Sebastian Raschka的新长篇博文:LLM 架构的近期进展:KV Sharing、mHC 与 Compressed Attention---- 从 Gemma 4 到 DeepSeek V4:新的开放权重 LLM 如何降低长上下文成本地址:magazine.sebastianraschka.com/p/recent-developments-in-llm-architectures
“最让我注意到的一点是,新一代架构越来越关注长上下文效率。
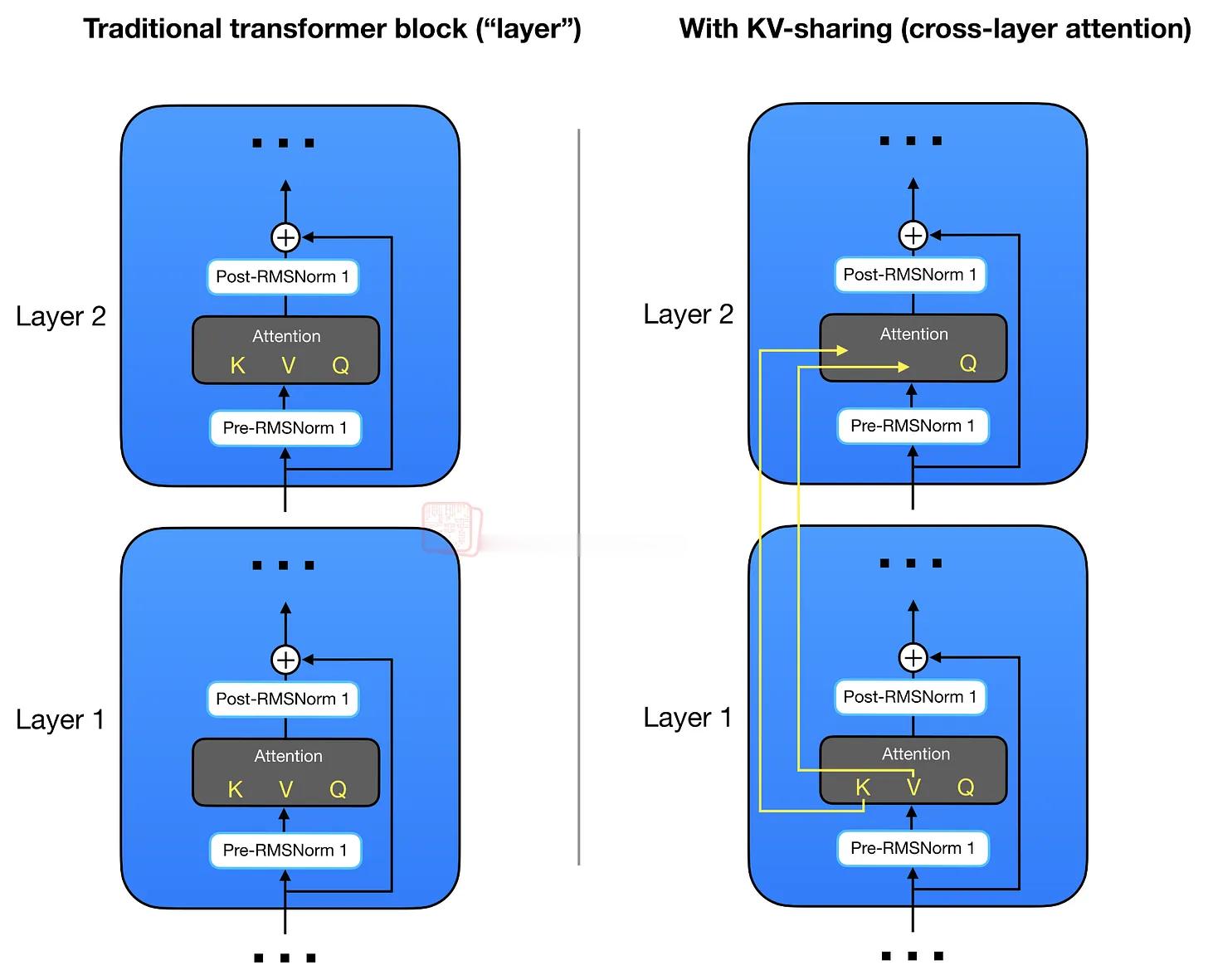
随着 reasoning models 和 agent workflows 保留更多 token,并且保留更长时间,KV cache 的大小、memory traffic 和 attention cost 很快会成为主要限制因素。因此,LLM 开发者正在加入越来越多架构技巧,以降低这些成本。
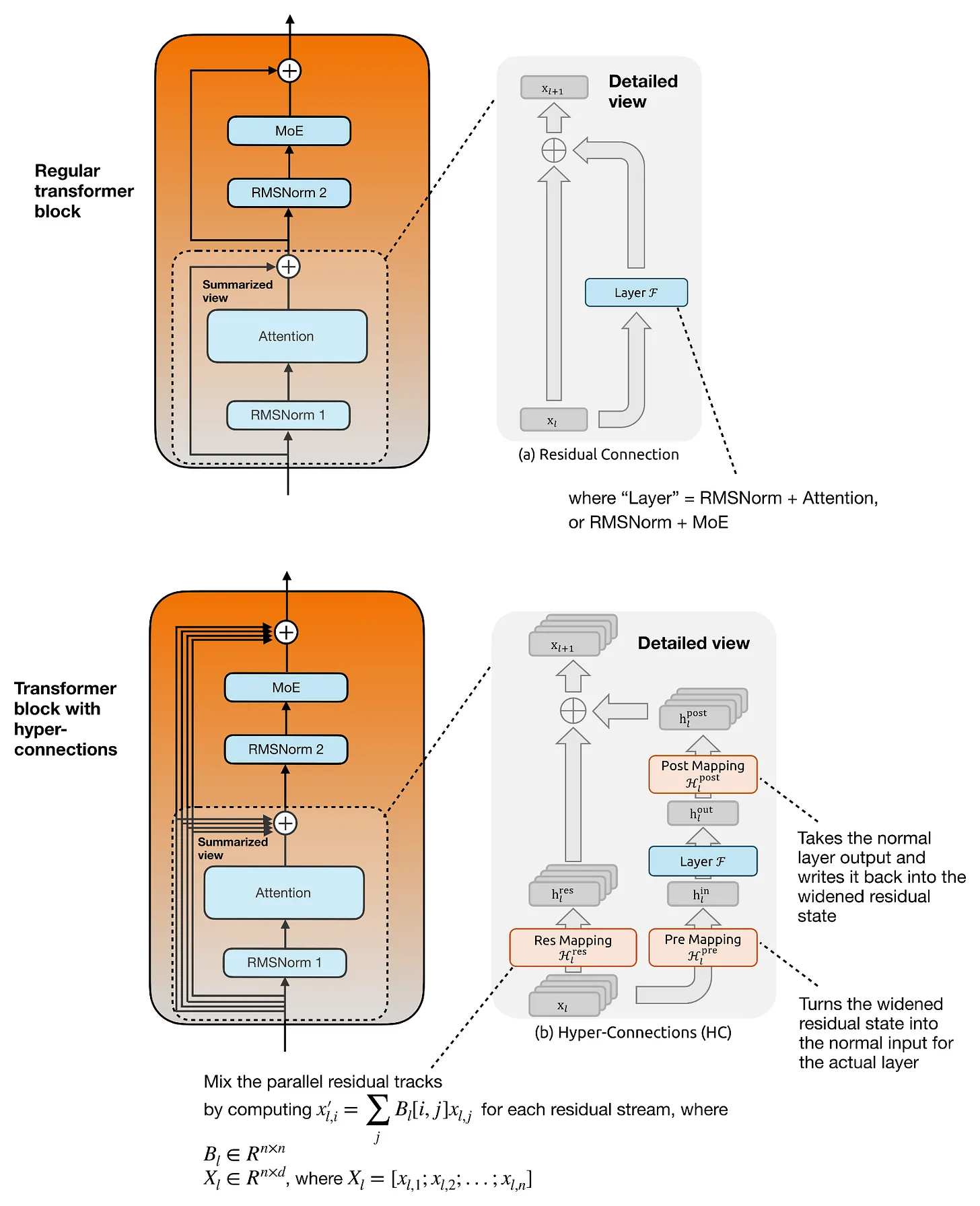
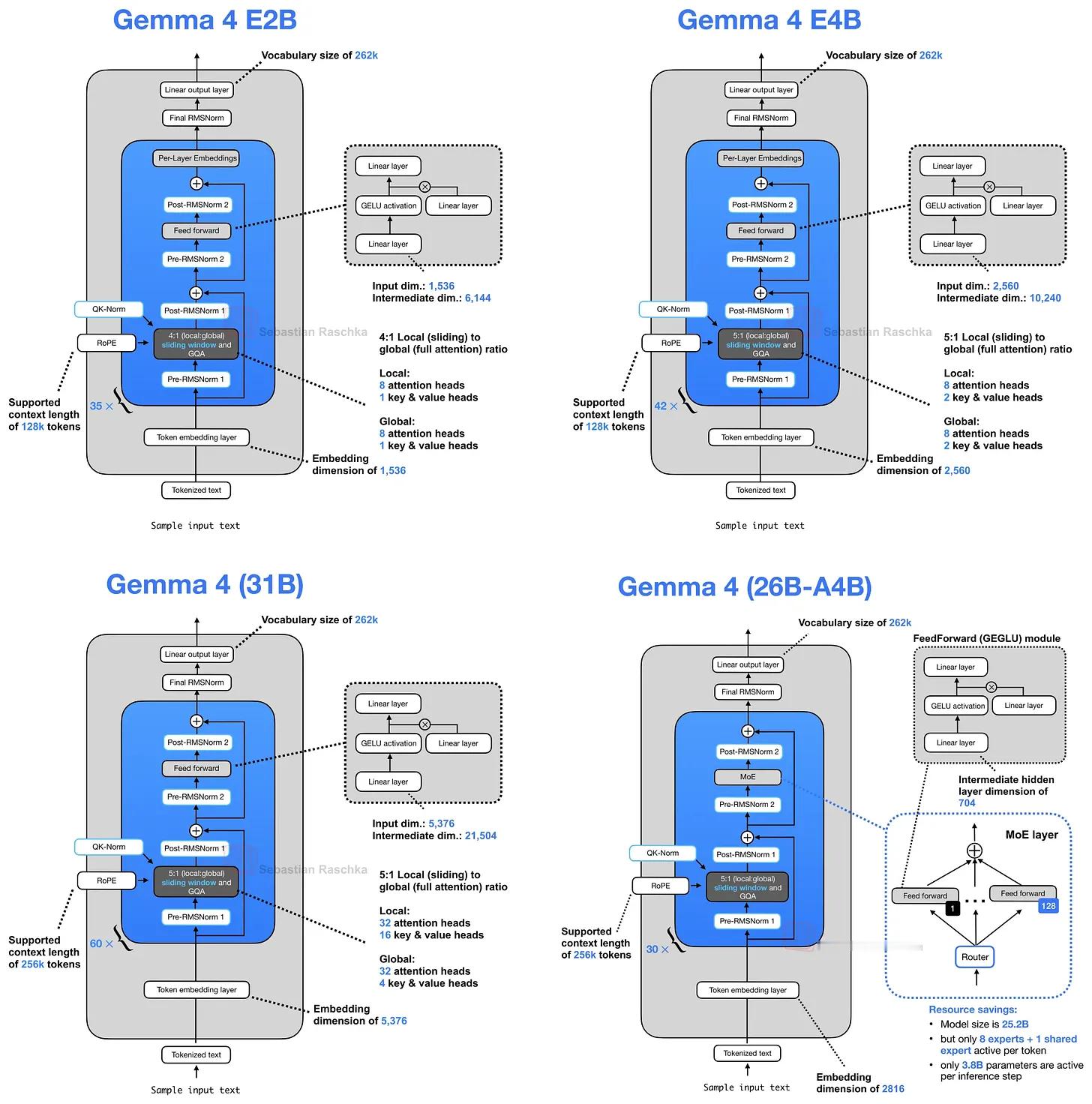
我想重点讨论的几个例子包括:Gemma 4 中的 KV sharing 和 per-layer embeddings,Laguna XS.2 中的 layer-wise attention budgeting,ZAYA1-8B 中的 compressed convolutional attention,以及 DeepSeek V4 中的 mHC 和 compressed attention。
这些变化中,大多数在我的架构图里看起来只是小改动,但其中一些其实是相当精巧的设计变化,值得更详细地讨论。”
AI创造营How I AI