一来长任务容易崩,二来交付质量达不到商用标准,最后还是要人工返工,算下来省不了多少事
到了今年,这个局面是真的被打破了。最近跟不少一些技术负责人啊,创业者聊天,大家就一句话,能不能接进现有工作流?这也说明模型需要跨过一道关键的质变线
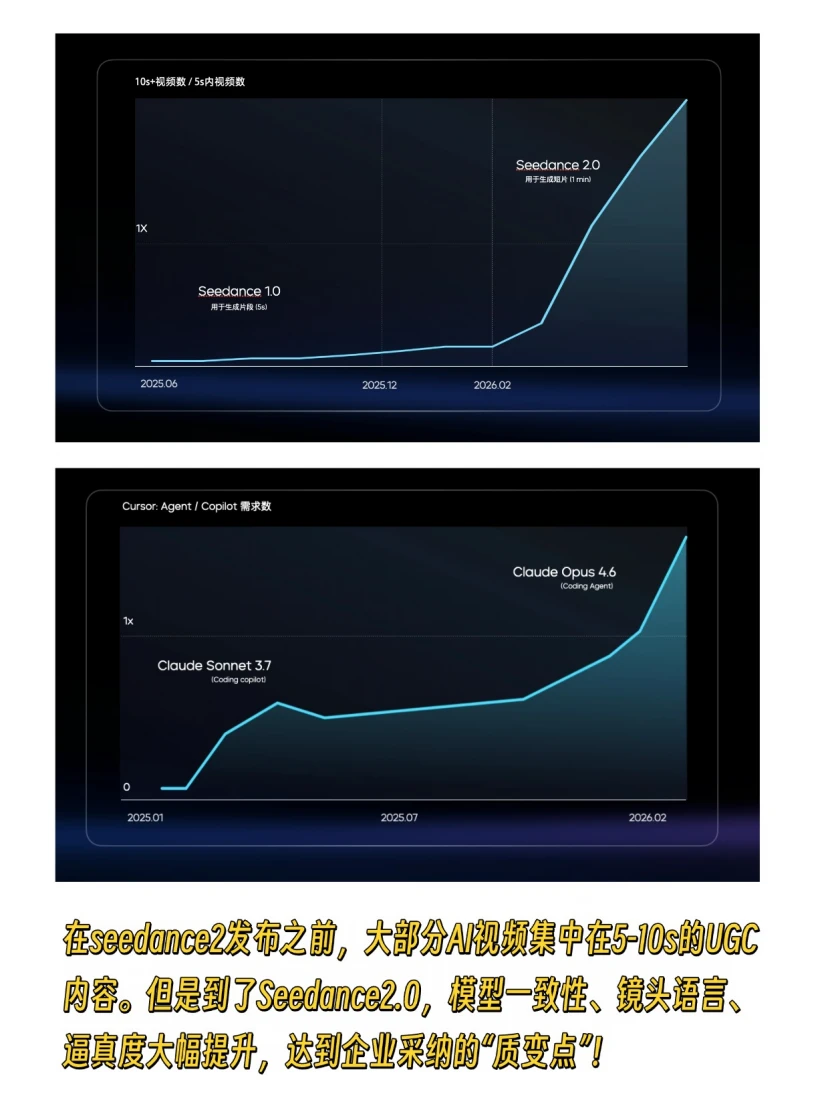
这条线也很微妙,不是线性的分数提升,是跨过某个节点后,模型突然就能hold住复杂长任务了
比如视频生成赛道,Seedance 2.0就是行业公认的质变节点。之前的AI视频大多是几秒的 UGC内容。它出来之后,镜头的一致性和逼真度直接达标,真正进入商业生产流程。Coding的变化更明显,Opus 4.6发布后,变成了整个项目的主力
这次火山引擎Force大会发布的豆包大模型Seed-2.1,我说实话真挺意外的。这可以说是一个突破了上述生产级质变点。在我看来,一个模型真的跨过生产级这道坎,得满足四个核心要求
一是能写出可以直接交付的生产级代码。第二,要能适配并完成复杂的Agent任务。第三还要具备领先的多模态理解能力,并且实现GUI操控。第四能够在企业级场景下稳定地规模化运行。对照这四条标准看,豆包 2.1 这次的升级刚好全方位踩中了生产级的门槛
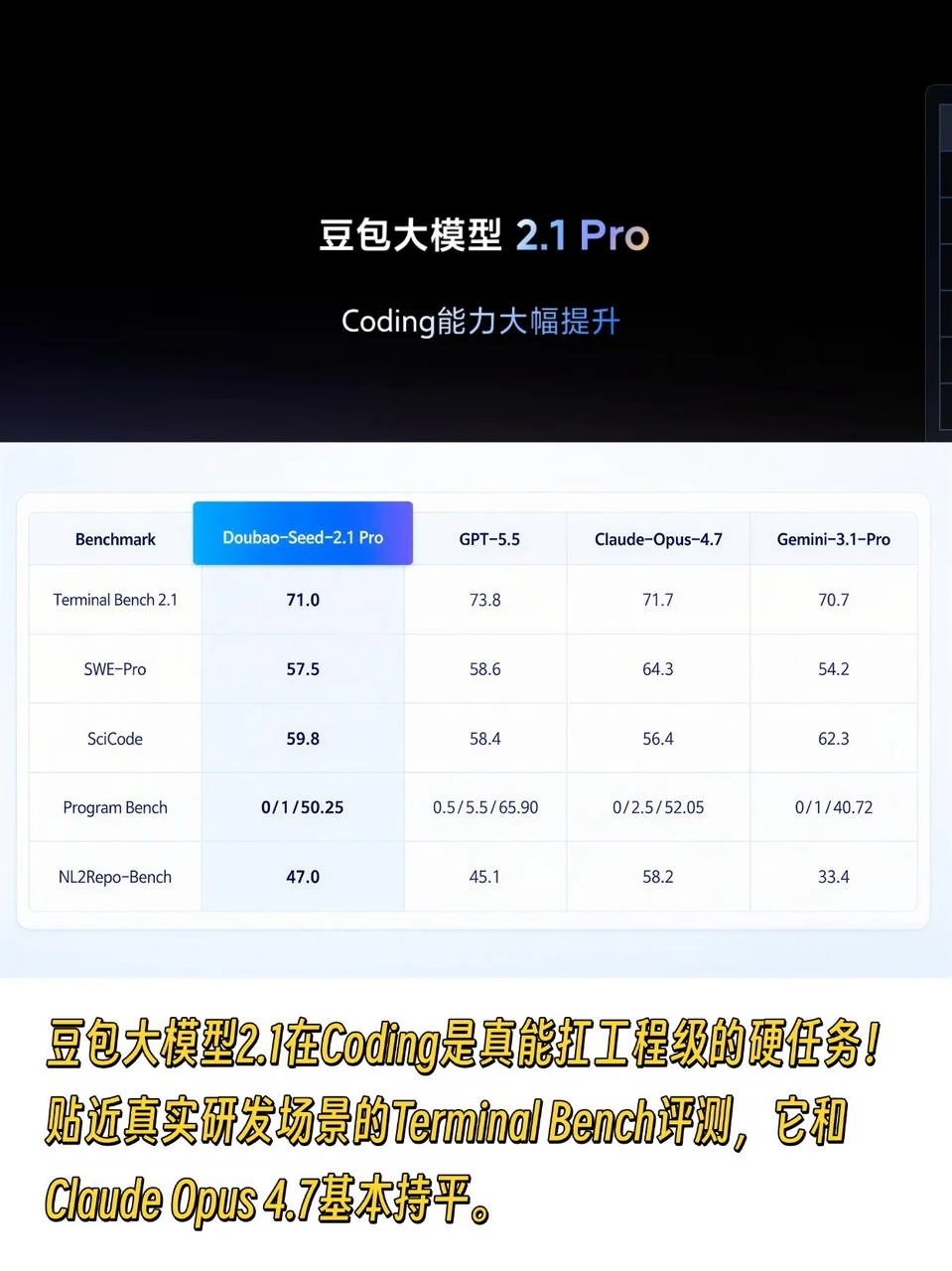
这次核心升级的Coding和Agent能力,也刚好对应前两条标准。Coding是真能扛工程级的硬任务,而非刷算法题那种纸面的强。贴近真实研发场景的Terminal Bench 2.1评测,它和Claude Opus 4.7基本持平
科学计算方向的SciCode,成绩超过了Opus 4.7和 GPT-5.5,仓库级代码生成的NL2Repo-Bench,则明显领先 GPT-5.5 和Gemini 3.1 Pro
最硬核的是芯片RTL设计的实测,原本要数名工程师做数周的工作,模型连续跑了18个小时,经历9轮迭代,就把仿真和测试全流程都跑通了。这已经是生产级交付能力了
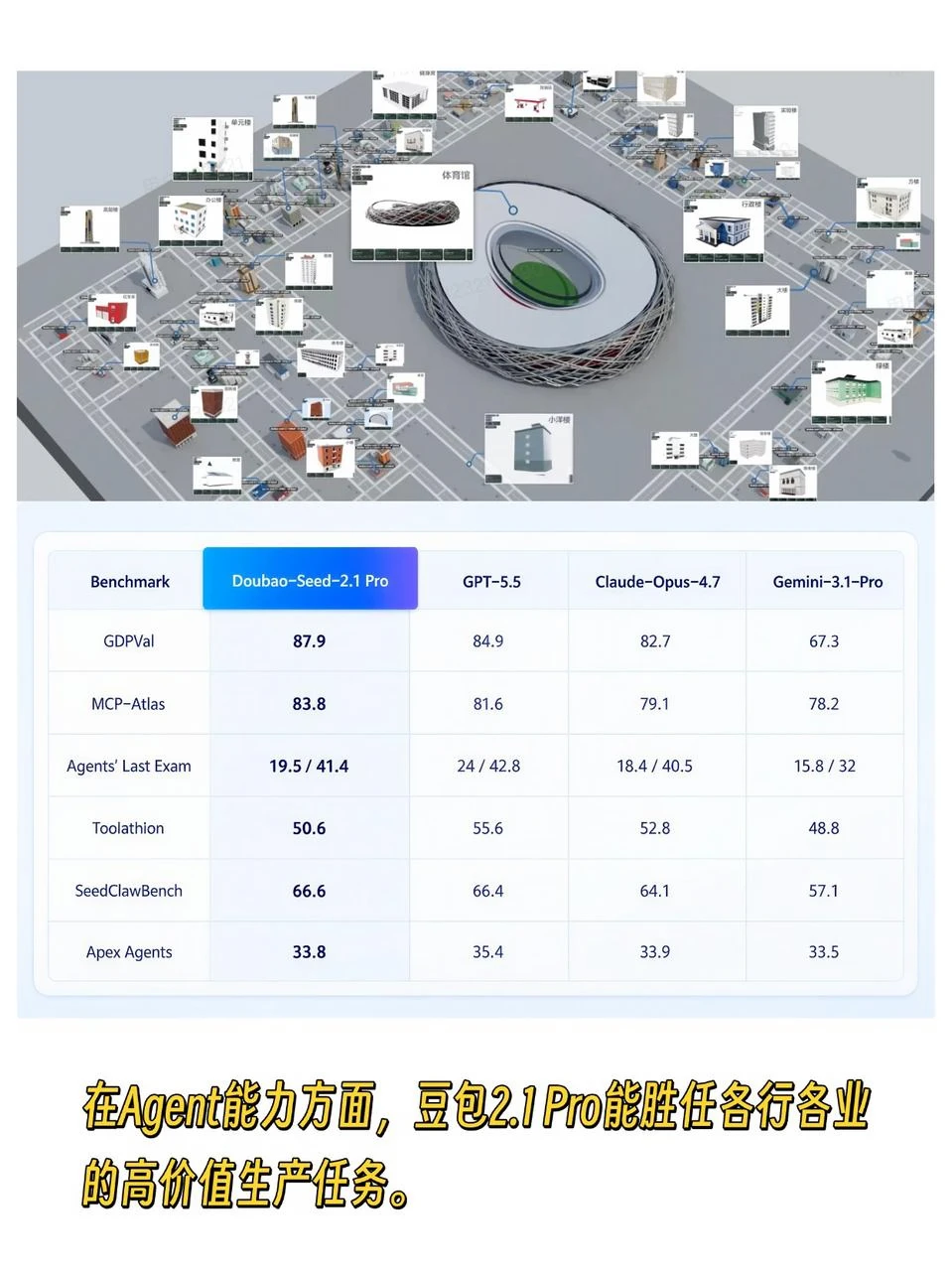
豆包2.1 Pro的Agent能力同样跨级提升。在一个案例中豆包2.1 Pro调度了500+个协同作业,累计触发工具调用上千次,最终在同一张大地图上建成100+不同的建筑,完成多轮自我迭代与全景成片
说句实在的,要生产级落地,那性价比永远是硬指标。豆包2.1Pro百万token输入6元、输出30元,缓存命中只要1.2元,综合成本比Claude Opus低近80%
整体看下来,这可以说是国产大模型真正摸到生产级门槛的一步,值得留意