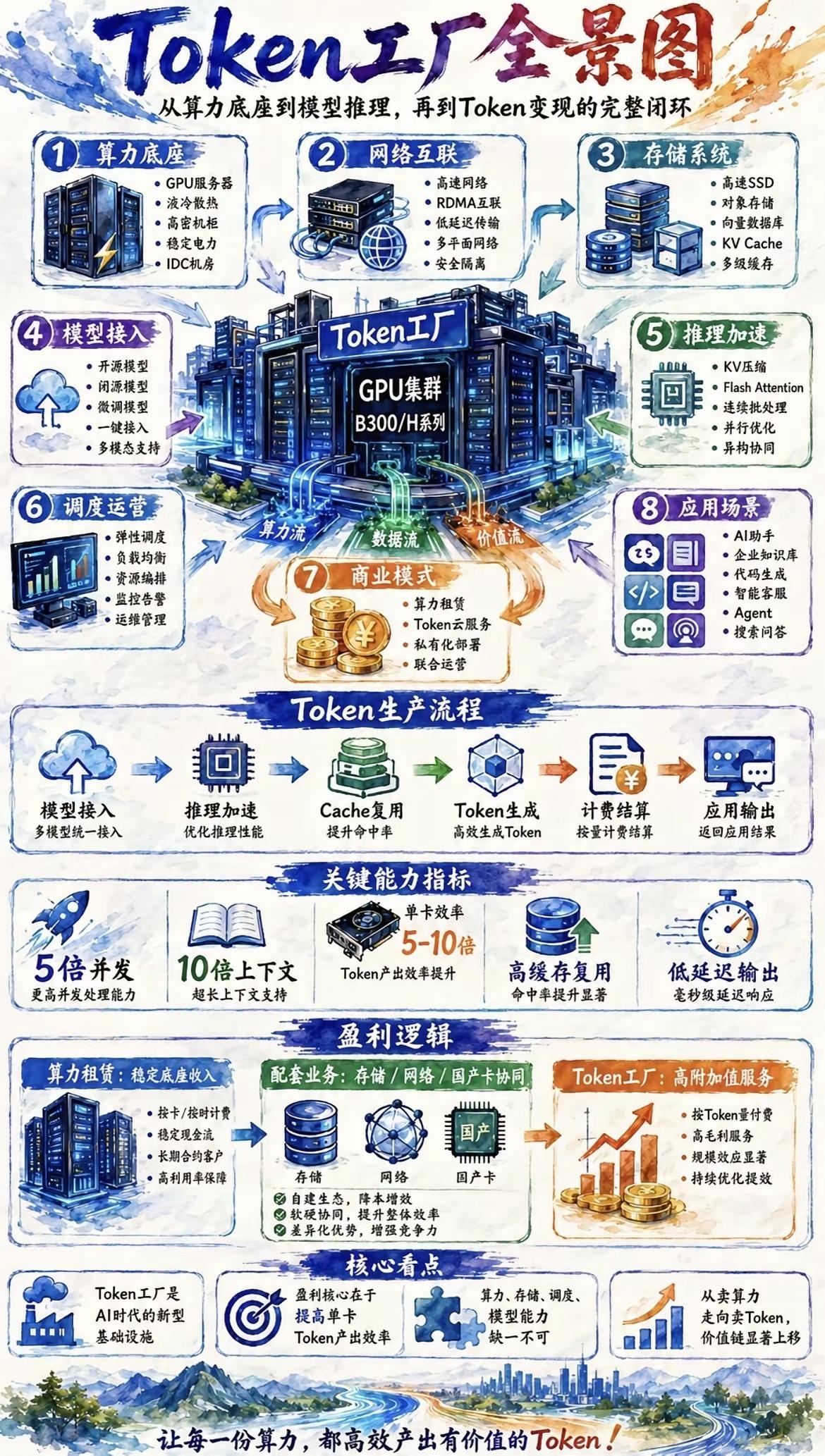
Token工厂全景图完整解读:AI算力到Token变现全闭环体系
一、八大核心底层模块(算力→推理完整链路)
1. 算力底座
底层硬件根基,包含GPU服务器、液冷散热、高密度机柜、稳定供电、专业IDC机房,支撑全部推理负载。
2. 网络互联
高速RDMA低延迟互联、多平面安全隔离网络,解决大模型海量数据传输卡顿问题。
3. 存储系统
高速SSD、对象存储、向量数据库、多级KV缓存,承载模型权重、业务知识库、会话缓存数据。
4. 模型接入
统一入口兼容开源/闭源/微调/多模态模型,一键完成模型部署接入,无需重复改造对接。
5. 推理加速
KV压缩、FlashAttention、批量并行、异构协同优化,直接拉高单卡Token产出效率5-10倍。
6. 调度运营
弹性扩缩容、负载均衡、资源智能编排、全链路监控告警,保障算力资源不闲置、不爆量。
7. 商业模式(价值流转)
三条盈利路径:算力租赁、Token按量云服务、私有化部署、联合运营;行业价值从“卖硬件算力”升级为“卖标准化Token服务”。
8. 上层应用场景
覆盖AI助手、企业知识库、代码生成、智能客服、Agent智能体、检索问答全行业落地场景。
二、标准化Token生产流水线
模型统一接入 → 推理性能加速优化 → Cache缓存复用(降低重复Token消耗) → 高效生成Token → 按量计费结算 → 业务应用输出结果
缓存复用是控制成本的核心环节,能大幅削减重复上下文带来的无效Token支出。
三、五大核心能力指标(降本增效关键)
1. 5倍并发:同硬件承载更高并发请求,摊薄单Token硬件成本
2. 10倍超长上下文:原生支持百万级长文本,适配大型代码、长文档Agent场景
3. 单卡Token效率提升5-10倍:推理加速技术直接压缩单位Token算力损耗
4. 高缓存复用:高频固定Prompt、项目上下文缓存命中,减少重复输入计费
5. 低延迟毫秒级输出:兼顾体验与批量处理吞吐量
四、三层阶梯盈利逻辑
1. 底层:算力租赁(稳定基础收入)
按时/按卡计费,现金流稳定,依靠高机柜利用率盈利,门槛最低、毛利偏低。
2. 中层:配套增值业务
存储、高速网络、国产算力配套打包售卖;软硬协同降低客户自建成本,提升整体竞争力。
3. 顶层:Token工厂标准化服务(高附加值核心)
按Token流量计费,规模效应显著,依托推理加速、缓存复用技术拉高单卡产出,是行业价值最高的商业模式。
五、核心行业看点
1. Token工厂是AI时代新型算力基础设施,打通硬件到业务落地完整链路;
2. 盈利核心指标是单卡Token产出效率,推理、缓存、调度优化直接决定利润;
3. 算力、存储、网络、调度、模型加速五大模块缺一不可,缺少任意一环都会造成成本暴涨;
4. 产业升级趋势:单纯售卖GPU硬件逐步淘汰,标准化Token云服务成为主流,产业链价值向上迁移。
结合你团队Token成本失控痛点落地启示
1. 自建/选用具备多级KV缓存的Token工厂底座,缓存项目固定规则、系统Prompt,直接削减30%+输入Token消耗;
2. 启用推理加速组件(FlashAttention、批量并行),同等代码开发量下,单任务算力开销压缩至原先1/5~1/10;
3. 配套弹性调度+用量监控,设置单账号/团队Token额度熔断,避免单日充值额度一次性耗尽;
4. 优先选择按Token计费的云服务模式,放弃无上限私有化裸算力租赁,精准管控研发AI预算。
Token工厂 大模型算力基础设施 AI算力降本 Token计费体系 AICoding成本治理 大模型推理优化 企业级AI架构 AI底层架构 AI计算架构 aitoken ai架构图 算力token ai算力工厂