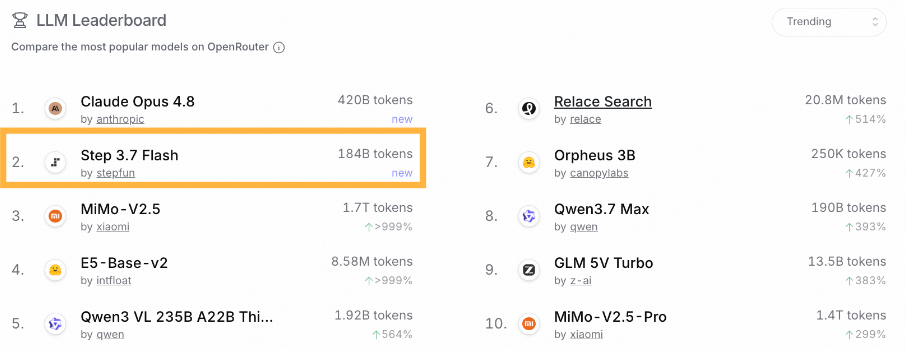
最近刷OpenRouter Trending,看到榜单前排出现了阶跃的Step 3.7 Flash,全球第二,发布才两天。
我还是蛮惊讶的。今年2月那次我还有印象,阶跃发的上一代模型 Step 3.5 Flash,也是发布后两天登顶。这次 Step 3.7 Flash,同样发布不久,就在开发者刷了屏。
连续两代,同一个系列模型,都迅速被开发者投入规模化应用。
这不是运气,而是阶跃可能踩准了接下来AI竞争里最关键的一个点,今天我们就来聊聊这件事。
1首先,OpenRouter Trending这个榜单,跟我们常见的AI跑分榜其实不是一回事。
跑分榜测的是模型在标准化测试里的表现,但OpenRouter Trending不测能力,它统计的是全球开发者的真实调用量。
相当于是开发者拿自己的钱包投票,选出来的结果。
能在这张榜上占据前排,只有一个原因:开发者真的在用这个模型干活,而且用得很多。在实际开发场景里,它足够好用、稳定、性价比高,开发者才愿意把自己的生产任务交给它。
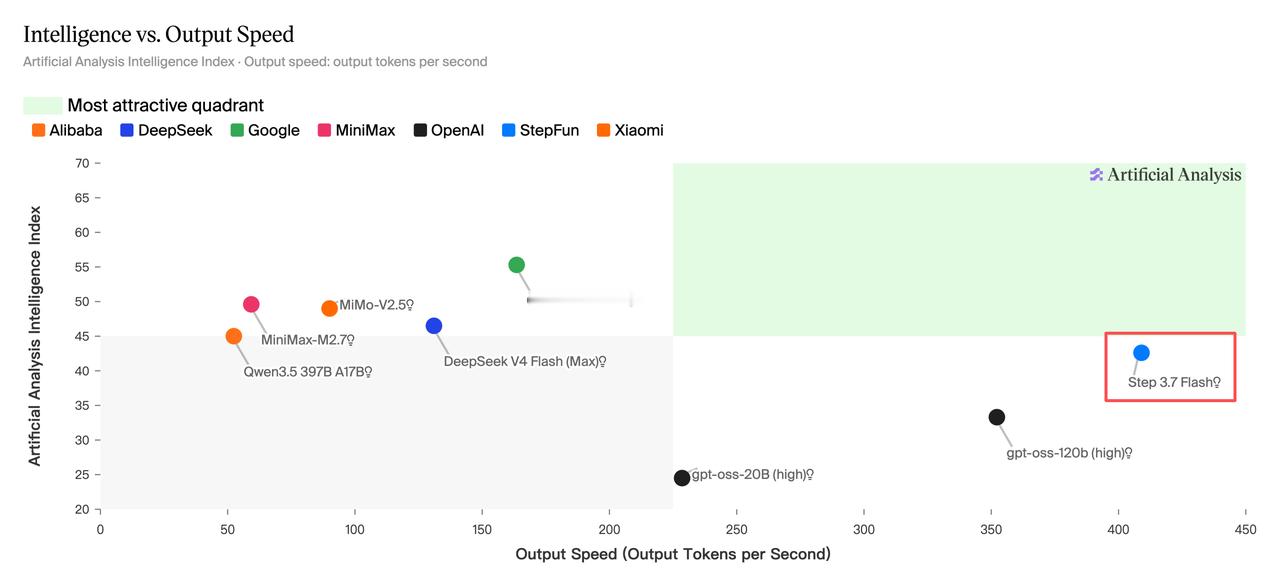
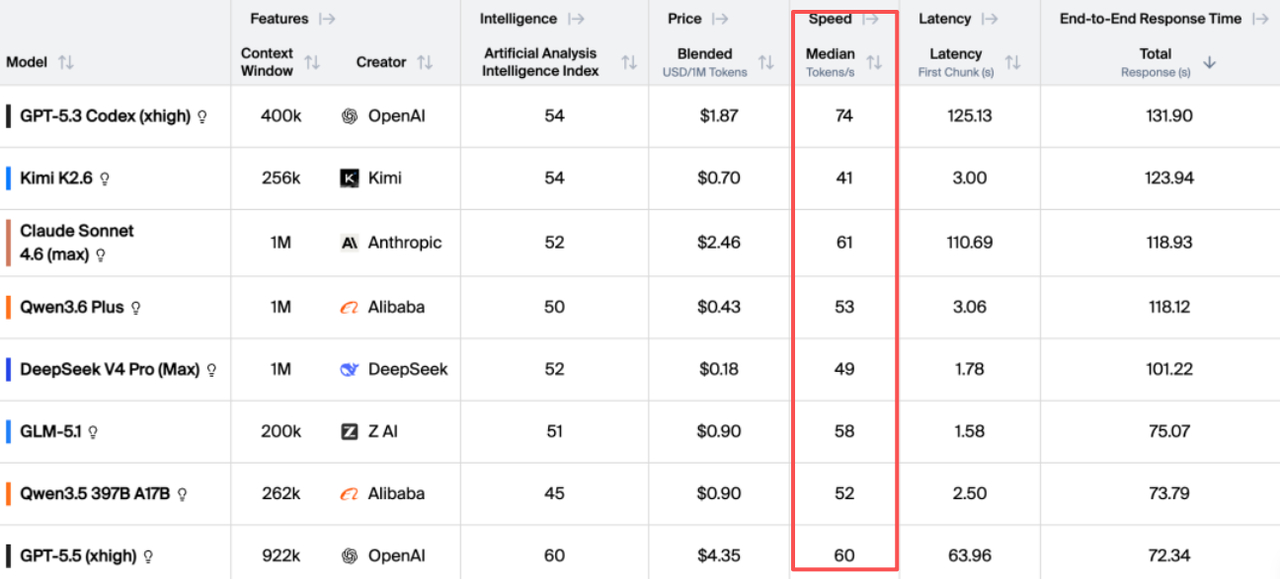
与此同时,Step 3.7 Flash还登上了另一个榜单——Artificial Analysis,简称AA榜,全球公认最权威的大模型性能评测之一。
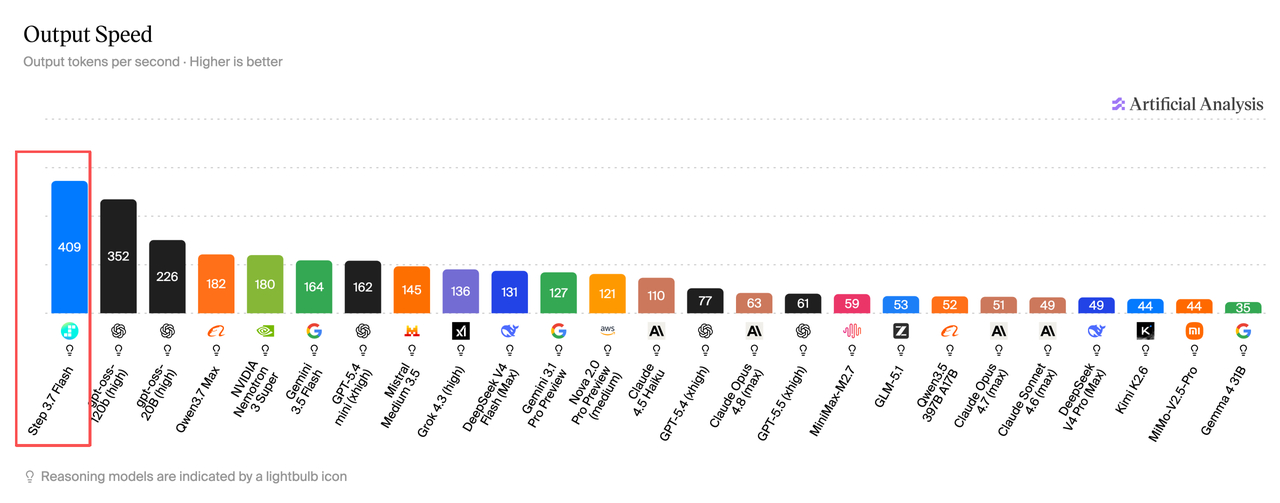
在AA榜上,Step 3.7 Flash拿下了输出速度主流模型第一,409 tokens每秒。端到端响应时长、智能效率、速度价格比,在多个关键维度都处于领先位置
一个模型能同时在这两张榜上领先,是真的被开发者用起来了。
2我把阶跃今年Flash系列的时间线拉出来看了一下:
2月,阶跃发布Step 3.5 Flash,发布即登顶OpenRouter Trending。一个月内,成为OpenClaw调用量全球第一。上线两个多月后,量产上车极氪8X,成了这款旗舰车型的Agent大脑。
5月底,阶跃发布Step 3.7 Flash。发布两天,冲上OpenRouter Trending全球第二,同步拿下AA多个第一。
一次可以说是运气好,连续两次,说明背后有一套成熟的体系在支撑。
3聊到这里,想展开一个我最近在思考的问题:为什么Flash模型现在变得越来越重要了?
目前市面上绝大多数大模型的推理速度在100 Tokens/s 以下,而Step 3.7 Flash的输出速度超过了400 Tokens/s。
这个速度放在单轮对话里,体感可能就是回答快了一些。但现在,AI的使用方式已经不是单轮问答了,而是在 Agent 场景里跑实际工作任务。
一个真实的Agent任务,可能要经历二十步、五十步的连续操作。
如果单次响应慢1秒,50步下来就是用户就要多等将近1分钟。在生产环境里,这种延迟是不可接受的。
成本也一样。单次调用便宜几分钱看起来没什么,但乘以高频调用、长链路任务、规模化用户量,成本差距会被成倍放大。
如果模型很贵,那哪怕效果再好,企业也不敢大规模用。
Agent时代真正的竞争指标,已经从「单次有多聪明」变成了「单位成本下,能持续交付多少有效智能」。
因为对企业而言,这是直接决定模型用不用得起的关键因素。而这恰好就是Flash模型的主场,够快、够稳、够便宜,能扛住高频长链路的持续调用。
有人测过,开了Advisor Mode之后,它的编程能力达到了Claude Opus 4.6的97%,但单任务成本只有大约九分之一。
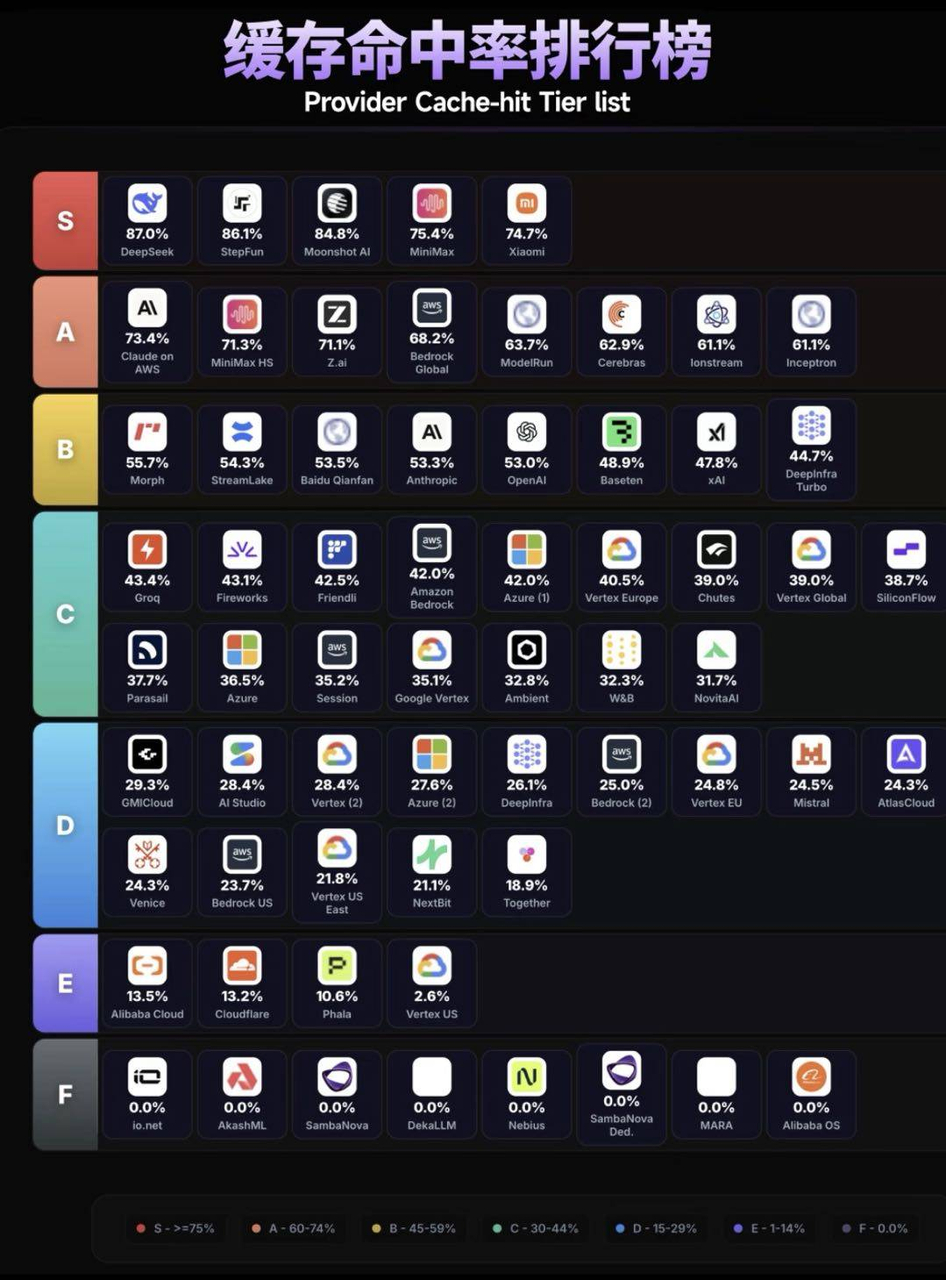
再给大家分享一组数据。有开发者统计了OpenRouter上60多个服务商、398个模型的缓存命中率,阶跃排全球第二,和DeepSeek、Moonshot同属第一梯队。
这意味着,在长任务和Agent场景里,这意味着阶跃模型的实际推理成本会比账面价格低不少,速度优势也更加明显,这也让这个模型在企业级Agent市场里有了更大的竞争优势。
4把上面这些要素放在一起看,我觉得阶跃想明白了一件事:未来AI大规模落地,不会只靠几个贵的旗舰模型。
旗舰模型当然重要,它代表智能天花板,但真正支撑日常生产任务的,一定是那些能力够用、成本可控、部署灵活的效率型模型。
Agent、Coding、搜索、多模态办公,这些高频场景需要的不是偶尔惊艳的天才选手,而是能7×24持续干活、成本可控的生产力模型。
阶跃连续两代Flash都在这个方向押注,每一代都能在全球开发者社区跑出来,说明这个判断正在被市场接受。
Anthropic今年估值和ARR涨得很猛,也从侧面印证:企业级Agent的商业化不是故事,是正在发生的事。想做好这门生意,效率型模型就是基础设施。
当然,领先不等于终局。Agent市场本身还在早期,持续迭代的能力、往垂直场景深扎的能力、把模型嵌到企业工作流里长期跑的能力,远比一次霸榜要更难。
但从目前的节奏来看,阶跃连续两代Flash模型的表现,都在回答一个问题:单位成本内能交付多少有效任务,单位时间内能完成多少次稳定执行,才是Agent时代真正的硬指标。
接下来的市场会怎么走,值得持续关注。