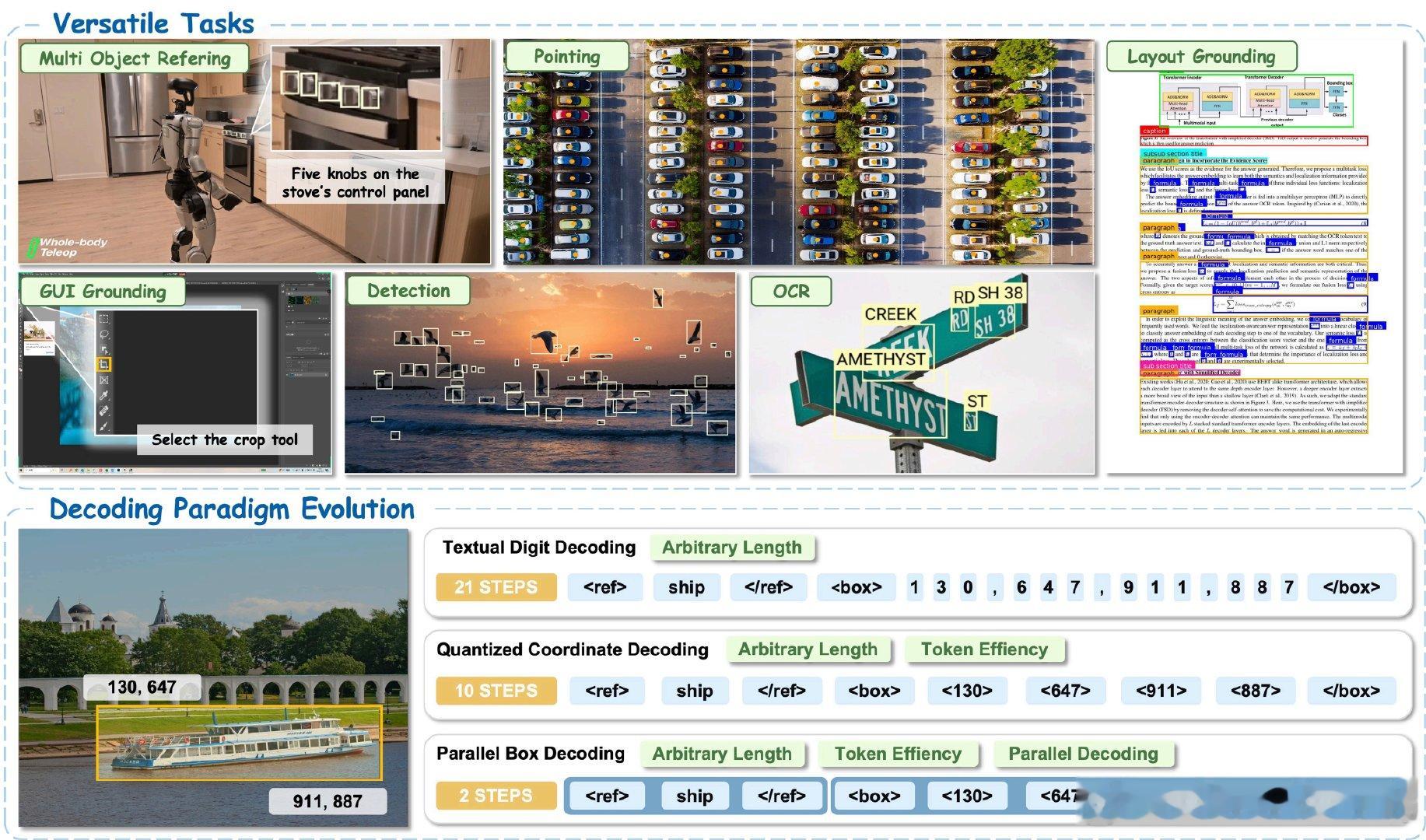
LocateAnything 是一套统一的高性能视觉语言定位框架,它将多种定位任务整合到单一模型中,实现了快速且精准的视觉 grounding 解决方案。
该框架创新性地采用 Parallel Box Decoding(PBD)技术,将每个边界框或点作为原子单元一次性预测,相比传统逐 token 解码方式大幅提升吞吐速度,同时保持几何结构的完整性。支持 Fast Mode(MTP)和 Slow Mode(NTP)混合推理模式,兼顾速度与准确率。
GitHub:github.com/NVlabs/Eagle/tree/main/Embodied 论文:research.nvidia.com/labs/lpr/locate-anything/
主要特性:- 统一视觉语言模型,支持文档理解、GUI 定位、密集目标检测、OCR 定位等多种任务;- Parallel Box Decoding 实现单步并行预测,吞吐量提升最高可达 2.5×;- 混合推理模式,默认使用快速模式,遇到格式或空间歧义时自动回退至稳定模式;- 提供 LocateAnything-Data 数据集,包含 1.38 亿语言查询与 7.85 亿边界框,覆盖通用检测、GUI、指代理解、文本定位等多领域;- 在 LVIS、M6Doc、ScreenSpot-Pro 等基准上实现 SOTA 定位精度,同时保持高效推理。
支持多种分辨率与密集场景,适合机器人、具身智能、文档分析等高精度定位应用。