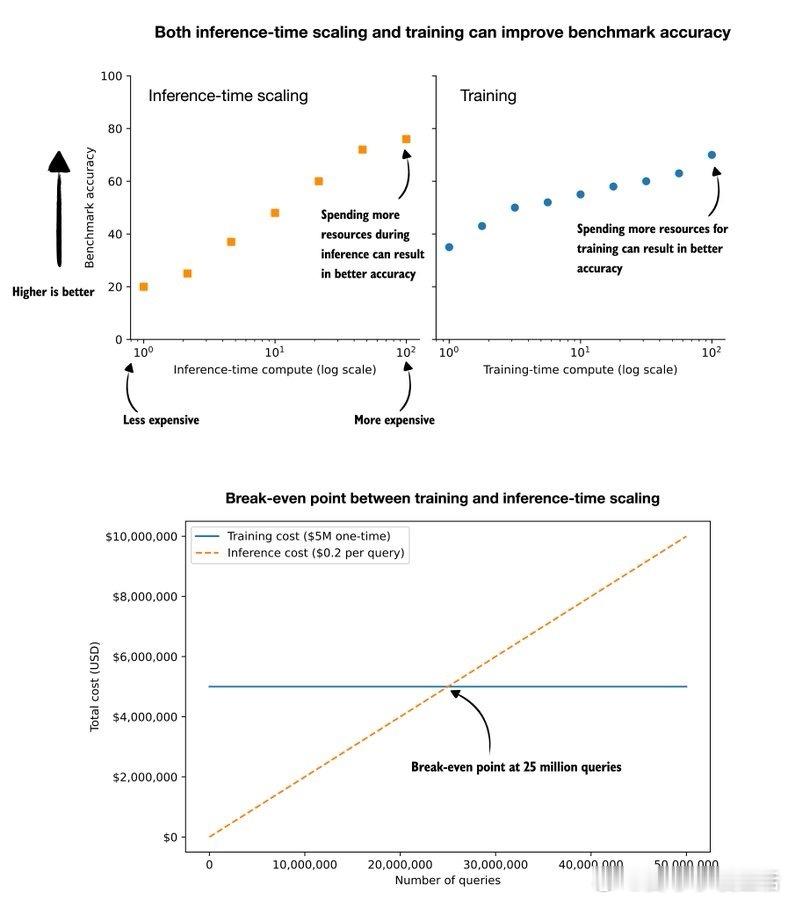
Sebastian Raschka提出了一个关键问题:在提升大型语言模型(LLM)性能时,我们应更注重训练阶段的投入,还是推理(inference)阶段的扩展?训练成本高且一次性,但推理成本低却是持续性的,每次查询都要付费。假设我们想让模型在某基准上提升5%,训练费用需500万美元,而推理阶段每次查询因使用更多token需额外支付0.2美元。两者的“盈亏平衡点”是2500万次查询。若用户每天平均查询10次,约7000名日活用户运行一年即可达到这一点。这意味着: - 用户量少、查询频次低或模型更新快的场景,单纯加大训练投入不划算。 - 大规模、高频使用的产品更适合先投入训练。 - 其实,两者结合(训练+推理扩展)能带来更大提升。这背后的核心逻辑是成本与使用规模的权衡,企业应根据模型生命周期和用户行为做出理性决策,而非盲目追求“训练定制”这一所谓的“身份象征”。毕竟,租用计算资源,待真正需要时再“拥有大脑”,往往更经济实用。此外,快速迭代的组织更多依赖推理扩展,高规模产品才会考虑高额训练成本。对企业来说,关键在于精准衡量训练成本与推理费用的平衡点,并将此纳入产品规划和定价策略。换句话说,模型投资不是一场“训练vs推理”的简单对决,而是基于查询量、生命周期、用户行为的动态优化。深刻理解这一点,才能避免资源浪费,最大化AI应用的价值。原文:x.com/rasbt/status/1990818353942769904