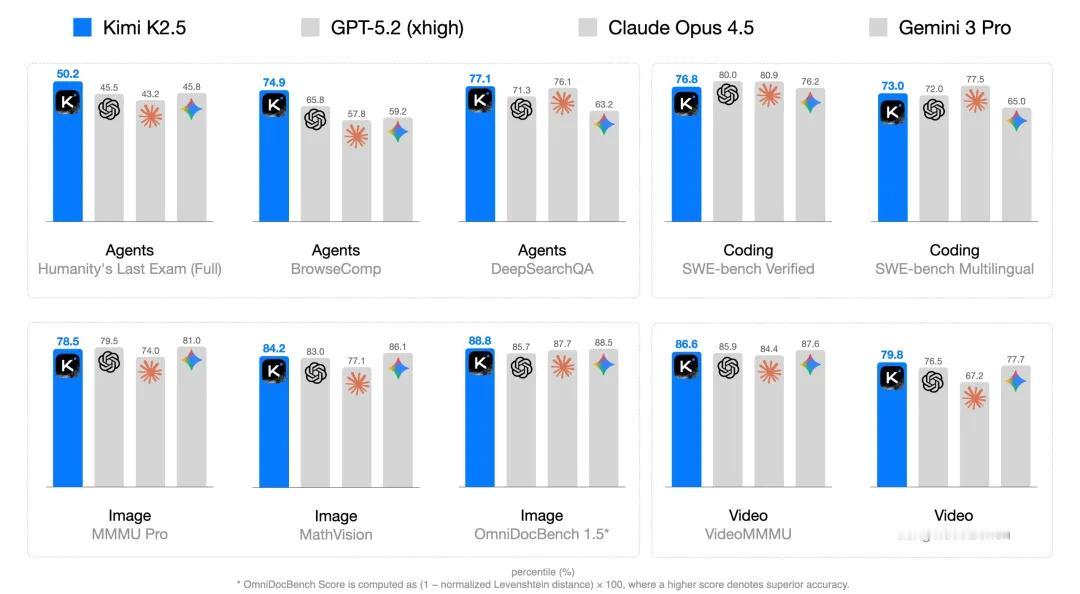
Kimi 官方发布了 Kimi K2.5 技术报告, 介绍了 Kimi K2.5 如何实现文本和视觉能力互相增强,希望帮助更多感兴趣的人了解模型背后的技术。
下面是 Kimi K2.5 实现文本和视觉能力互相增强的核心原理,包括以下几个方面:
1. 联合文本-视觉预训练:
早期视觉融合:在预训练阶段,K2.5 采用早期视觉融合策略,在训练早期就引入视觉数据,并保持恒定比例混合文本和视觉 token,使模型能够自然地发展出平衡的多模态表征。
MoonViT-3D:K2.5 采用 MoonViT-3D 作为视觉编码器,支持可变分辨率图像输入,并通过 NaViT 打包策略将图像划分为 patch 并顺序拼接成 1D 序列,从而能够高效地处理不同分辨率的图像和视频。
2. Zero-Vision SFT:
零视觉激活:K2.5 通过零视觉监督微调(Zero-Vision SFT)技术,仅使用文本数据即可激活视觉能力,避免了传统方法中需要人工标注或提示工程生成视觉数据的局限性。
3. 联合多模态强化学习:
基于结果回报的视觉强化学习:K2.5 在视觉定位与计数、图表与文档理解、视觉关键型 STEM 问题等任务上采用基于结果回报的视觉强化学习,进一步提升视觉能力。
视觉强化学习提升文本性能:研究发现,视觉强化学习不仅可以提升视觉能力,还可以在文本任务上产生可测量的改进,实现了文本和视觉能力的双向增强。
4. Agent 集群:
并行执行:Agent 集群允许模型将复杂任务分解为异构子问题,并由领域专门化的 agent 并发执行,从而实现并行化,进一步提升模型在多个领域的性能。
详细报告可以搜索一下