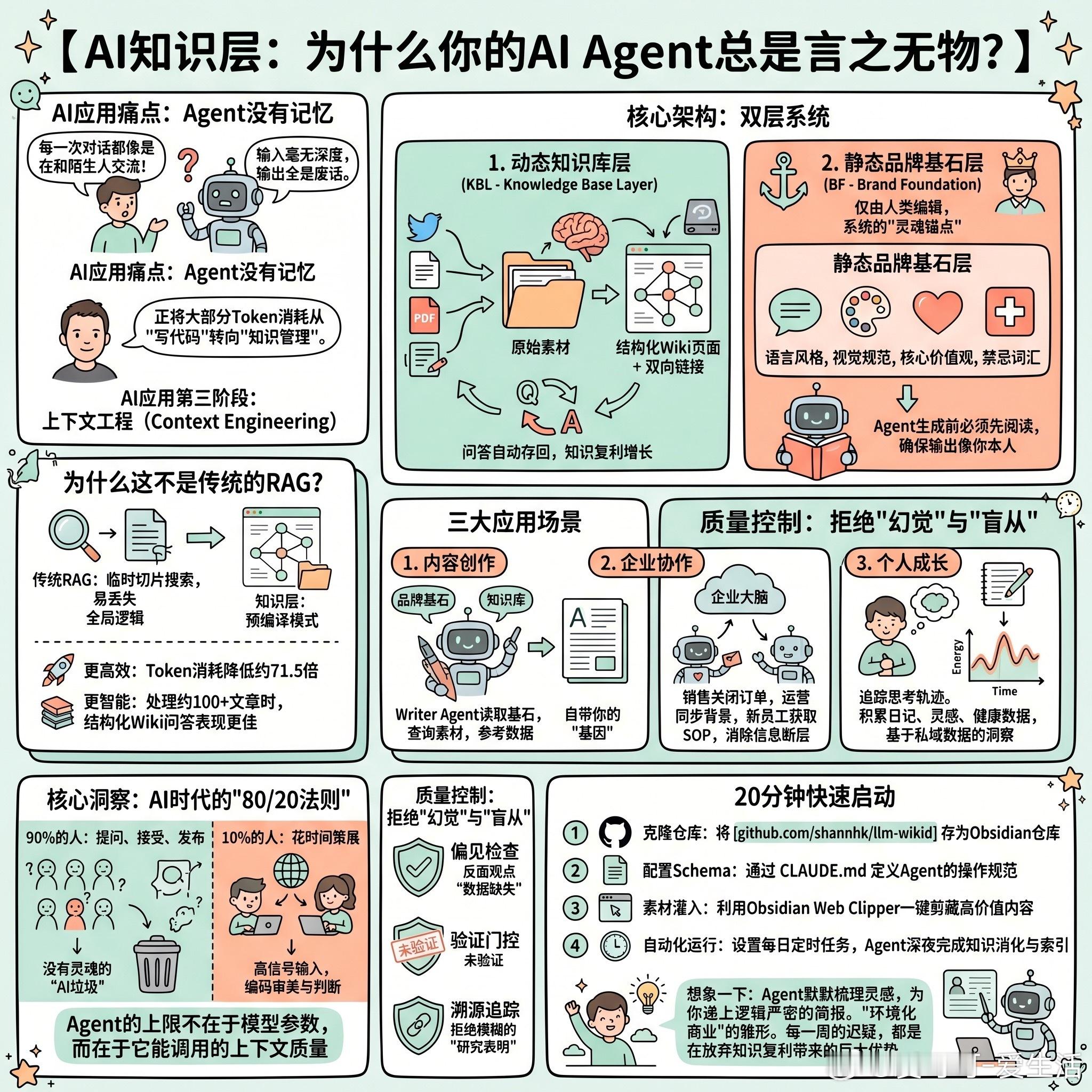
【AI知识层:为什么你的AI Agent总是言之无物?】
目前的AI应用存在一个普遍痛点:Agent没有记忆。每一次对话都像是在和陌生人交流,你不得不反复解释背景、品牌调性、业务逻辑。结果就是:输入毫无深度,输出全是废话。
Andrej Karpathy最近提到,他正将大部分Token消耗从“写代码”转向“知识管理”。这标志着AI应用进入了第三阶段:上下文工程(Context Engineering)。
+ 核心架构:双层系统
要让AI真正“懂你”,需要构建一套位于你与Agent之间的基础设施——AI知识层(AI Knowledge Layer)。它由两个核心部分组成:
1. 动态知识库层 (KBL - Knowledge Base Layer): 这是Agent的“外挂大脑”。你只需将推文、文章、PDF、会议纪要等原始素材丢进文件夹,Agent会自动读取、分类、提炼结构化Wiki页面,并建立双向链接。最关键的是,你提出的每一个问题和得到的答案都会被自动存回Wiki,实现知识的复利增长。2. 静态品牌基石层 (BF - Brand Foundation): 这是系统的“灵魂锚点”,仅由人类编辑。它包含你的语言风格、视觉规范、核心价值观及禁忌词汇。Agent在生成内容前必须先阅读这一层,确保输出永远像你本人,而非冰冷的算法。
+ 为什么这不是传统的RAG?
传统的RAG(检索增强生成)在查询时才临时切片搜索,容易丢失全局逻辑。而“知识层”采用预编译模式:- 更高效:相比直接搜索原始文件,Token消耗降低了约71.5倍。- 更智能:在处理约100篇以上文章时,这种结构化Wiki的问答表现远超普通RAG。
+ 核心洞察:AI时代的“80/20法则”
大多数人宁愿忍受平庸的AI输出,也不愿花20分钟搭建系统。- 90%的人:提问、接受、发布。产出的是没有灵魂的“AI垃圾”。- 10%的人:花时间策展高信号输入,编码自己的审美与判断。
Agent的上限不在于模型参数,而在于它能调用的上下文质量。
+ 三大应用场景
1. 内容创作:Writer Agent读取“品牌基石”确保语气,查询“知识库”获取素材,参考“表现数据”选择格式。这样产出的内容自带你的“基因”。2. 企业协作:建立“企业大脑”。销售Agent关闭订单后,运营Agent自动同步背景;新员工接入Agent即可获取公司沉淀多年的SOP,消除信息断层。3. 个人成长:追踪你的思考轨迹。当系统积累了你的日记、灵感和健康数据后,你可以问它:“我上个季度的精力波动有什么规律?”这种基于私域数据的洞察,是任何通用大模型无法提供的。
+ 质量控制:拒绝“幻觉”与“盲从”
为了防止系统变成一堆废话,必须引入硬性约束:- 偏见检查:强制要求Agent在每个Wiki页面加入“反面观点”和“数据缺失”部分。- 验证门控:所有AI生成的页面默认为“未验证”,必须经由人类审核。- 溯源追踪:每一条结论必须链接到具体的原始素材,拒绝模糊的“研究表明”。
+ 20分钟快速启动
基于开源项目 LLM Wikid,你可以立即构建自己的第二大脑:1. 克隆仓库:将 [github.com/shannhk/llm-wikid] 存为Obsidian仓库。2. 配置Schema:通过 `CLAUDE.md` 定义Agent的操作规范。3. 素材灌入:利用Obsidian Web Clipper一键剪藏高价值内容。4. 自动化运行:设置每日定时任务,让Agent在深夜自动完成知识的消化与索引。
想象一下,你每天随手剪藏的灵感,在深夜被Agent默默梳理成网。当你第二天醒来,你的AI助手不仅记得你去年写过的观点,还能结合你昨晚刚看到的论文,为你递上一份逻辑严密的简报。这就是“环境化商业(Ambient Business)”的雏形。
在这个“Vibe Coding”降低了开发门槛的时代,分发能力和知识深度成了最后的护城河。每一周的迟疑,都是在放弃知识复利带来的巨大优势。
x.com/shannhk/status/2044111115878326444