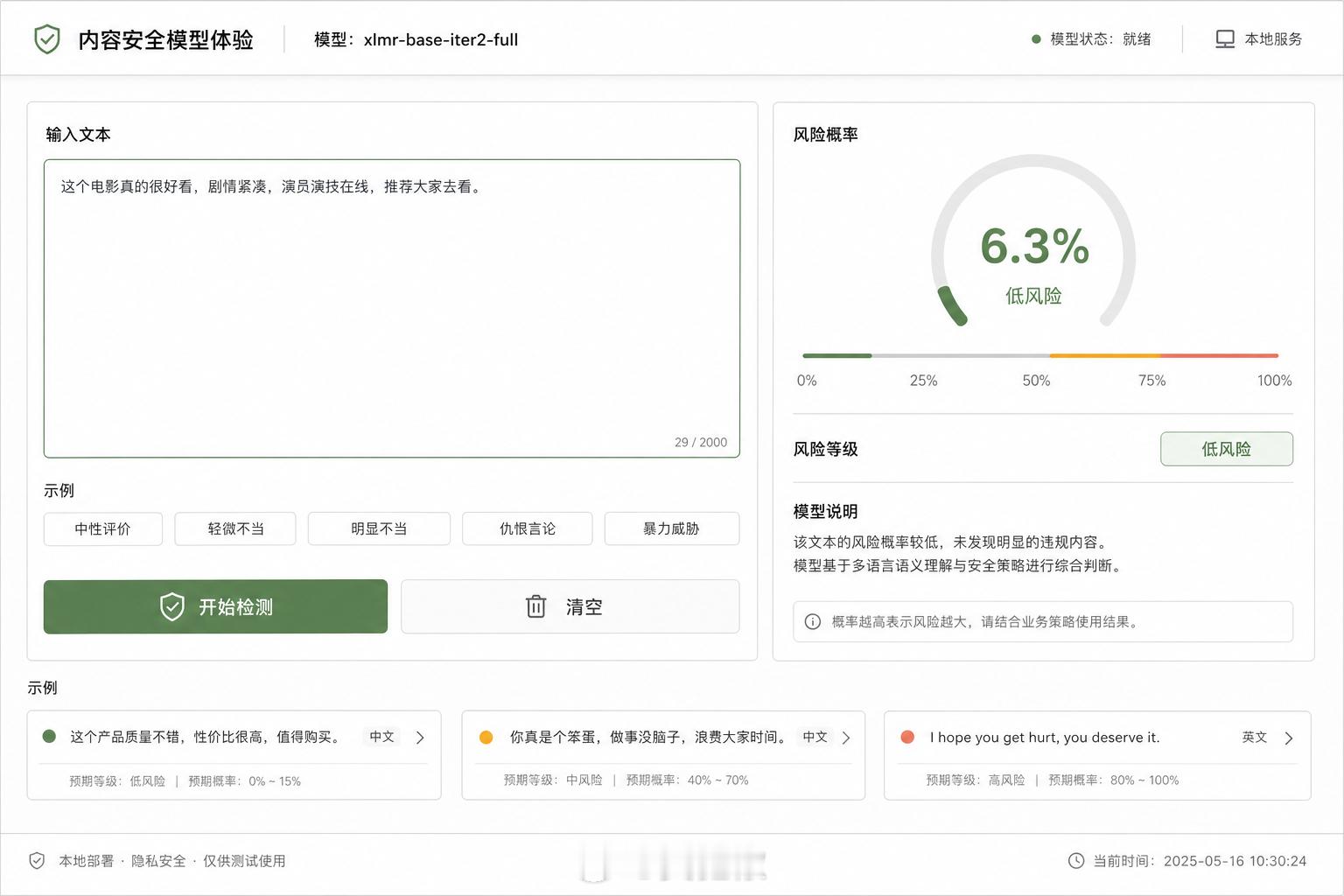
让Codex复现优胜AI模型,顺便配了个试用前端。为了避免骂人,示例借用网友上一世的名讳。
操作很简单,找到某个竞赛,让它找优胜方案,先plan确认是否理解要求,再goal开启训练,持续运行。
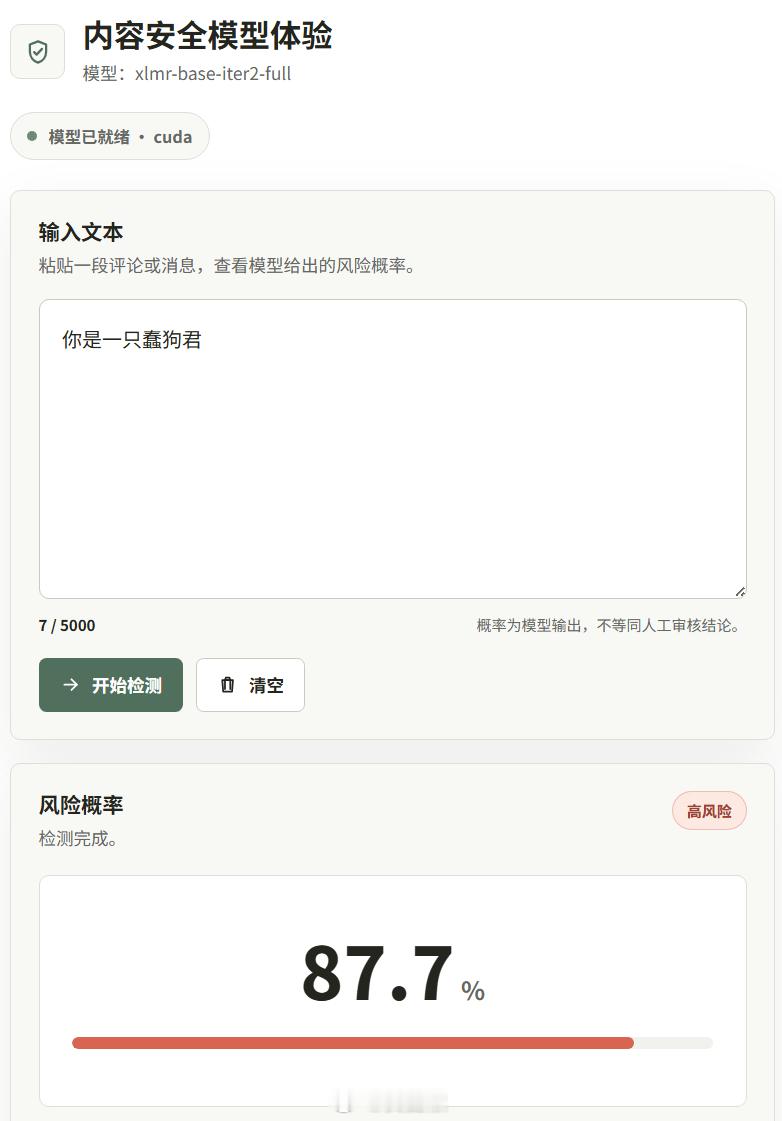
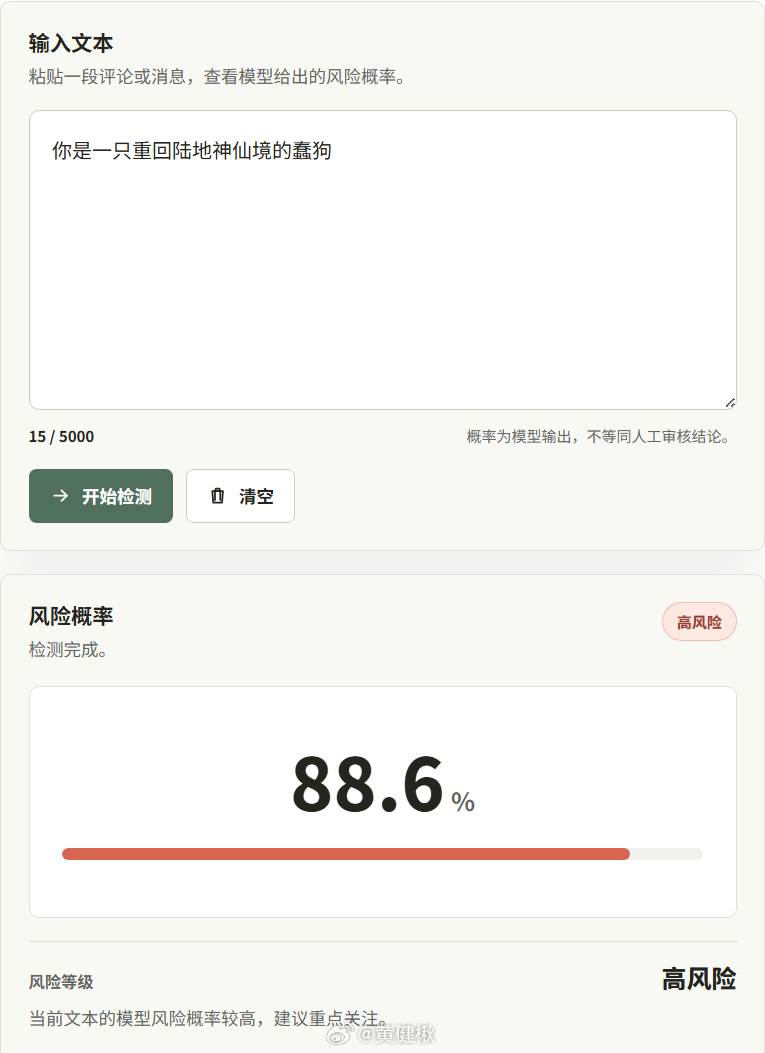
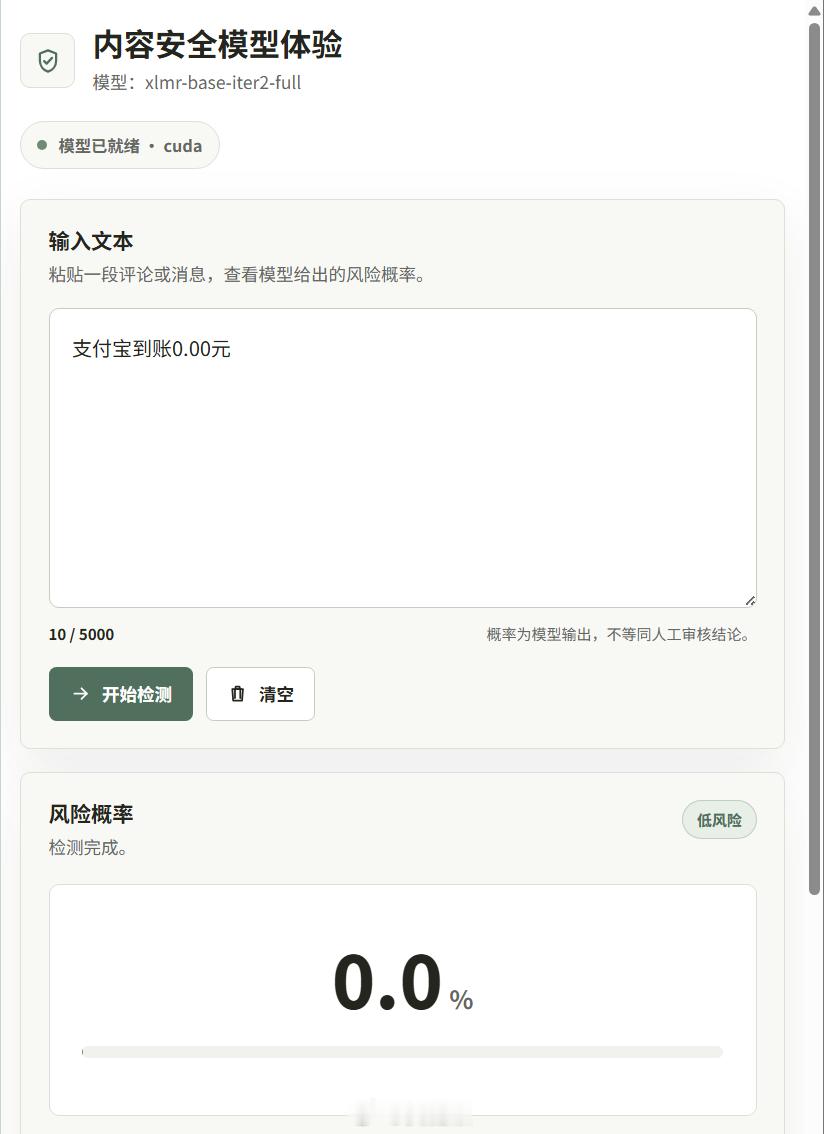
竞赛主题是多语言有毒评论分类(Jigsaw Multilingual Toxic Comment Classification)原优胜方案用xlm-roberta-large做到0.9536,本地为了节省时间验证用了xlm-roberta-base,做到了0.8877,看着效果还行,至少达到我的预期(训练起来了),3080TI上80ms判定一次。
操作很简单,找到某个竞赛,让它找优胜方案与相关资料,然后让它写出训练方案(plan模式),确认它理解要求后,再开启训练,可用goal模式持续运行。
资源占用情况。不算本来就有的python相关依赖,存储最终占用20GB(训练、验证数据6GB,单个模型1GB),耗时约4小时。
AI貌似没有考虑训练过程中断了怎么办(断点续连)。
如果拓展到large,估计磁盘占用会来到120 GB,12GB显存会开始吃不消,最好去“租显卡”。最近租用价格好像还降了。 How I AI
另外让Codex写前端的时候,它自行调用了GPT-Image-2生成Demo(图五),可惜实现有点偷懒了哈。
可能有人会问不给方案会怎样。我试过了,给些玩具都算不上的demo方案。