[CL]《LoSA: Locality Aware Sparse Attention for Block-Wise Diffusion Language Models》H Xi, H Singh, Y Hu, C Hooper… [UC Berkeley] (2026)
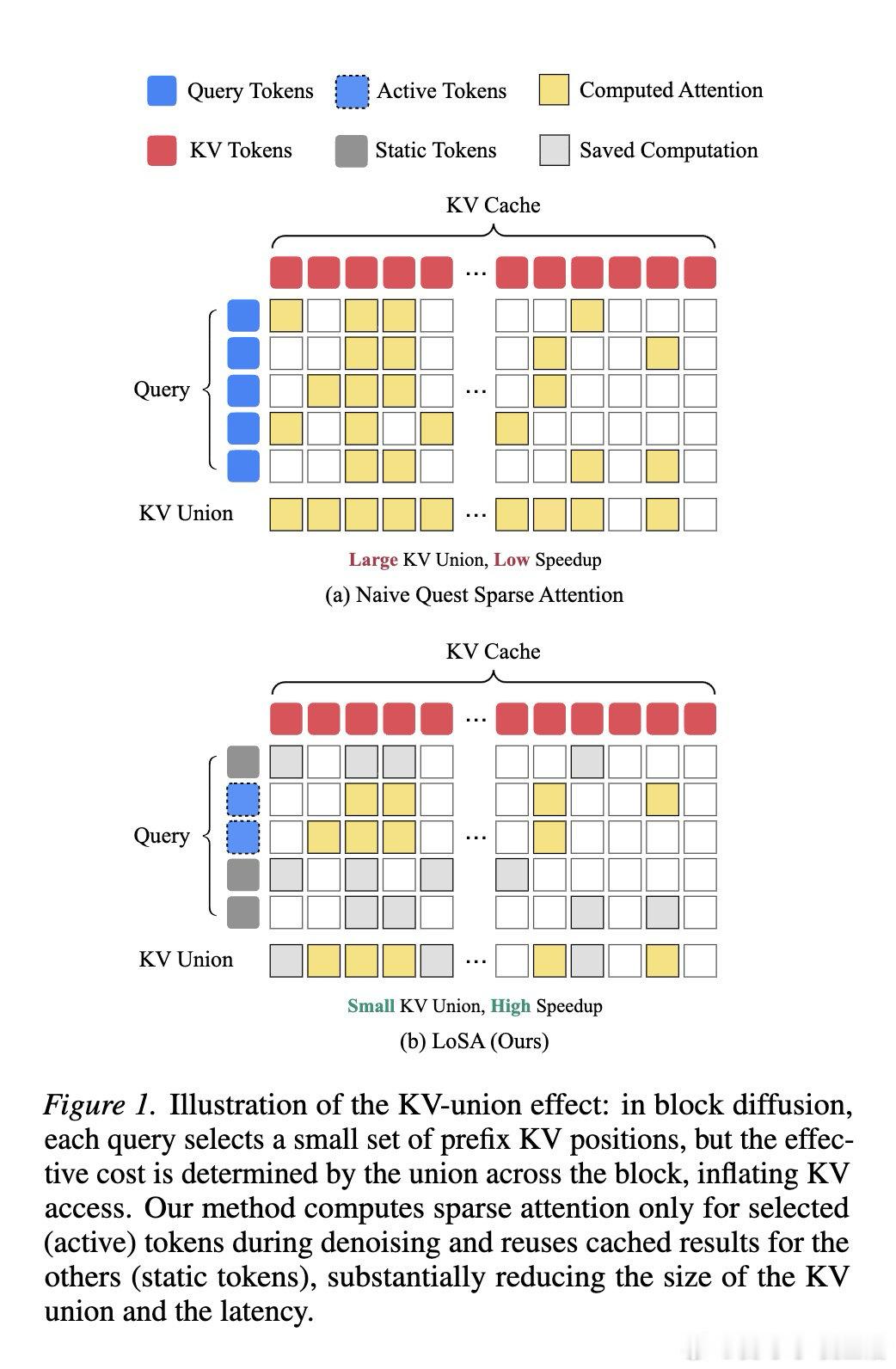
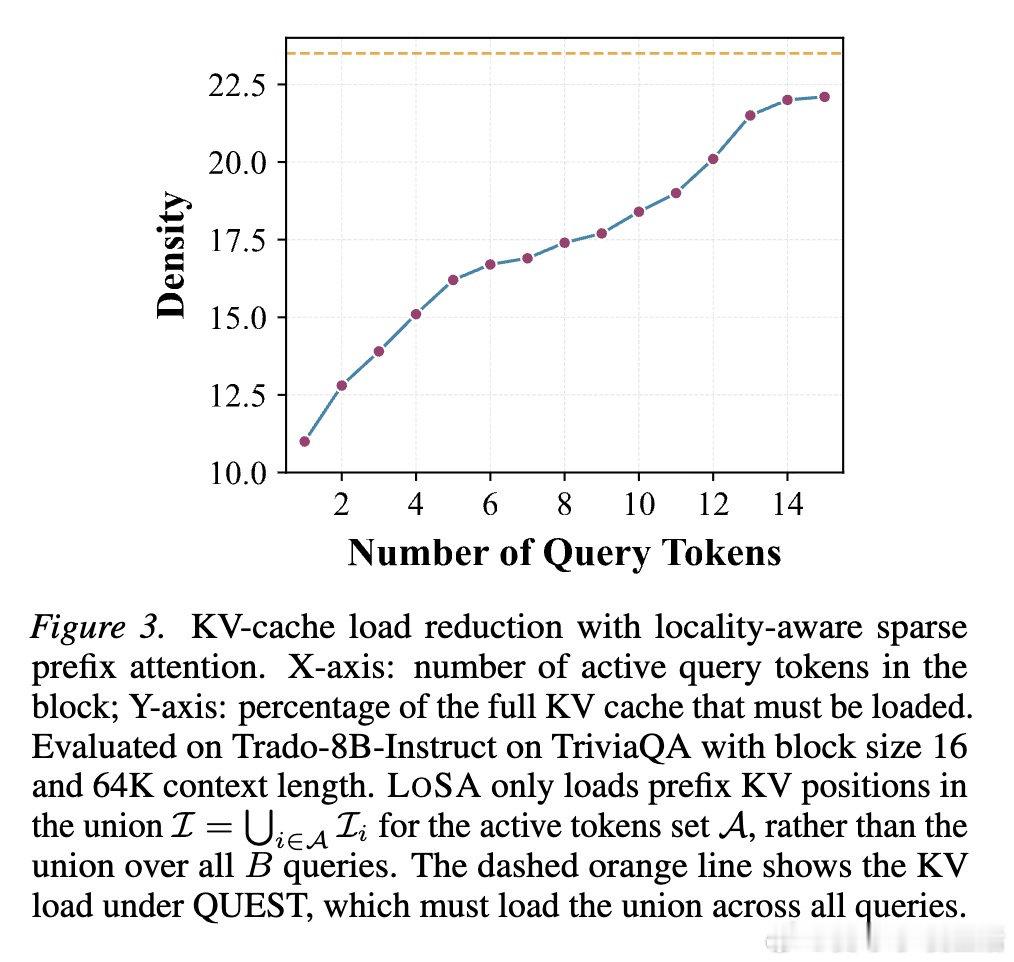
在长文本扩散语言模型推理领域,KV缓存膨胀是一个悬而未决的难题。当一个块中的多个查询各自选择不同的前缀位置时,所有查询所需位置的并集会急剧扩大——块越大,稀疏注意力节省的内存带宽就越少,加速效果被抵消殆尽。
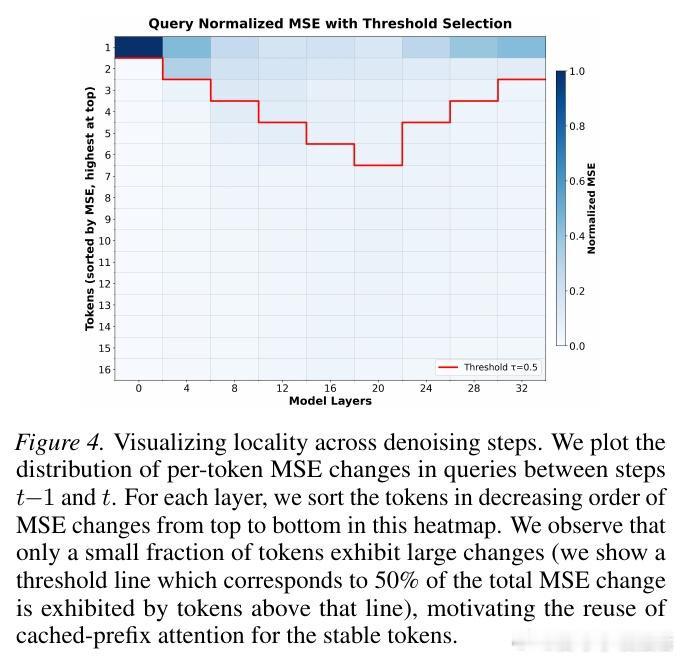
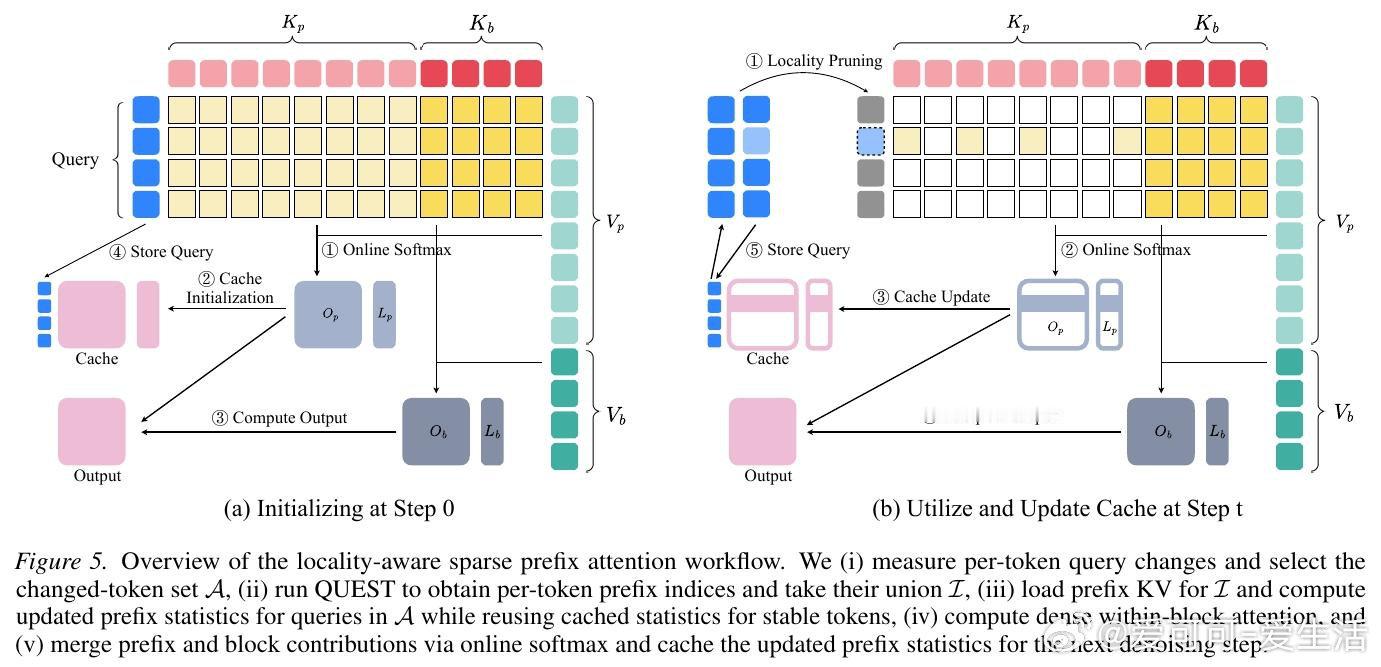
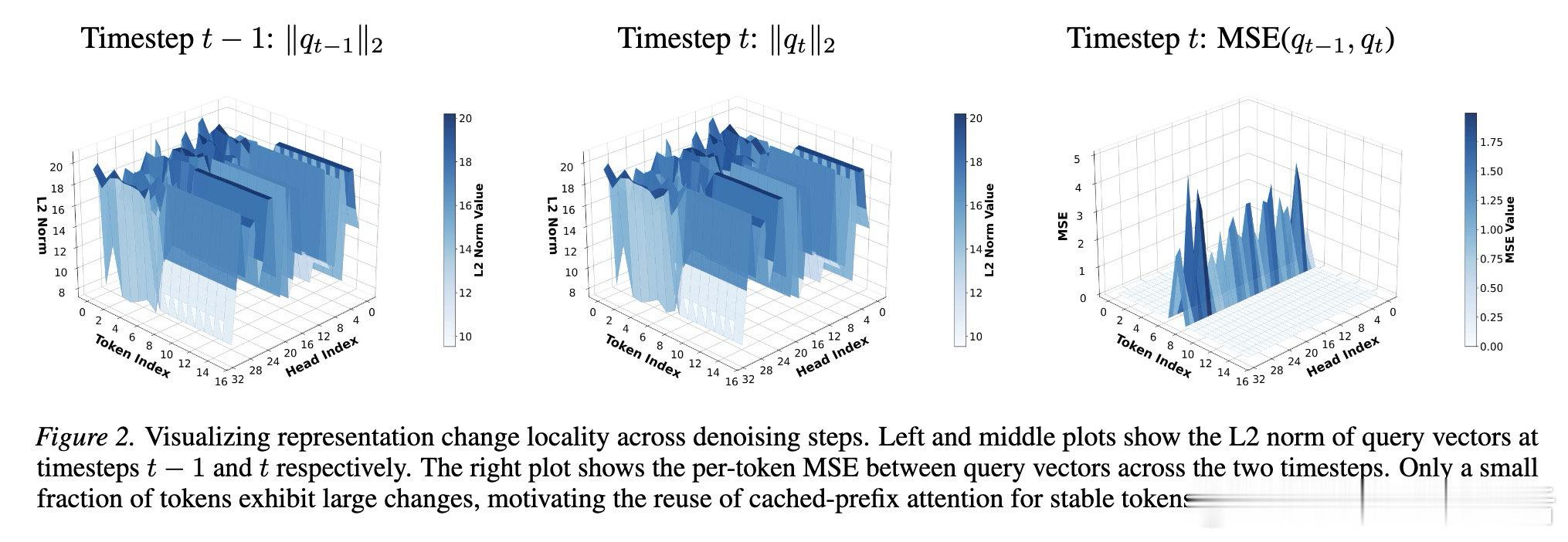
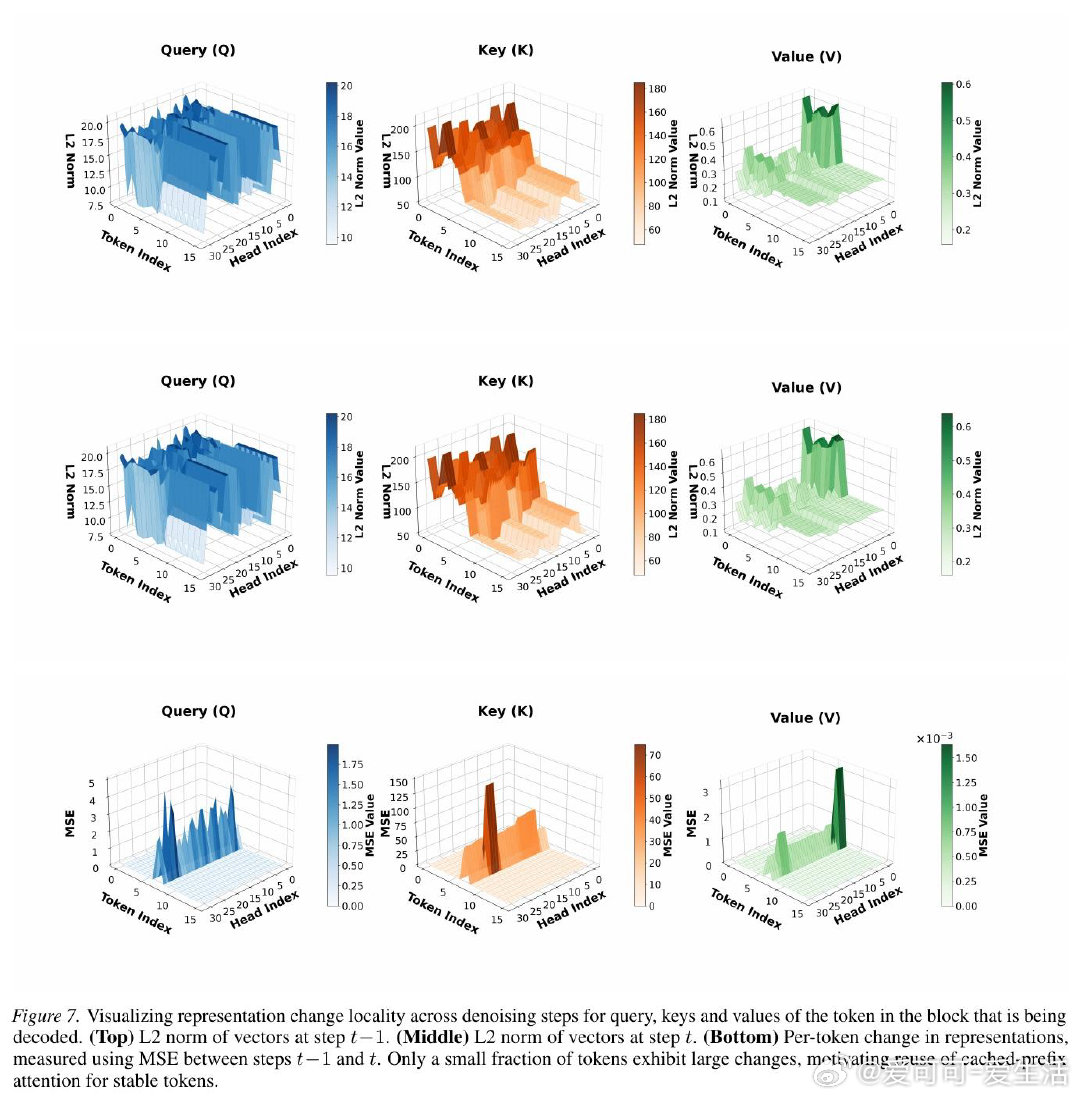
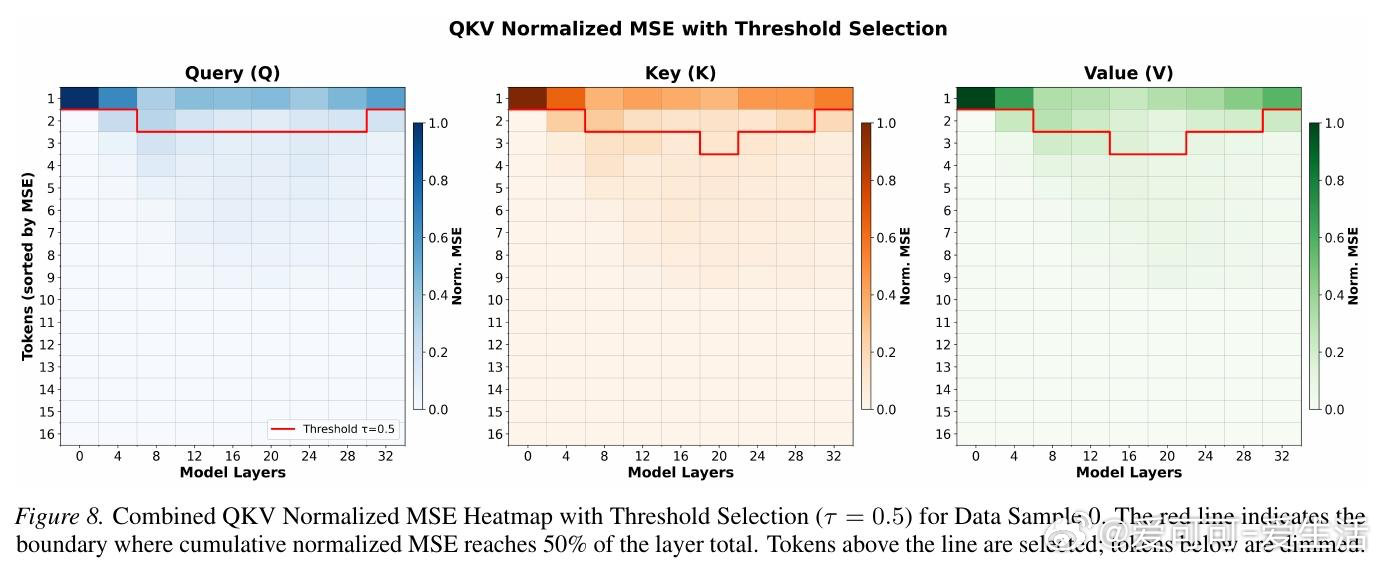
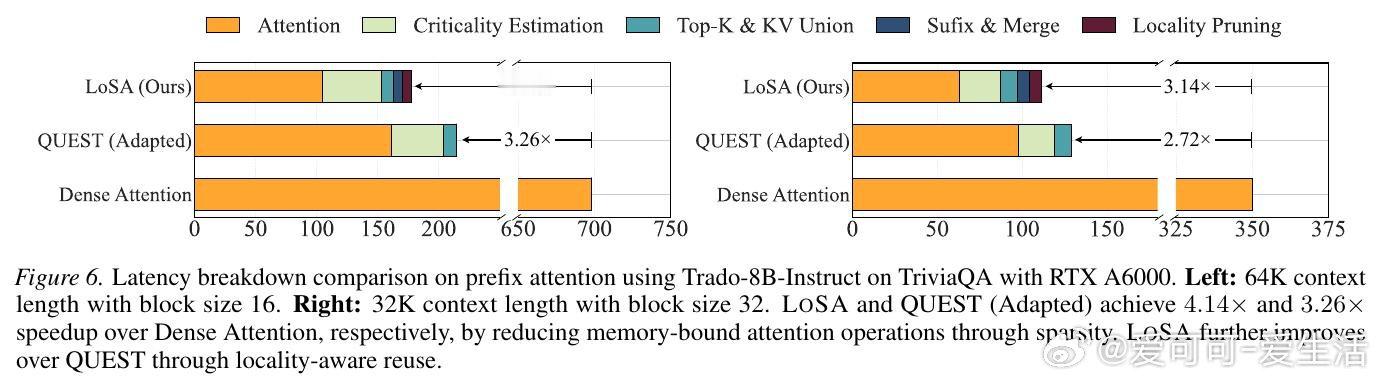
本文的核心洞见是:把扩散去噪步骤之间的表示变化重新看作一种局部性结构。由此,"只对隐状态发生实质变化的活跃词元重新计算稀疏注意力、对稳定词元直接复用上一步缓存的注意力输出"这一关键操作使问题得以解开——参与KV索引选取的查询从整块B个缩减至少数活跃词元,并集随之收缩,内存流量直接下降。
这项工作真正留下的遗产是:为块式扩散模型提供了一条无需修改训练、仅在推理侧即可实现近密集精度与显著加速共存的路径。它为后来者打开的新门是将"步间表示局部性"作为通用信号驱动动态稀疏策略,有望推广至更大批量服务和更多非自回归架构;但尚未跨过的门槛是批量并行场景下的工程整合,以及在块首次去噪时不可避免的密集注意力初始化开销。
arxiv.org/abs/2604.12056
机器学习 人工智能 论文 AI创造营