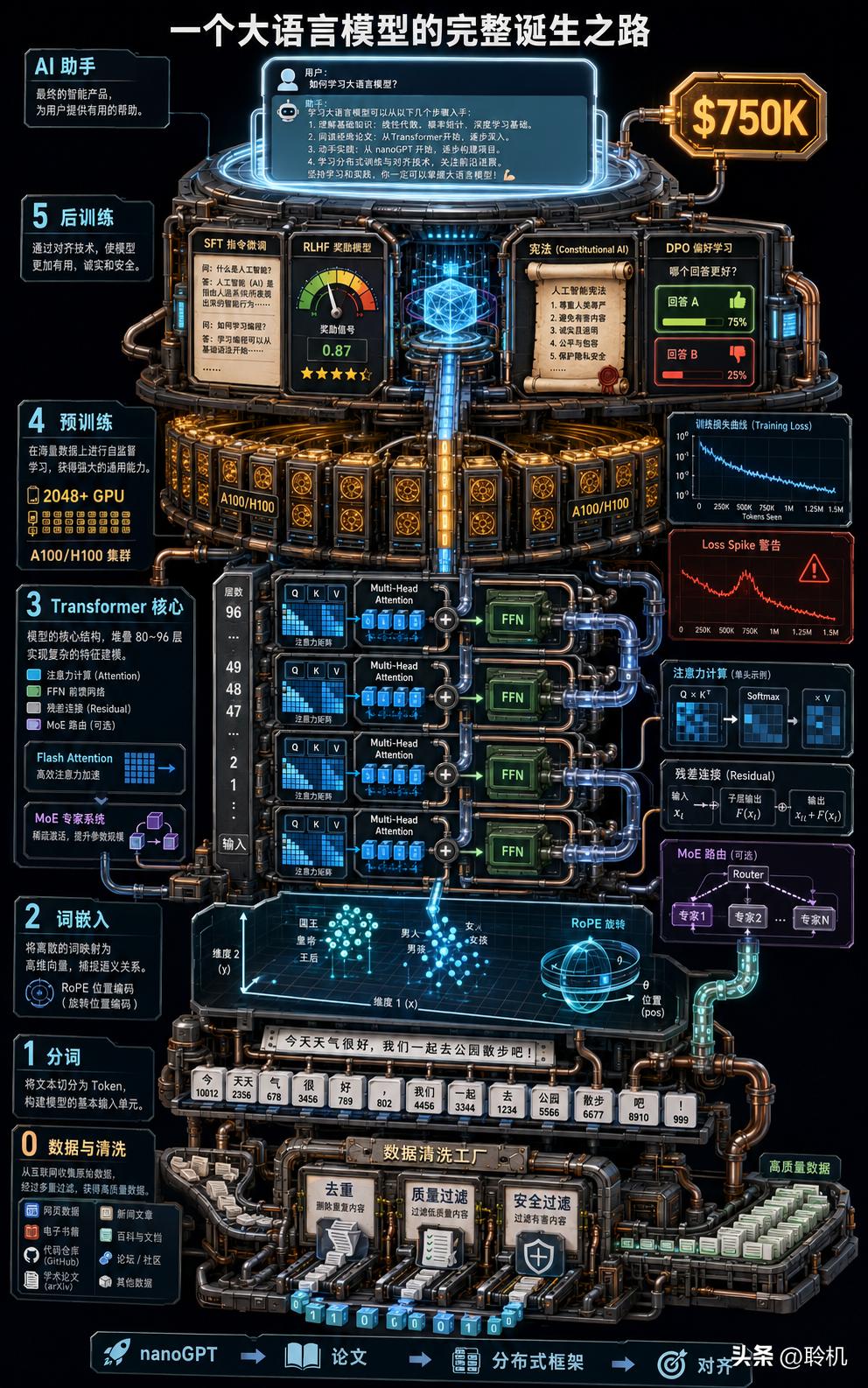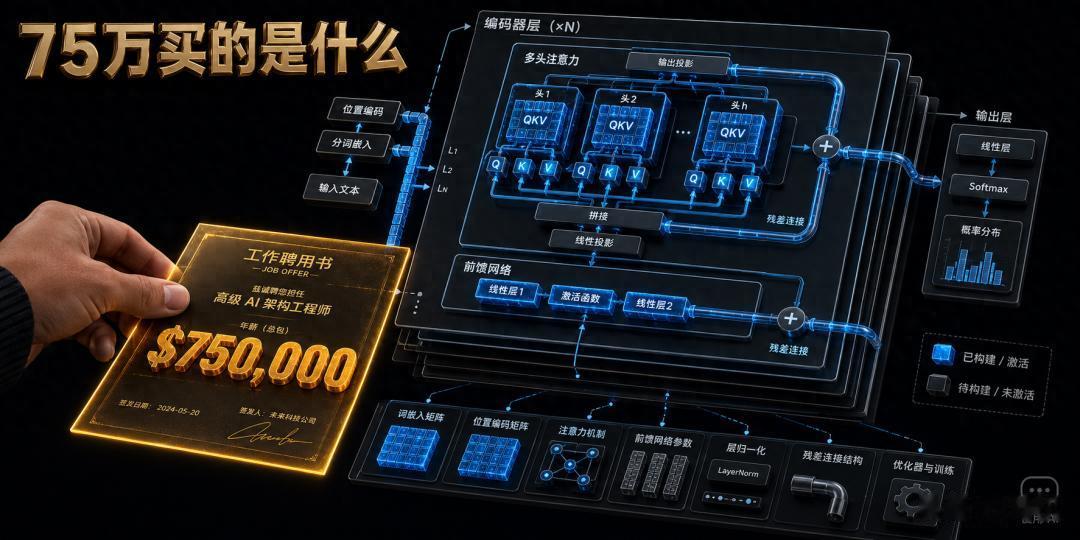
75 万美元。这不是某家投行高管的年终奖,也不是创业者上市后的套现——这是一家 AI 公司给一个普通软件工程师岗位开出的年薪。
根据 Levels.fyi 的公开薪酬数据,Anthropic 高级软件工程师的总包(TC)中位数落在 56.3 万到 79.5 万美元之间,首席工程师能到 89 万美元以上。基本工资大约 30 到 33 万,剩下的大头全部来自股权和 RSU。
什么工程师值这个价?
不是"会调 API",不是"懂一点 PyTorch",也不是"跑通过几个开源 demo"。Anthropic 要的是能从零构建大语言模型的人——从数据清洗到架构设计,从分布式训练到强化学习对齐,整条流水线上每一个环节,都能亲自操刀。
这意味着什么?当你下次在对话框里敲下一行字,ChatGPT 在零点几秒吐出一段流畅回答的时候——那个回答背后,是一条精密到极致的技术流水线。这篇文章要做的,就是把这条流水线从第一个字符到最后一行代码,完整拆给你看。不堆术语,不搞玄学,就当我们在厨房做一道菜,一步一步告诉你每一味调料为什么放进去。
第一步:把人类的语言变成机器能吃的数字大模型不认识汉字,不认识英文,不认识任何符号。它骨子里只有一样东西:数字。
所以构建大语言模型的第一步,是解决一个看似不可能的问题——怎么把"今天天气真好"这句话,变成一串数字?
答案是分词(Tokenization)。
分词器干的事情,类似于把一整块面团切成大小不一的小块。切面依据不是字符数量,而是语言中的"高频组合"。最常见的算法叫 BPE(Byte Pair Encoding),它的工作方式像一个勤快的统计员:先把所有文字拆成最小单位(单个字节或字符),然后统计哪两个相邻单位出现频率最高,就把它们合并成一个新单位,再继续统计、继续合并,反反复复,直到达到预设的词表大小。
举个例子。单词"unhappiness",BPE 可能会把它切成三个 token:un、happ 和 iness。为什么这么切?因为 un(否定前缀)、happ(快乐词根)和 iness(名词后缀)在英语中出现频率都很高,单独作为 token 可以复用到无数其他单词中:un 可以拼出 unlikely、unreal,iness 可以拼出 business、likeness。
GPT-4 使用的分词器叫 tiktoken,词表大小大约 10 万个 token。中文的 token 效率比较低,一个汉字经常要消耗 2-3 个 token,这也是中文场景下 API 费用更高的原因之一。
这里有个很多人忽略的工程细节:分词器的质量直接决定了模型的上限。如果分词器把"深度学习"切成"深""度""学""习"四个碎片,模型就很难学到"深度学习"作为一个整体概念的语义。好的分词器会把"深度学习"作为一个 token,让模型直接在概念层面建模。这也是 OpenAI、Anthropic 在分词策略上花大量时间调优的原因——它看似是预处理步骤,实则影响着模型理解世界的颗粒度。
还有一个冷知识:分词也是大模型有时"算不对数学题"的原因之一。模型看到的不是数字"12345",而可能是 token "12" 和 "345" 两个碎片。它需要从这些碎片中重建数字的完整含义,这个过程很容易出错。后来很多模型专门引入了"数字分词"策略,把数字逐位切分("1""2""3""4""5"),大幅提升了数学能力。
分词完成后,每个 token 都会被分配一个整数编号。比如"今天"可能是 token #18342,"天气"可能是 token #28901。一句话就变成了一串数字:[18342, 28901, 8933, 44520]。
到这一步,语言已经变成了数字。但数字之间还没有"意义"——18342 和 28901 之间的关系,和 18342 与 99 的关系,在数学上没有任何区别。这就引出了下一步。
第二步:让数字长出"意义"——词嵌入词嵌入(Embedding)解决的是"意义"问题。
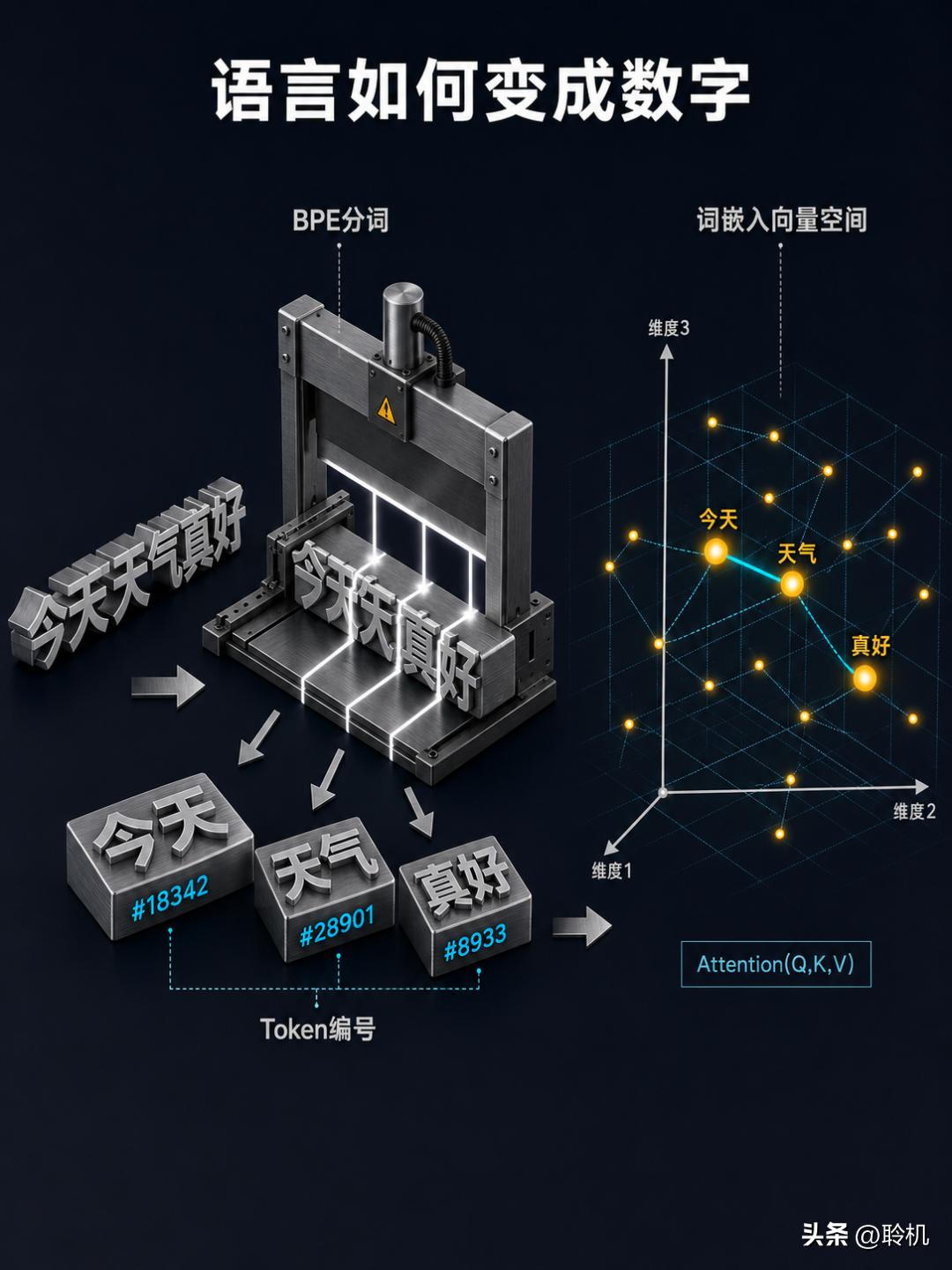
做法听起来很暴力:给每个 token 编号分配一个很长很长的向量。有多长?GPT-3 用的是 12288 维,LLaMA-2 7B 用的是 4096 维。你可以把它理解成,每个词都被放在一个几千维的空间里,拥有一个唯一的坐标。
关键在于,这些坐标不是随便填的。训练过程中,模型会自动调整每个词的坐标,使得意思相近的词在空间中的距离也相近。"猫"和"狗"的向量会比较接近,"猫"和"航空发动机"的向量会差得很远。更神奇的是,向量之间的方向也有语义:"国王"减去"男人"加上"女人"约等于"女王"——向量运算竟然能对应到语义逻辑。
光有词义还不够。一个词在不同位置、不同语境下,意思可能完全不同。"苹果"在"我吃了一个苹果"里是水果,在"苹果发布了新手机"里是公司。模型怎么区分?
答案是位置编码(Positional Encoding)。最原始的做法是给每个位置生成一个固定的编码向量,和词嵌入向量逐位相加。更现代的做法是 RoPE(Rotary Position Embedding,旋转位置编码),LLaMA 系列用的就是这个——通过旋转矩阵把位置信息编织进向量中,让模型能自然理解"谁在谁前面"的相对关系。
到这一步,输入文本已经变成了一组既有词义又有位置信息的向量。但这还只是原材料。真正让大模型"理解"语言的引擎,是接下来这个发明。
第三步:Transformer——那个改变一切的引擎2017 年,Google 的八位研究员发了一篇论文,标题叫《Attention Is All You Need》。这篇论文提出的 Transformer 架构,在此后八年里彻底改变了人工智能的轨迹。GPT、BERT、Claude、LLaMA、Gemini——今天你能叫出名字的大语言模型,没有一个不用 Transformer。
Transformer 的核心是一个叫自注意力(Self-Attention)的机制。
用大白话讲就是:让句子中的每个词,去"看"其他所有词,然后决定应该把多少注意力分给谁。
拿"银行"这个词举例。在"我去银行存钱"这句话里,"银行"应该更多关注"存钱",因为它需要理解这里的"银行"是金融机构而不是河岸(bank 既是银行也是河岸的意思)。自注意力机制让模型自动学会做这种判断。
具体怎么做的?每个词的向量会被分别投影成三个新的向量,叫做 Q(Query,查询)、K(Key,键)和 V(Value,值)。你可以把 Q 想象成"我在找什么样的信息",K 想象成"我能提供什么样的信息",V 想象成"我实际携带的信息内容"。
模型计算每个词的 Q 和其他所有词的 K 之间的点积。点积越大,说明两个词越"相关"。这个相关度分数经过 softmax 归一化后,就变成了注意力权重——一组加起来等于 1 的比例。最后,用这些权重对所有词的 V 做加权求和,就得到了这个词经过注意力处理后的新表示。
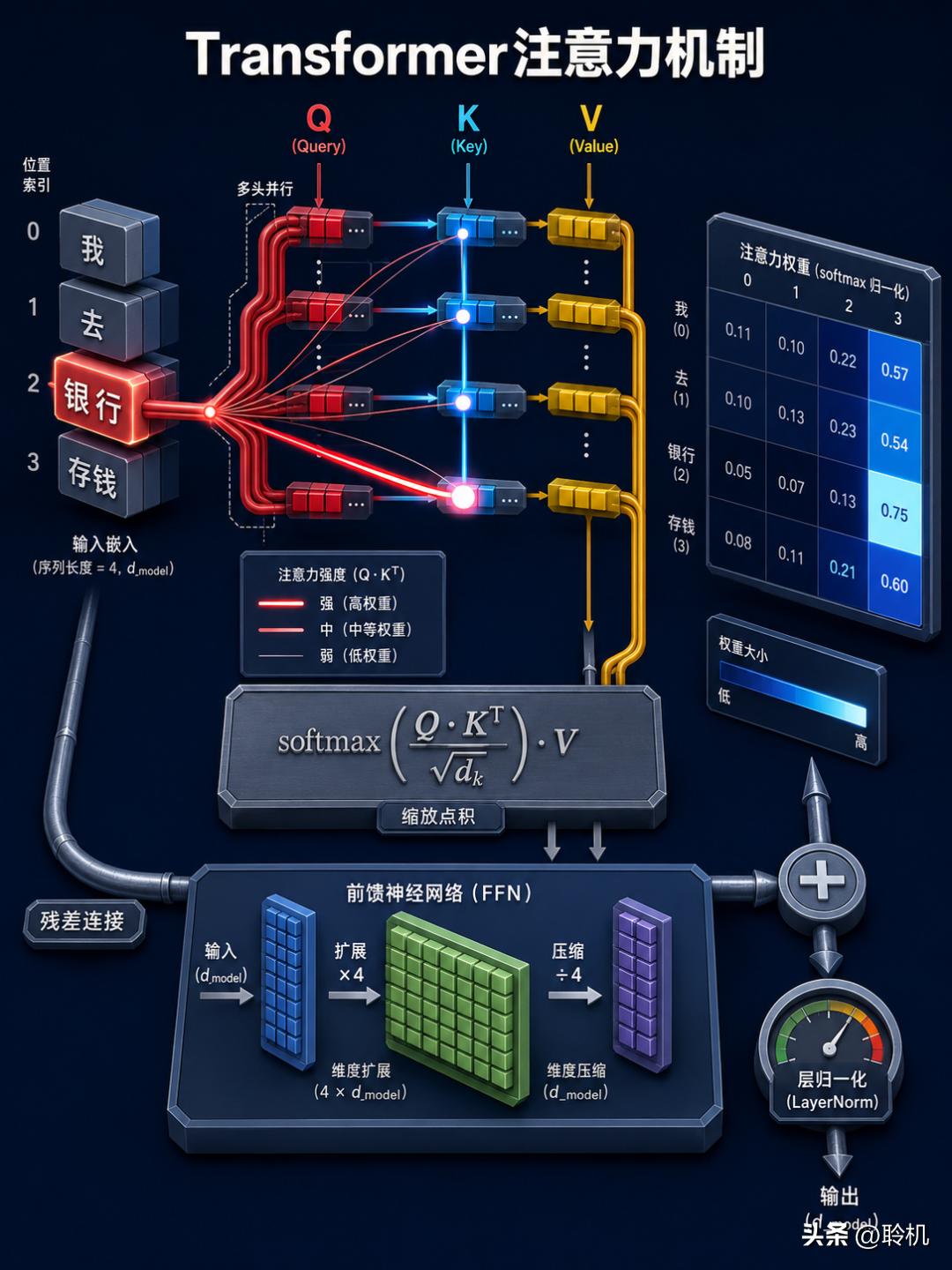
用公式写就是:Attention(Q, K, V) = softmax(Q·Kᵀ / √dₖ) · V
这里有个细节:除以 √dₖ(dₖ 是 Key 向量的维度)是为了防止点积数值过大导致 softmax 梯度消失。这种工程细节看似不起眼,少做了这一步,模型可能根本训练不出来。
实际的模型用的是多头注意力(Multi-Head Attention)——把上面这个过程并行做很多遍(GPT-3 用了 96 个头),每个头关注不同方面的信息,有的头可能关注语法关系,有的关注语义关联,最后把所有头的结果拼接起来。
注意力之后,向量会经过一个前馈网络(Feed-Forward Network, FFN)。FFN 由两个线性层和一个激活函数组成,先把向量维度放大(通常是 4 倍),经过激活函数,再压缩回原来的维度。激活函数的选择也在进化:最早用 ReLU,后来用 GELU,现在主流模型用 SwiGLU——这个由 Google 提出的激活函数在大语言模型上表现明显更好。
还有一个关键设计:残差连接(Residual Connection)和层归一化(Layer Normalization)。残差连接的做法是,每一层的输入会直接和输出相加:输出 = 子层(输入) + 输入。这看起来简单得不像话,但它解决了一个致命问题——当模型有几十上百层时,如果没有残差连接,梯度会在反向传播过程中指数级衰减或爆炸,根本无法训练。层归一化则是把每一层的激活值拉到均值 0、方差 1 的范围,让训练更稳定。现代模型大多采用 Pre-LN(在子层之前做归一化),LLaMA 则更进一步用了 RMSNorm——去掉均值的偏移,只做方差缩放,计算更简单,效果相当。
把上面的模块堆叠起来——多头注意力 → 残差连接 → 层归一化 → 前馈网络 → 残差连接 → 层归一化——就构成了一个 Transformer 层。GPT-3 把这个层堆了 96 层,LLaMA-2 70B 堆了 80 层。
近年来还有几个重要架构改进。GQA(Grouped Query Attention,分组查询注意力)让多个查询头共享同一组 Key 和 Value,大幅减少了 KV Cache 的显存占用,在不损失太多质量的情况下显著提升了推理效率。Flash Attention 从计算访存比的角度重新设计了注意力的计算顺序,避免了中间结果在 GPU 高带宽内存和 SRAM 之间的反复搬运,实现了精确注意力计算的速度翻倍。MoE(Mixture of Experts,混合专家)把前馈网络替换成多个"专家"网络,每次推理只激活其中 2-3 个,在总参数量不变的情况下大幅降低实际计算量。GPT-4 据报道就是 MoE 架构,Mixtral 8x7B 也是:8 个专家每次只激活 2 个,总参数 47B 但每次推理只用 13B 的算力。
架构搭好了。但这个模型现在还是一张白纸,什么都不会。它需要被"教育"。这个教育过程,就是预训练。
第四步:预训练——用万亿 token"教"模型说话预训练(Pre-training)是大语言模型构建过程中最烧钱、最暴力、也最关键的阶段。
训练目标简单到令人发指:预测下一个 token。 给模型一段文字的前 N 个 token,让它预测第 N+1 个是什么。比如输入"今天天气真",模型应该输出"好"的概率最高。这听起来像是个无聊的文字接龙游戏,但当训练数据达到万亿 token 级别,模型规模达到百亿千亿参数时,这个简单目标逼出了惊人的能力——语法、逻辑、常识、推理、翻译、代码……全都涌现出来了。这个现象有个专门的名字:涌现能力(Emergent Abilities)。没人能完全解释为什么预测下一个 token 这么简单的任务,在足够大的规模上会"涌现"出如此复杂的智能。但事实就是发生了,这是整个大语言模型领域最重要的经验事实之一。
但在正式开始训练之前,有一个容易被忽视却至关重要的环节:数据准备。这是 Anthropic 和 OpenAI 真正的"秘密武器"所在。
训练数据的来源包括网页爬取(Common Crawl)、书籍(Books3 等)、学术论文(arXiv)、代码仓库(GitHub)、维基百科、对话数据等。原始数据的质量参差不齐,充满了噪声——广告页面、重复内容、机器生成的垃圾文本、有害信息、个人信息……需要经过极为严格的清洗流程。
清洗管道的核心步骤包括:去重(MinHash 等近似匹配算法,去掉重复网页内容)、质量过滤(用小模型给文本打分,过滤低质量内容)、安全过滤(去除有害、涉暴、涉隐私数据)、语言识别(确保语言比例合理)、数据配比(决定网页文本、代码、学术、书籍各占多少比例)。这个配比直接影响模型的"性格"——代码数据多了,模型就更擅长编程;学术数据多了,模型就更"学术范"。

业界有个共识:数据质量比模型规模更重要。同一个架构,用更好的数据训练,效果可以超过两倍大小的模型。这就是 Anthropic 在数据清洗管道上投入大量顶尖工程师的原因——这也是"从零构建 LLM"中最难、最脏、也最值钱的部分之一。
预训练的过程是这样的:模型对输入序列中的每个位置都做一个预测,每个预测都是词表大小的概率分布。然后用交叉熵损失(Cross-Entropy Loss)衡量预测分布和真实分布之间的差距,通过反向传播(Backpropagation)计算梯度,用 AdamW 优化器更新模型参数。
关键挑战在于规模。训练 GPT-3(1750 亿参数)用掉了大约 3000 亿个 token,算力成本估计在 460 万美元以上。GPT-4 的训练成本据估计在 6300 万到 1 亿美元之间。最新前沿模型的训练成本已经突破 1 亿美元。
一张 GPU 装不下一个完整模型——GPT-3 的参数本身就需要 350GB 显存(FP32 精度),而一张 A100/H100 只有 80GB。所以模型必须被拆开,分布到成百上千张 GPU 上。这就是分布式训练。
三种核心策略:
数据并行(Data Parallelism):每张 GPU 拿一份完整的模型副本,处理不同的数据批次。各 GPU 算完各自的梯度后,做一次 AllReduce 同步梯度,然后各自更新。简单粗暴,但要求每张卡能装下完整模型。
张量并行(Tensor Parallelism):把单个层的权重矩阵按维度切分,不同 GPU 各算一部分,最后拼接结果。适合超大层。
流水线并行(Pipeline Parallelism):把模型的不同层放在不同 GPU 上,数据像工厂流水线上的产品一样依次通过。GPU 0 算第 1-12 层,GPU 1 算第 13-24 层……
实际训练中三种策略混合使用。比如用 Megatron-LM 或 DeepSpeed ZeRO 框架,在 2048 张 GPU 上实现 3D 并行:数据并行 × 张量并行 × 流水线并行。
还有一个工程噩梦:训练不稳定。大规模训练中,Loss(损失值)有时会突然飙升——某个 batch 里混入了异常数据,梯度爆炸,或者某些数值溢出。凌晨三点 Loss 突然 spike,你需要在几分钟内决定是回滚到上一个 checkpoint 还是调低学习率继续。一次错误决策,可能浪费几十万美元的算力。这正是 Anthropic 愿意花 75 万美元雇人的原因——这些钱买的是凌晨三点从容应对危机的经验。
预训练结束后,模型已经"读过"了互联网上几乎所有的公开文本。它能流畅地续写文字,但还不会"对话"。你问它"法国的首都是哪里",它可能不回答你的问题,而是续写成"法国的首都是哪里?这是一个经常被问到的问题……"。它学会的是文字的统计规律,但还不知道怎么当一个有用的助手。
让它从"文字接龙机器"变成"有用助手"的过程,叫后训练。
第五步:后训练——从"会说话"到"会帮忙"后训练分两步走。
第一步:监督微调(SFT)
相当于给模型做"示范教学"。准备一大批高质量问答对:
[CODE / LOGIC FLOW]
用户:请用三句话解释光合作用。 助手:植物利用阳光将二氧化碳和水转化为葡萄糖和氧气。这个过程发生在叶绿体中。光合作用是地球上几乎所有生命的基础能量来源。用这些数据继续训练模型,让它学会"别人问你问题时,你应该直接回答,而不是继续编故事"。SFT 数据的质量比数量重要得多——研究表明,几千条精心标注的高质量指令数据,效果可能好过几十万条低质量数据。

第二步:人类反馈强化学习(RLHF)
SFT 之后的模型已经能对话了,但回答可能不够好——太啰嗦、不够安全、偶尔胡说八道。RLHF 的目标就是让模型变得更好、更安全、更诚实。
流程是这样的:先让模型对同一个问题生成多个回答,让人类标注员按"哪个更好"排序。用这些排序数据训练一个奖励模型(Reward Model),它学会了给任何一对(问题,回答)打分。然后,用奖励模型的分数作为奖励信号,通过强化学习算法(通常是 PPO)来优化主模型的生成策略。
Anthropic 自己用的是一套叫 Constitutional AI(宪法 AI) 的方法。核心思路是:不依赖大量人类标注,而是给 AI 一套"宪法"(一组行为准则),让 AI 自己评判和修正自己的回答。这大幅降低了对人类标注员的依赖。
还有一种更简洁的对齐方法叫 DPO(Direct Preference Optimization,直接偏好优化)。它跳过了训练奖励模型这一步,直接用偏好数据优化策略模型。数学更优雅,工程更简单,LLaMA-3 就用了 DPO 作为对齐策略之一。
后训练过程中有个需要时刻警惕的副作用:灾难性遗忘(Catastrophic Forgetting)。模型在对齐过程中可能"忘了"预训练时学到的东西——你使劲训练它礼貌,它可能就变笨了。怎么在对齐和保持能力之间找到平衡,是一门极其精微的调参艺术。
到这一步,一个完整的大语言模型就建好了。但在正式进入推理之前,有一个贯穿整个构建过程的关键理论值得了解。
2020 年,OpenAI 发表论文揭示了一个极其简洁的规律:模型性能只取决于三个变量——参数量(N)、数据量(D)和计算量(C),它们之间存在幂律关系。参数越多、数据越多、算力越多,模型就越好——而且这种变好是可预测的。
这个发现改变了一切。它意味着,只要你有足够的钱和数据,就能按公式预测出你的模型会有多强。这也是过去几年所有大公司疯狂买 GPU 的原因——算力投入和模型能力之间存在确定性的对应关系。英伟达的万亿市值,很大程度上建立在这条曲线之上。
后来的研究(DeepMind 的 Chinchilla 论文)进一步修正:对于给定的计算预算,最优策略不是无脑堆参数,而是让参数量和数据量按特定比例同步增长(大约 20 个 token 对应 1 个参数)。这个发现催生了一系列"计算最优"模型。
第六步:推理——让模型真正开始干活训练好的模型是一个几百 GB 的参数文件。让它在实际应用中高效运行,需要的工程量和训练一样硬核。

自回归生成:大模型生成文字时,是一个 token 一个 token 吐出来的。每生成一个 token,就把它拼到输入后面,再把整个序列喂回模型,预测下一个。这就是为什么模型越长越慢——每多生成一个 token,计算量就大一点。
KV Cache:推理优化中最重要的发明之一。自注意力计算中,前面 token 的 K 和 V 向量在一次生成后就固定不变了。把它们缓存下来,下次只需要计算新 token 的 Q、K、V,不必重复计算整个序列。KV Cache 把推理从 O(n²) 的计算降到了接近 O(n),速度提升可以到几十倍。
量化(Quantization):模型默认用 FP16(16 位浮点数)存储。但很多场景下,把参数压缩到 INT8(8 位整数)甚至 INT4(4 位整数),精度损失很小,显存占用和推理速度都能大幅改善。7B 模型在 FP16 下需要 14GB 显存,量化到 INT4 只要 3.5GB,普通消费级显卡就能跑。
采样策略:模型预测下一个 token 时,输出的是整个词表上的概率分布。怎么选?最简单的是贪心解码——永远选概率最高的,但生成的文字很死板。更常用的方法是温度采样:引入一个 temperature 参数控制随机性。温度越高,输出越多样但也越容易跑偏;温度越低,输出越保守。此外还有 top-k(只在概率最高的 k 个里选)和 top-p / nucleus sampling(只在累积概率超过 p 的 token 里选),都是控制输出质量的常用手段。
回到那个 75 万美元的问题现在回到开头那条新闻。
Anthropic 开出的 75 万美元年薪,买的不是某个单一技能。它买的是一个人能在上面六步的每一步里都做到顶尖:
能设计 tokenization 策略,让中文 token 效率提升 20%能搭建稳定的多头注意力架构,在 80 层深度下训练不崩能管理万亿 token 的数据清洗管道,在去重和过滤之间找到平衡能在凌晨三点 Loss spike 时,15 分钟内做出正确的工程决策能用 Constitutional AI 做对齐,同时避免灾难性遗忘能优化推理引擎,让 200K 上下文的响应延迟降到可接受范围任何一步做到极致,都值这个价。

这篇文章的目的,不是教你拿到那个 offer。是让你在下次打开 ChatGPT、Claude 或者任何一个大模型对话框时,知道那一行行流畅的回答背后,经历了怎样的旅程:文本被切成 token、被嵌入成向量、经过几十层注意力机制的反复打磨、在海量数据上学过万亿种文字组合、再经过人类反馈和宪法约束的精细校准——最终变成你屏幕上那个既聪明又克制的 AI 助手。
大语言模型不是魔法,是一层一层精密堆叠的工程。理解了这些工程细节,你就理解了 AI 时代最值钱的那种能力到底长什么样。
如果你想把这些知识变成实际能力,路径很清晰:先用 Andrej Karpathy 的 nanoGPT(300 行 PyTorch 从零实现一个迷你 GPT)感受整个流程;然后读 Transformer 原始论文,搞懂每一个公式的物理含义;接着学分布式训练框架(DeepSpeed、Megatron-LM),理解大规模并行的工程实现;最后深入对齐领域(RLHF、DPO、Constitutional AI),理解怎么把原始模型变成安全可靠的助手。每一步都有开源资源——论文、代码、教程、社区。
至于那 75 万美元——至少现在你知道,它买的不是"会用 AI",而是"会造 AI"。而这个"会造",就是从这篇文章里拆解的六步开始,一步一个脚印走出来的。