[CL]《Continuous Knowledge Metabolism: Generating Scientific Hypotheses from Evolving Literature》J Tao, Y Wang, X Liu, M Yang [Central University of Finance and Economics & Beijing Institute of Technology & TsingyuAI] (2026)
在科学假设生成领域,如何让机器真正"追踪知识演化"而非仅仅处理静态文献快照,是一个悬而未决的难题。过去的方法将文献视为一次性全量输入,本质原因是忽略了知识变化的时序结构——而恰恰是那些"变化本身",而非变化后的状态,才是科学洞见的真正触发器。
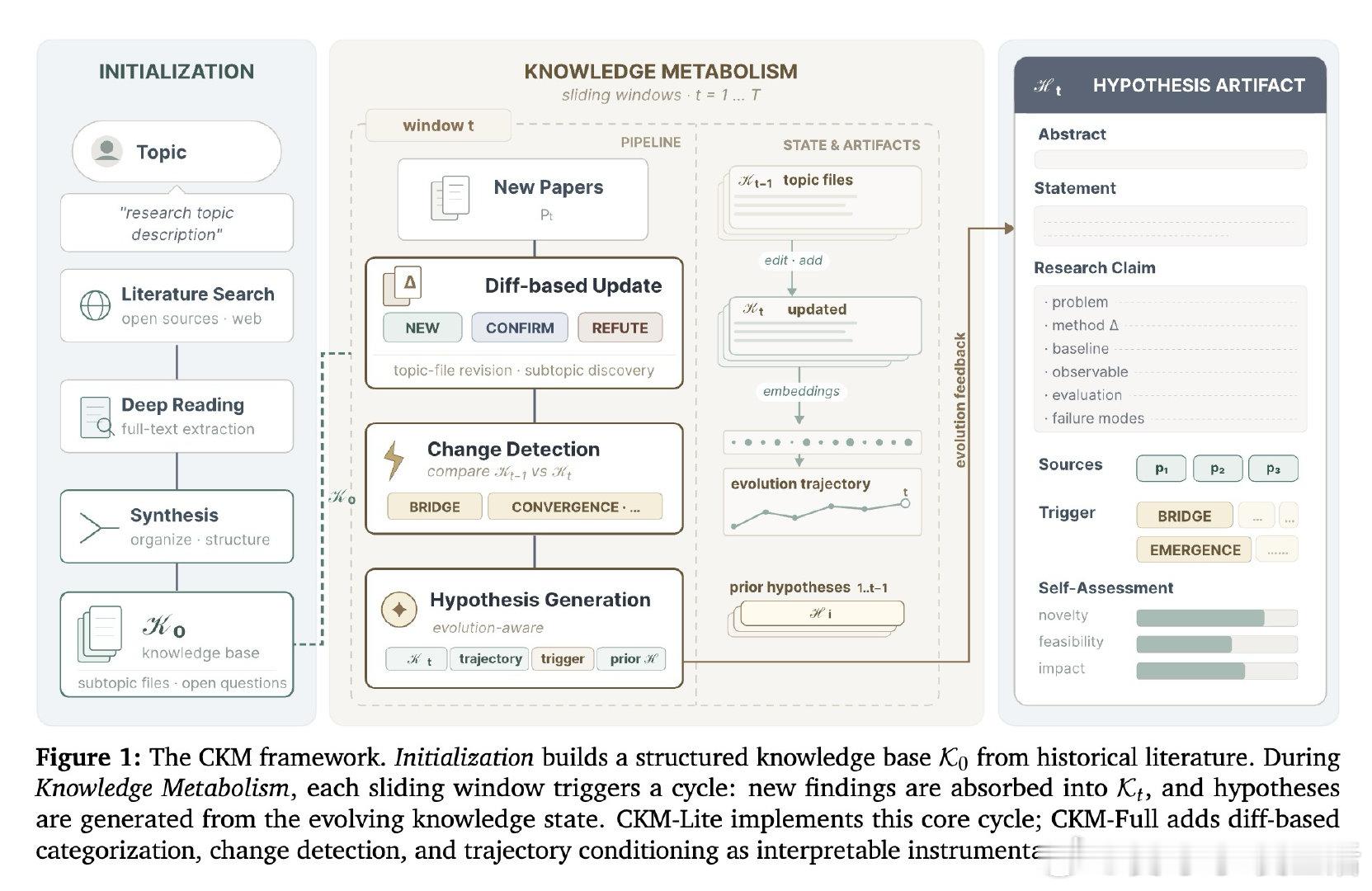
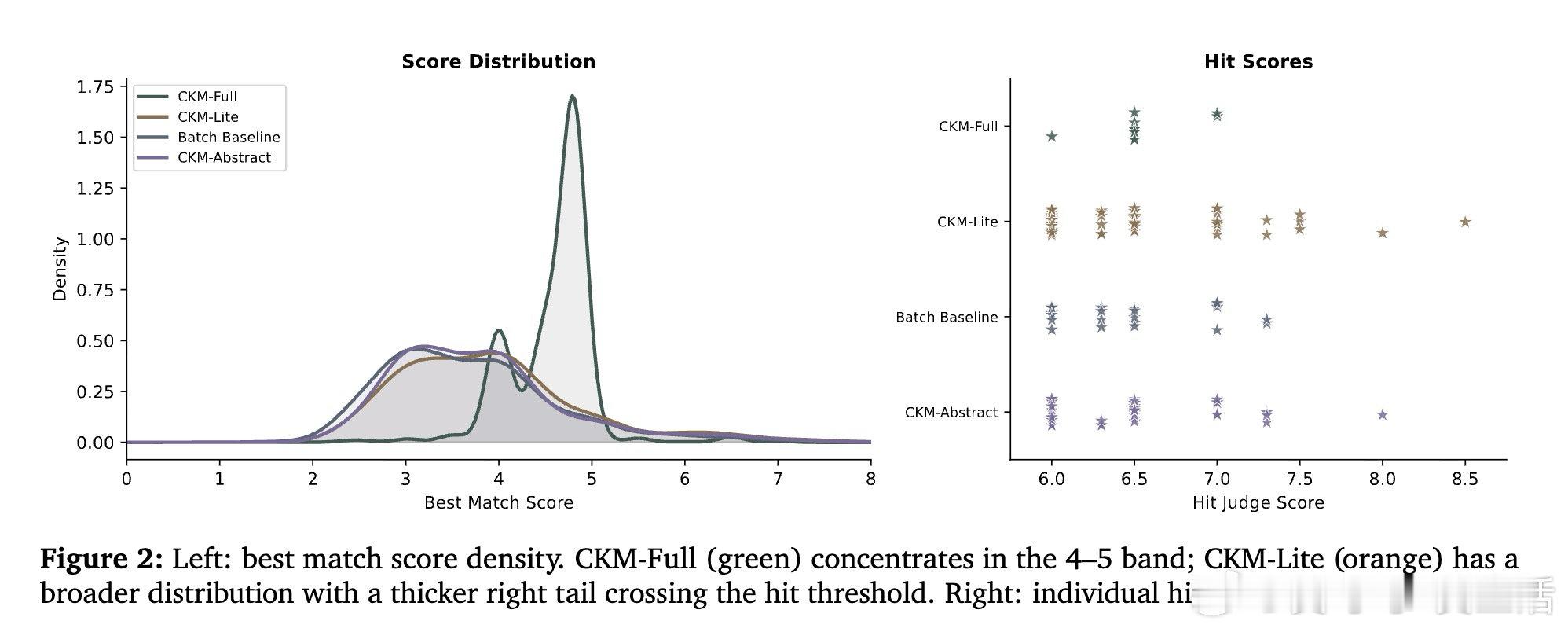
本文的核心洞见是:把文献处理从"批量检索"重新看作"持续代谢"。由此,以滑动时间窗口驱动的增量知识更新这一关键操作使问题得以解开——每一轮新论文不是被堆入一个静态知识库,而是被分类为"新发现、确认、或矛盾",并触发有针对性的假设生成。
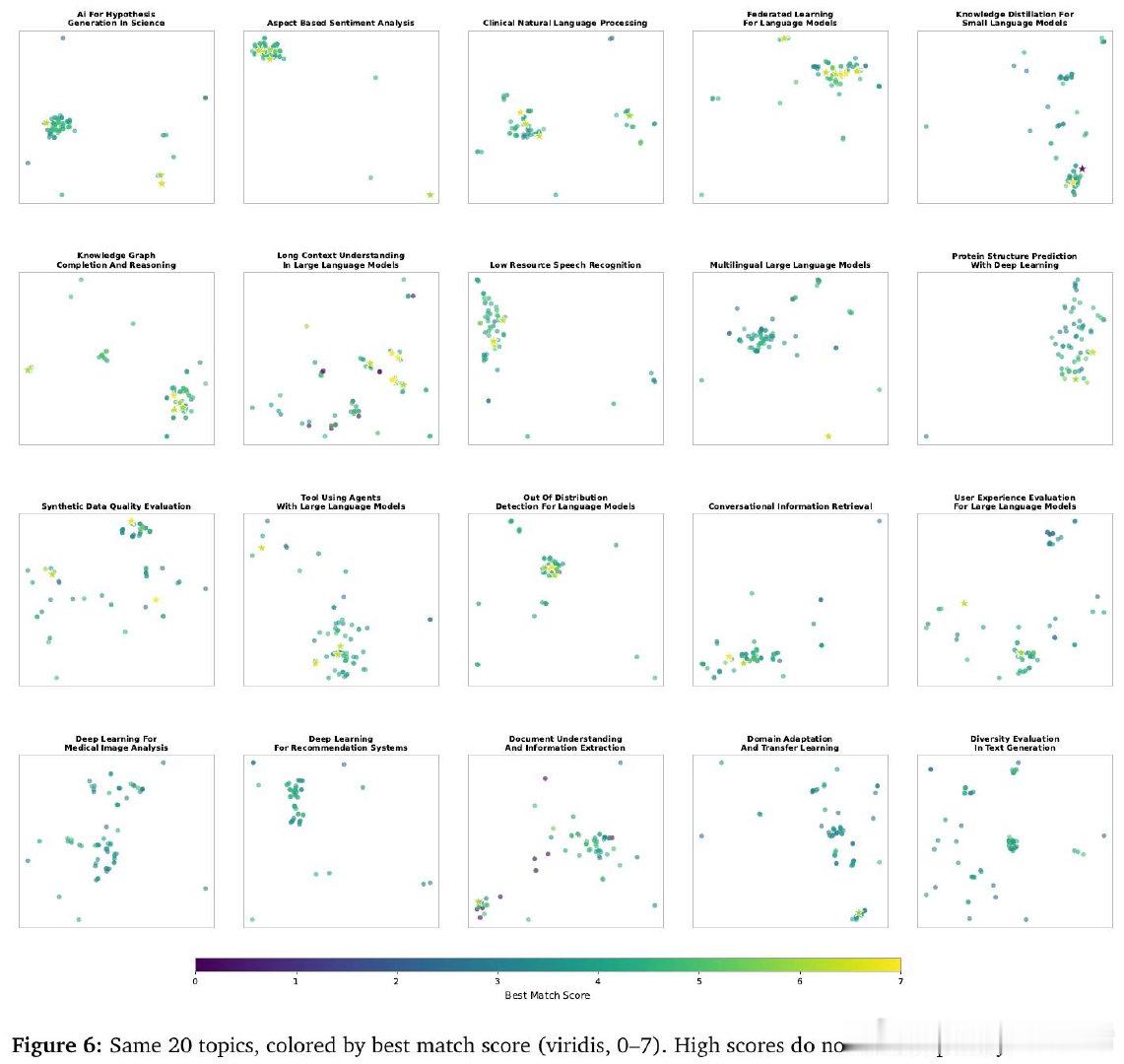
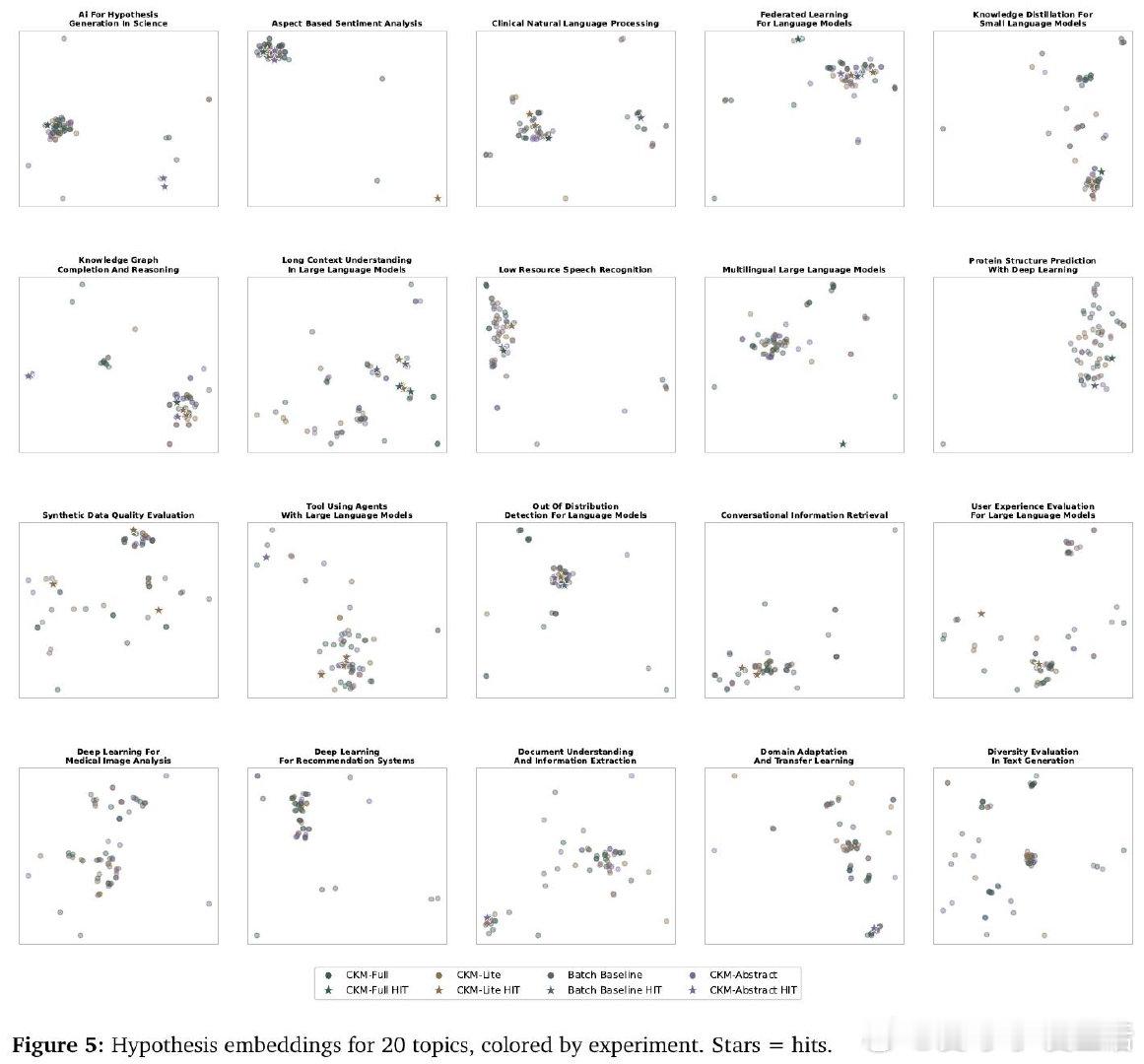
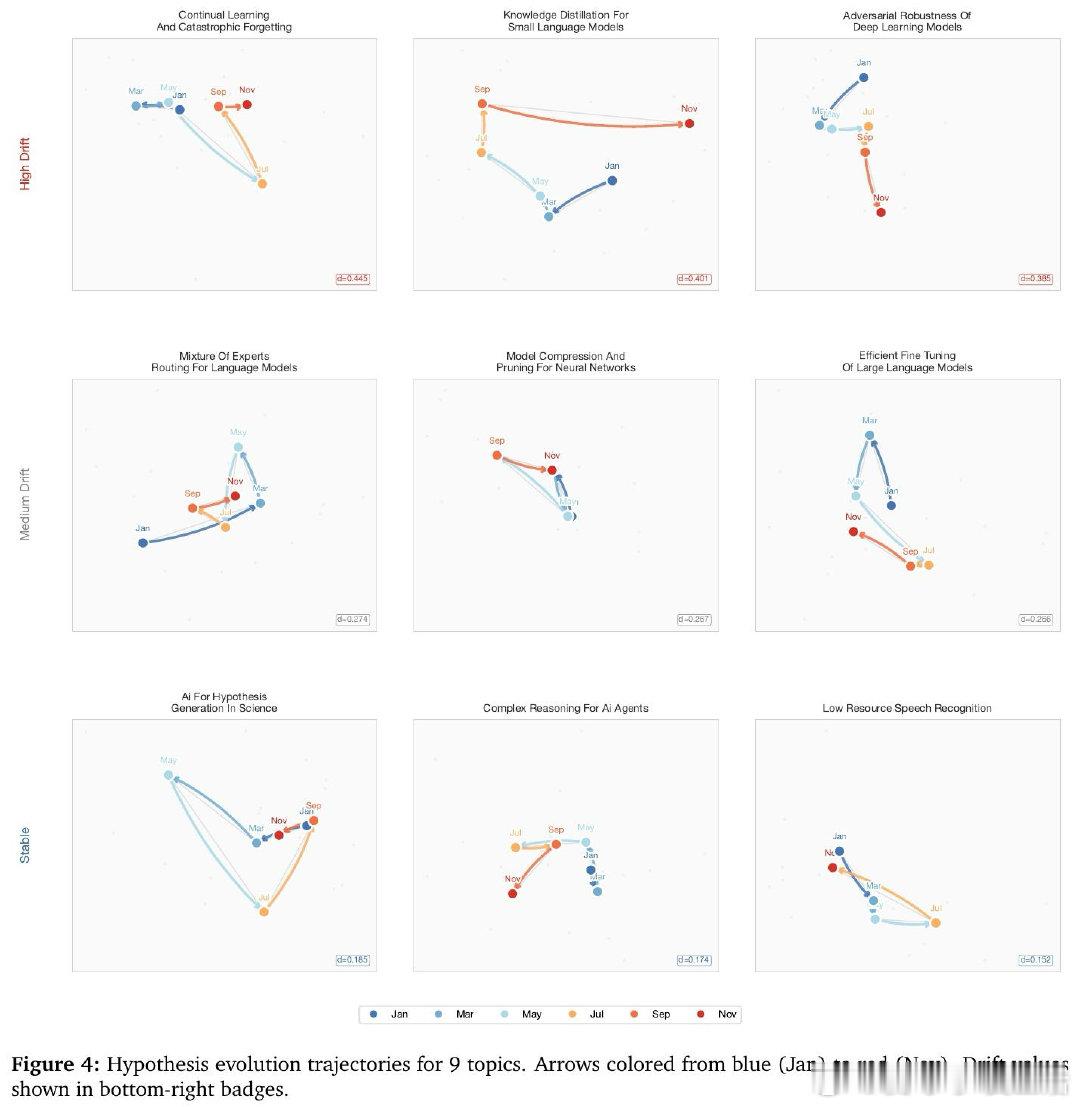
这项工作真正留下的遗产是:证明了处理文献的方式(而非仅仅处理量)会系统性地改变所生成假设的性质。它为后来者打开的新门是:将知识变化类型(收敛、矛盾、桥接)作为生成系统的调度信号,而非背景噪声。但尚未跨过的门槛是:所有质量评估仍依赖LLM裁判而非领域专家,覆盖率与原创性之间的权衡能否在实际科研场景中被有效利用,也尚无答案。
arxiv.org/abs/2604.12243
机器学习 人工智能 论文 AI创造营