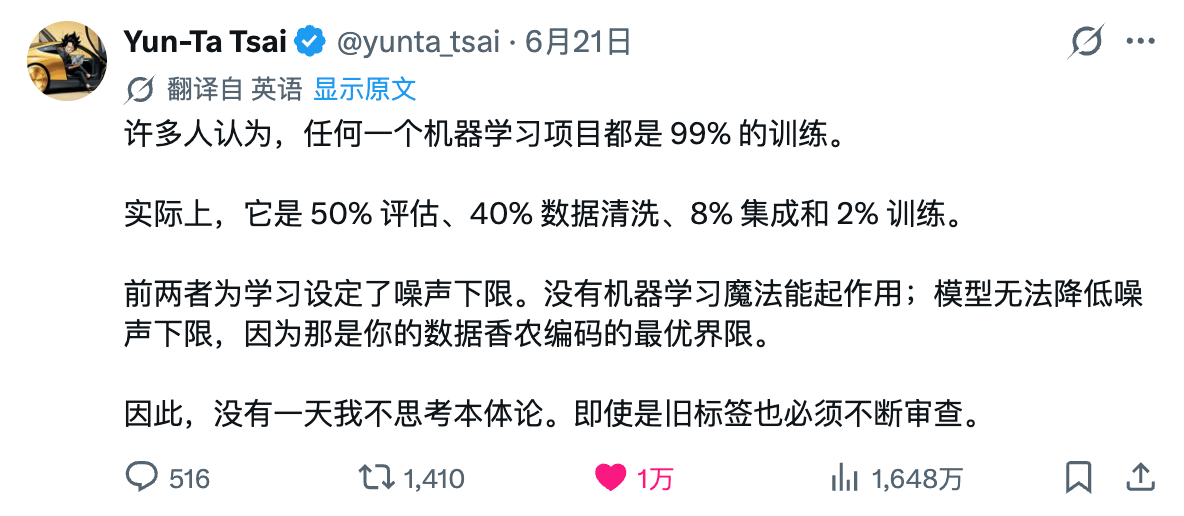
蔡云达:许多人认为,一个机器学习项目里 99% 的工作都是在进行训练。
但现实中,它是 50% 的评估、40% 的数据清洗、8% 的系统集成,以及仅仅 2% 的训练。
前两者决定了学习的「噪声下限(noise floor)」。没有任何机器学习的魔法能起作用;模型无法降低噪声下限,因为那是你数据中香农编码(Shannon encoding)的理论最优极限。
因此,没有一天我不去思考本体论(ontology,即概念与分类体系)。即使是旧的标签,也必须不断地进行复查。
---
这段话尤其后两段读下来,如果不是理工科,难免一知半解。下面 Gemini 写的这个小寓言,可以很好的帮助加深理解:
在大山深处,有一个自古流传的塞外古镇,镇民们世世代代依靠酿造一种名为「神启」的秘药维生。传说这种秘药只要喝下一口,就能让人看清未来的迷雾。
镇上最年轻的酿酒师名叫陈儿,他极其崇拜古书里记载的「圣火淬炼法」。陈儿总觉得,酿药最核心、最神圣的秘密,就在于最后那九天九夜、用火炉进行的猛烈控火和熬煮。他逢人便说:「只要火候完美,顽石也能炼成金丹。熬煮,才是赋予秘药灵魂的 99%。」
为了证明自己,陈儿决定独自酿造一炉旷世秘药。
第一天,他去后山的「真理之泉」挑水。然而,那口泉水久未打理,里面混杂着枯枝、烂泥和死去的昆虫。陈儿急着回去架炉点火,他心想:「有点杂质怕什么?等我的火炉火升起来,几千度的高温什么东西烧不化?圣火能净化一切!」于是他粗粗捞了几把,就挑着浑浊的泉水回去了。
接下来的日子里,陈儿把所有的时间和精力都花在了对火候的精细控制上。他寸步不离炉火,调整着每一缕微风的灌入,计算着木柴的摆放角度,汗流浃背,甚至自豪地认为自己达到了前所未有的技术巅峰。
终于,到了开炉的日子。
药汤倾倒而出。然而,那不是什么澄澈的秘药,而是一碗散发着恶臭、粘稠而浑浊的黑泥。陈儿彻底崩溃了,他哭着去找镇上最年长的智者。
「我的火候毫无瑕疵!我用了最完美的淬炼魔法!」陈儿咆哮着,「为什么会这样?」
智者没有看他的药炉,而是跟着陈儿来到了那口真理之泉。智者蹲下身,用一个极细的竹筛在泉水里捞了捞,指着里面的泥沙说:「孩子,你把 99% 的心血花在了那几天的烈火熬煮上,但实际上,你真正需要做的,是花一半的时间去用肉眼和舌头尝测这泉水的分量与毒性,再花四成的时间去过滤掉这里面的泥沙和枯枝。至于你引以为傲的控火熬煮,不过占了最后那微不足道的两成气力。」
陈儿不服气地辩解:「可是圣火难道不能把这些泥沙都烧成灰烬吗?」
智者摇了摇头,叹息道:「天地间有它不可违背的法则。水里混了多少沙子,最后药里就必定留下多少杂质。你的圣火再神奇,也无法超越这碗水本身具有的混乱。只要源头是脏的,世界上就没有任何魔法能把脏水煮成甘露。这口泉水原本的混乱程度,就是你药效的极限。」
陈儿低下头,看着那口混杂着无数腐叶和死水蝇的泉水。
「那我该怎么做?」
智者从怀里掏出一本泛黄的《万物命名录》,递给陈儿:「你得从最基础的活开始。每天清晨,你不能先去生火,而是要坐在这里,一遍遍地分清什么是落叶,什么是浮萍,什么是有毒的苔藓。你要给它们分类,把不该属于这口泉水的东西一件件挑出去。甚至连你昨天以为是中药的那些枯草,今天也要重新审视,看看它是不是在夜里腐烂变质了。只有当你把这口泉水的分类和纯度琢磨透了,你的火,才有意义。」
---
所以很简单:
圣火淬炼/熬煮 → 模型训练 Training。一半的时间尝测 → 50% 评估四成的时间过滤 → 40% 的数据清洗
浑浊的泉水就是带有噪声的数据。如果你的标签是错的、数据充满了噪音,无论用多么高深、多么魔法的深度学习模型,它也无法凭空把错误的数据修正为正确的预测。模型的上限,被数据质量卡住了。
---
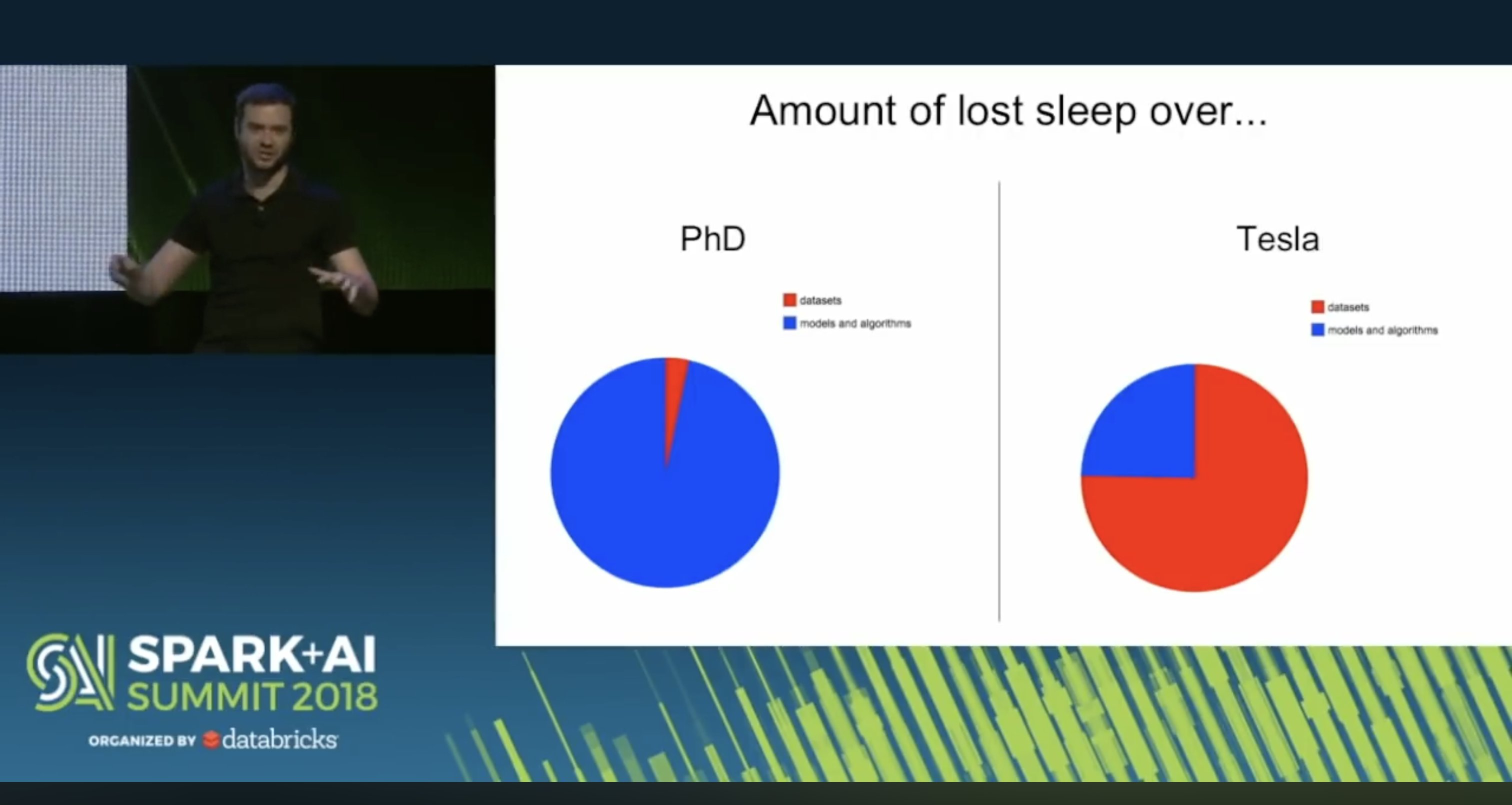
无独有偶,2018 年 Andrej Karpathy 分享他在读博期间和在特斯拉工作期间失眠的原因,在学术界读书时 90% 以上的精力在反正调整模型和算法,到了工业界在特斯拉工作时 75% 的时间都在反复迭代调整数据集。
其实是一个意思。