[LG]《Multi-Mixer Models: Flexible Sequence Modeling with Shared Representations》K Y. Li, A Trockman, A T Suresh, Z Sun [CMU & Google Research] (2026)
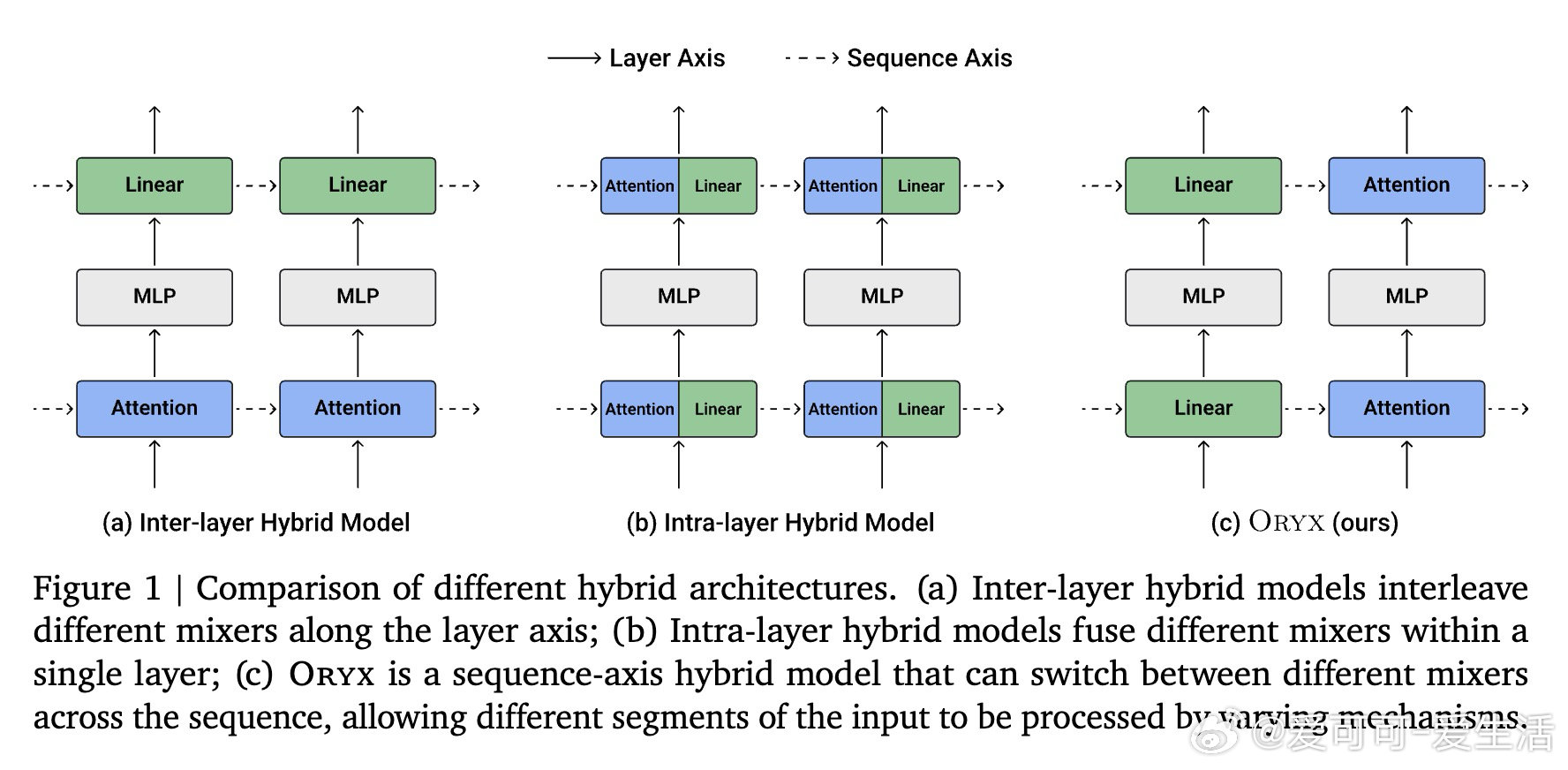
在序列建模中,注意力强但贵,线性递归省但弱于检索。过去混合架构把模块固定在层内或层间,本质上仍无法按序列片段切换算力。
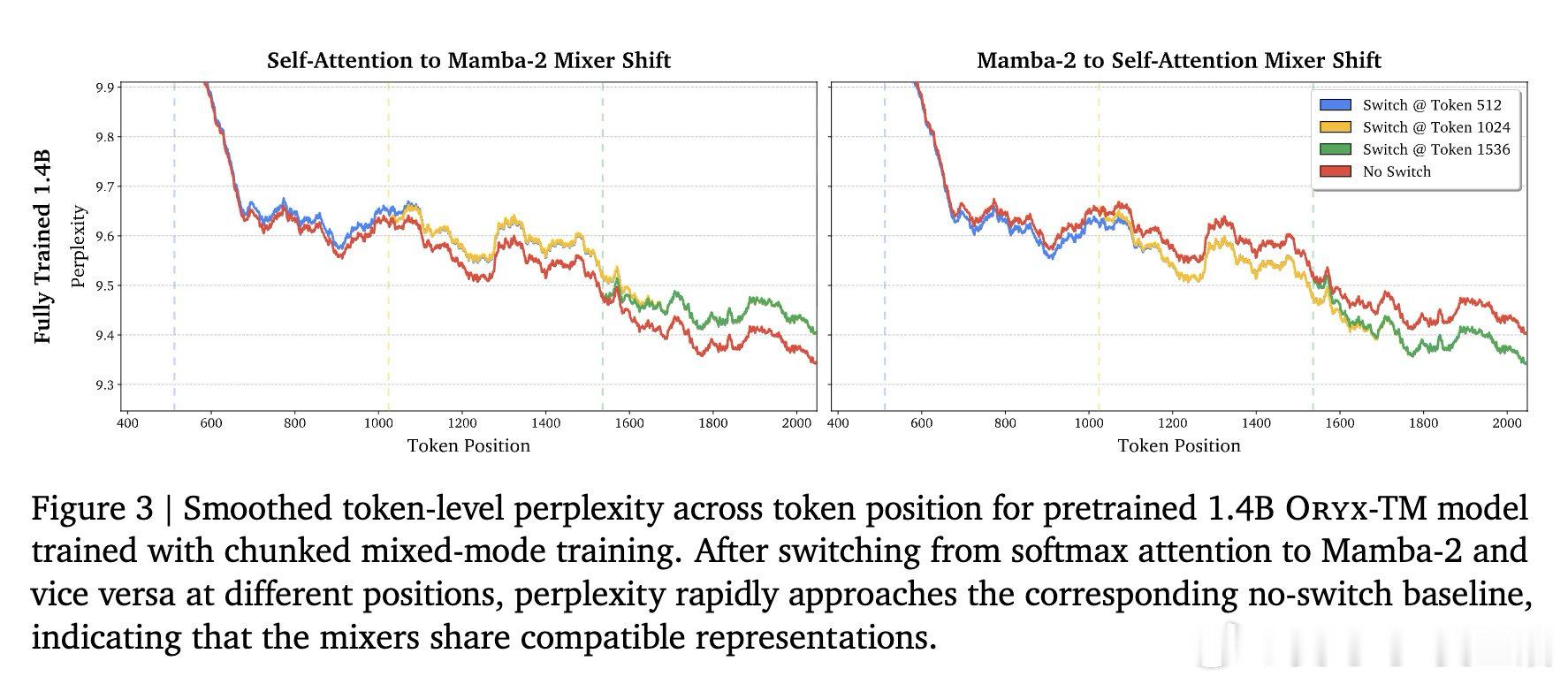
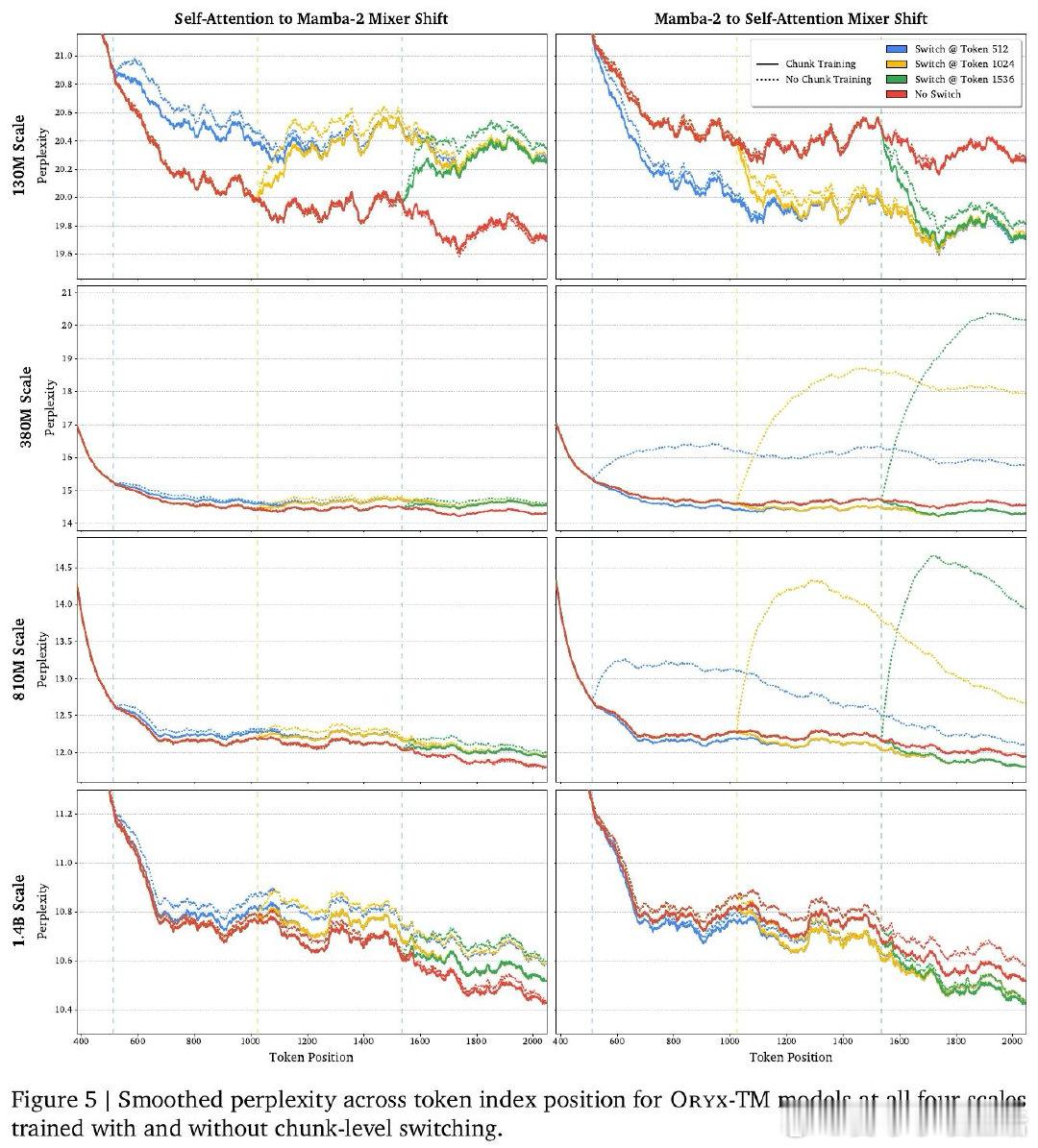
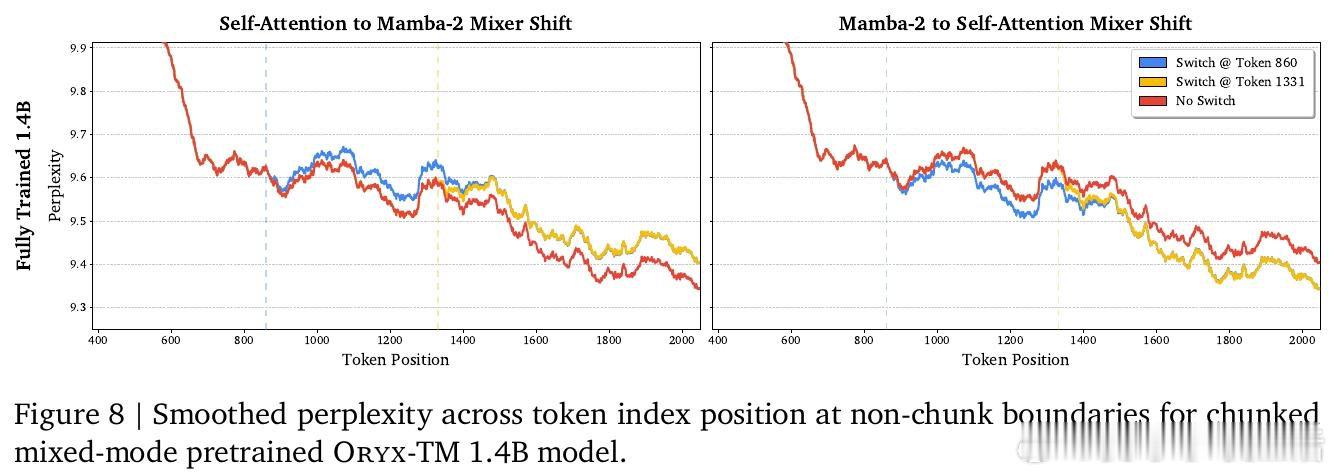
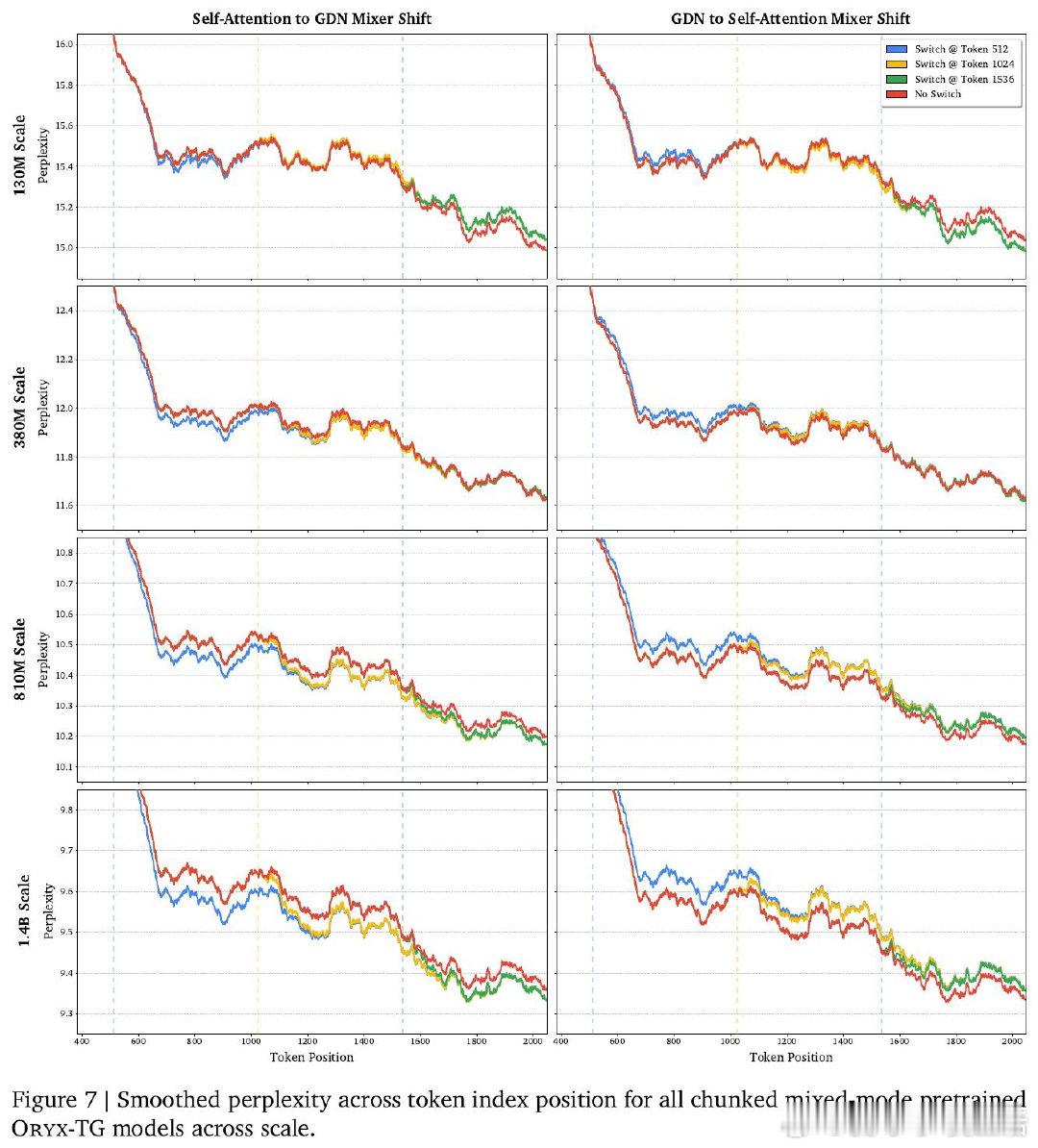
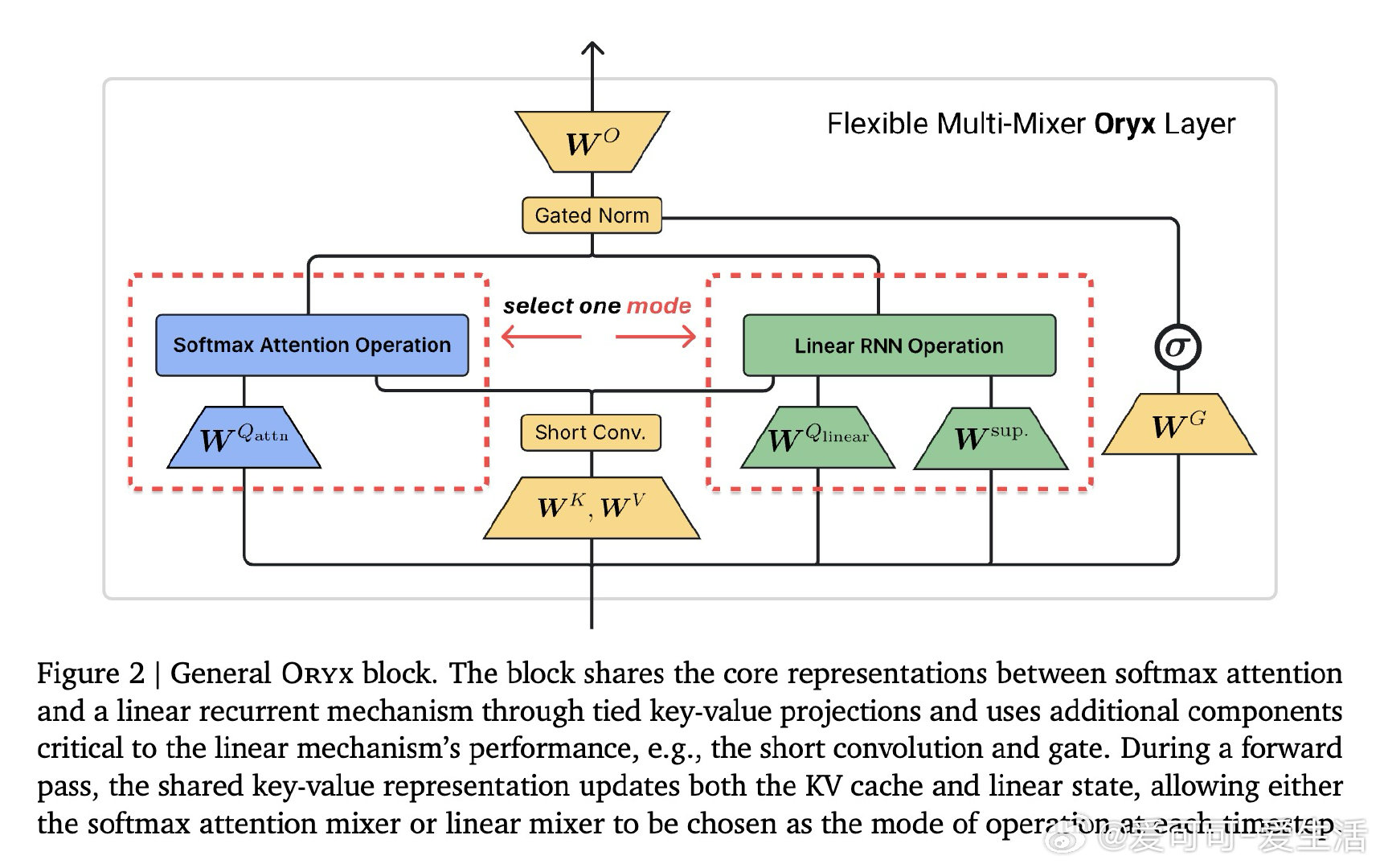
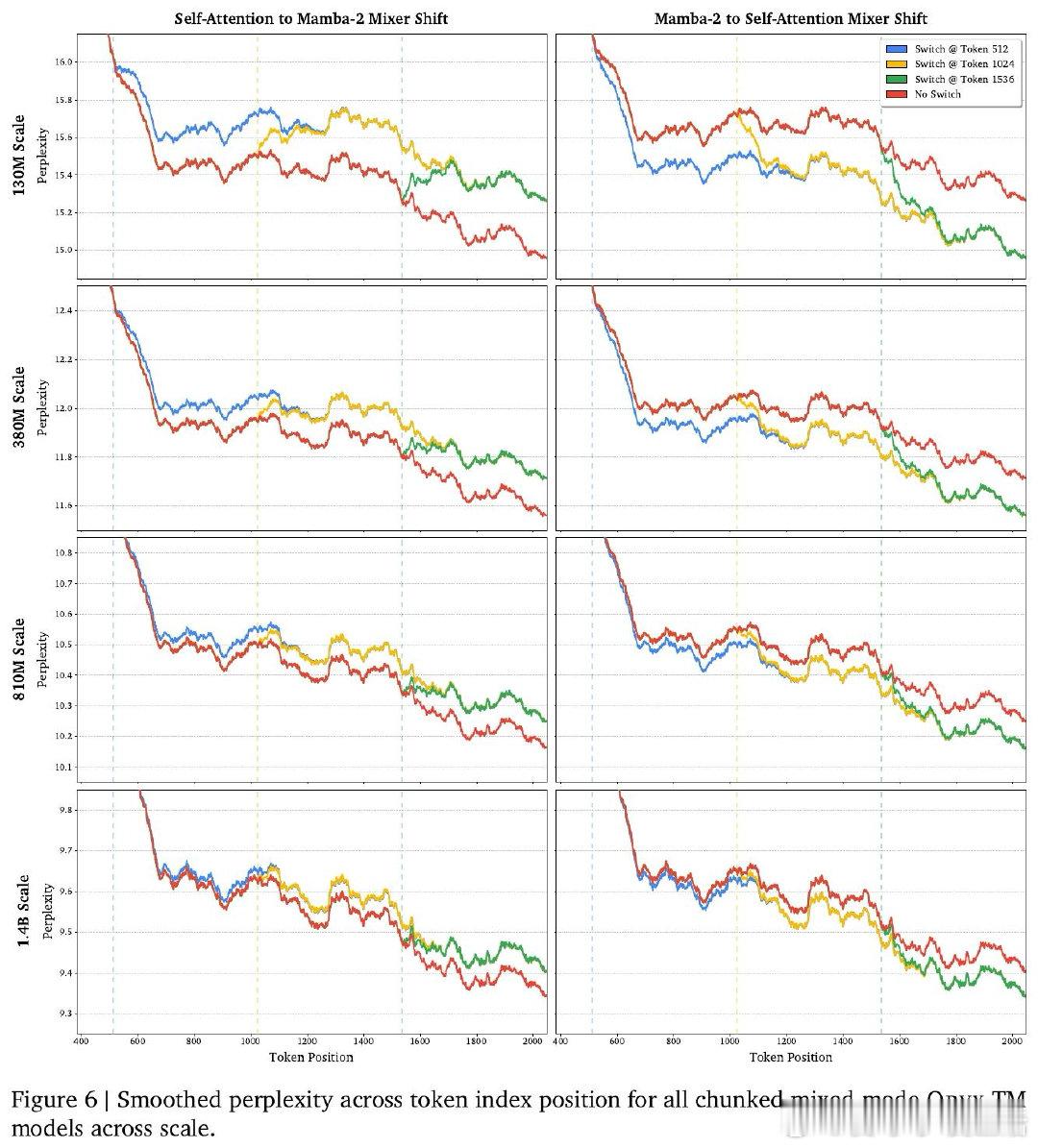
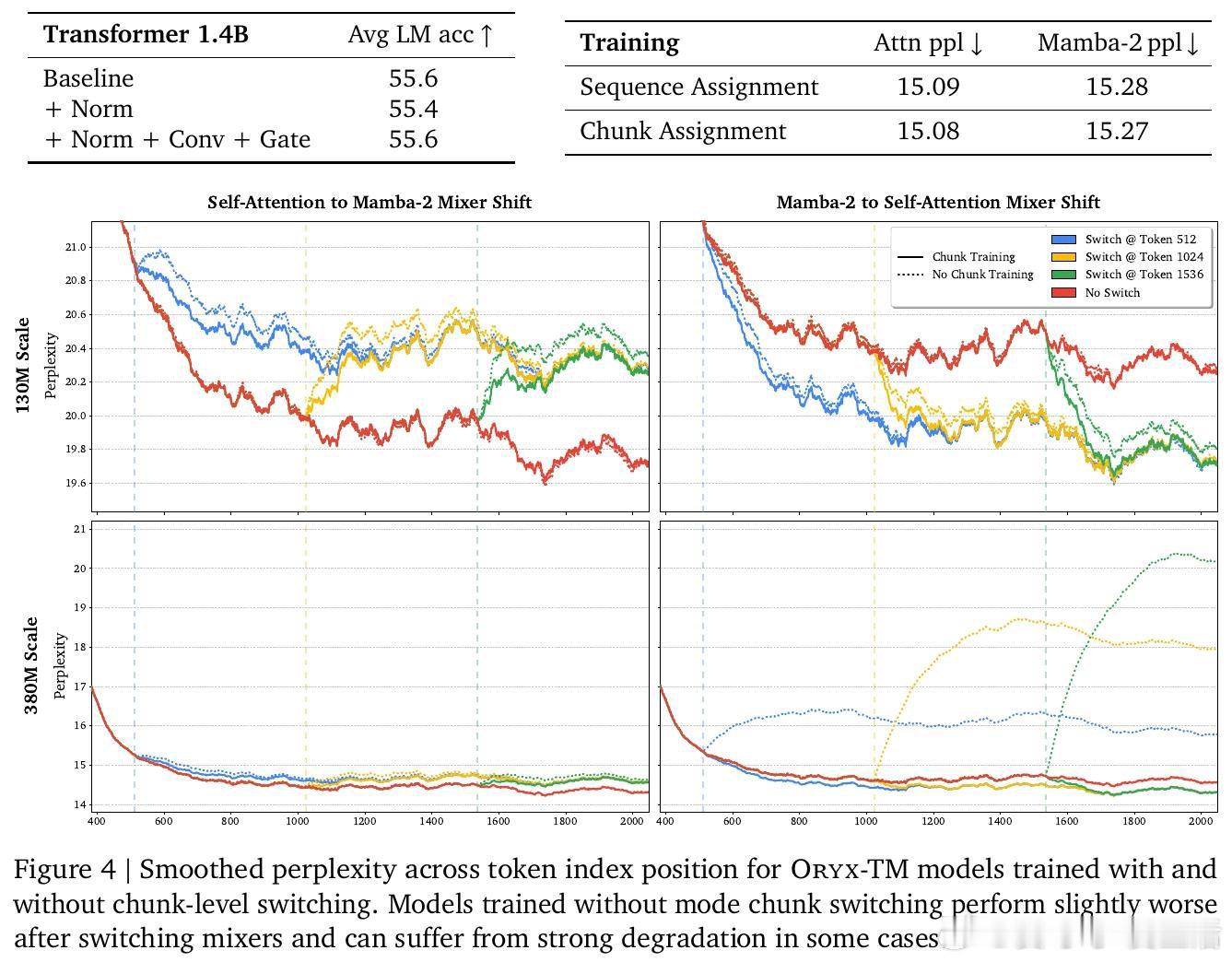
本文的核心洞见是:把注意力与线性递归看作共享键值记忆的两种读写方式。由此,Oryx共享键值投影,在序列中按块切换混合器。
这项工作留下的是“序列轴混合”范式。它打开了按任务分配注意力成本的新门,但尚未解决同时维护KV缓存与递归状态的开销。
arxiv.org/abs/2605.28769 机器学习 人工智能 论文 AI创造营