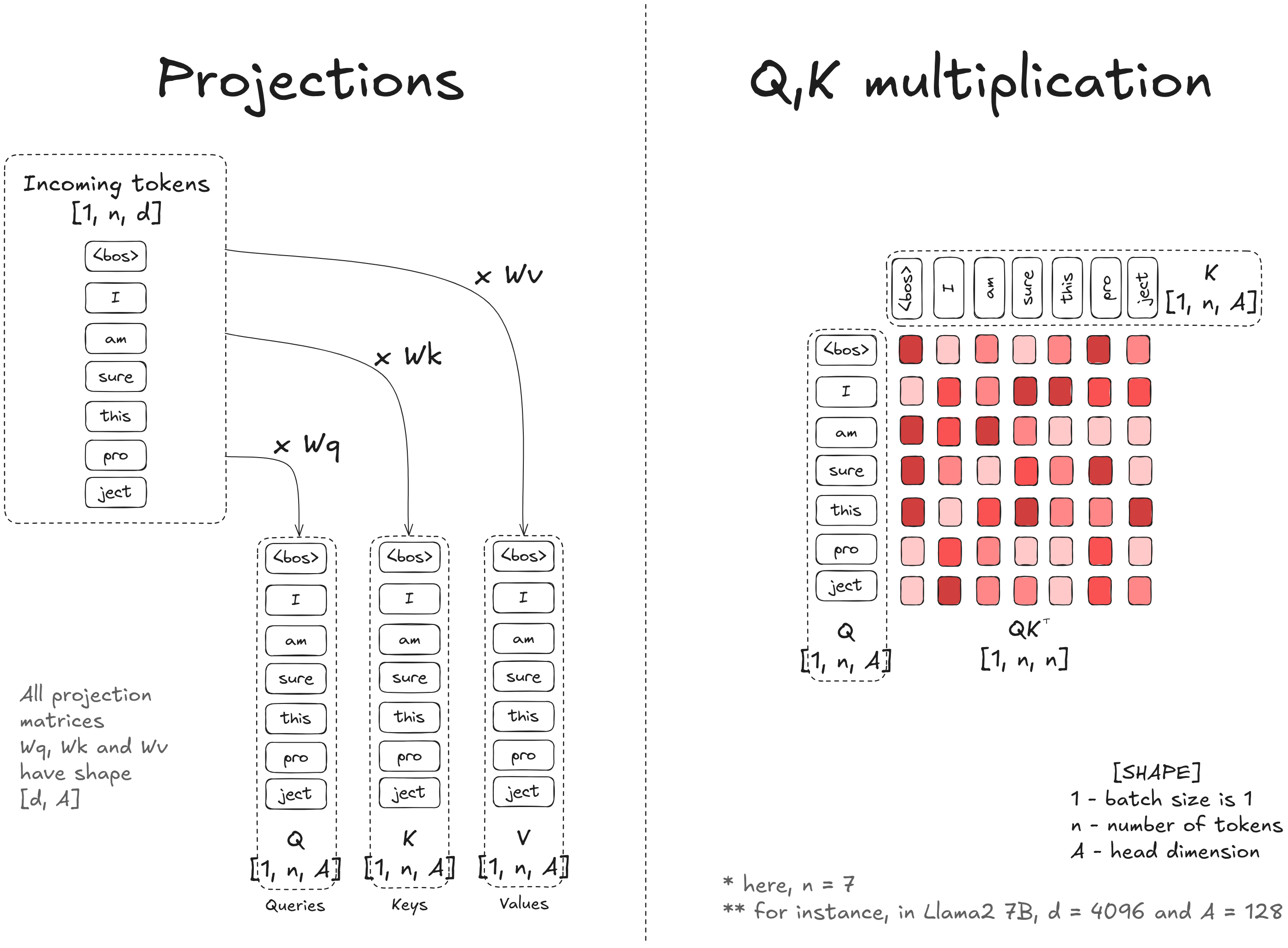
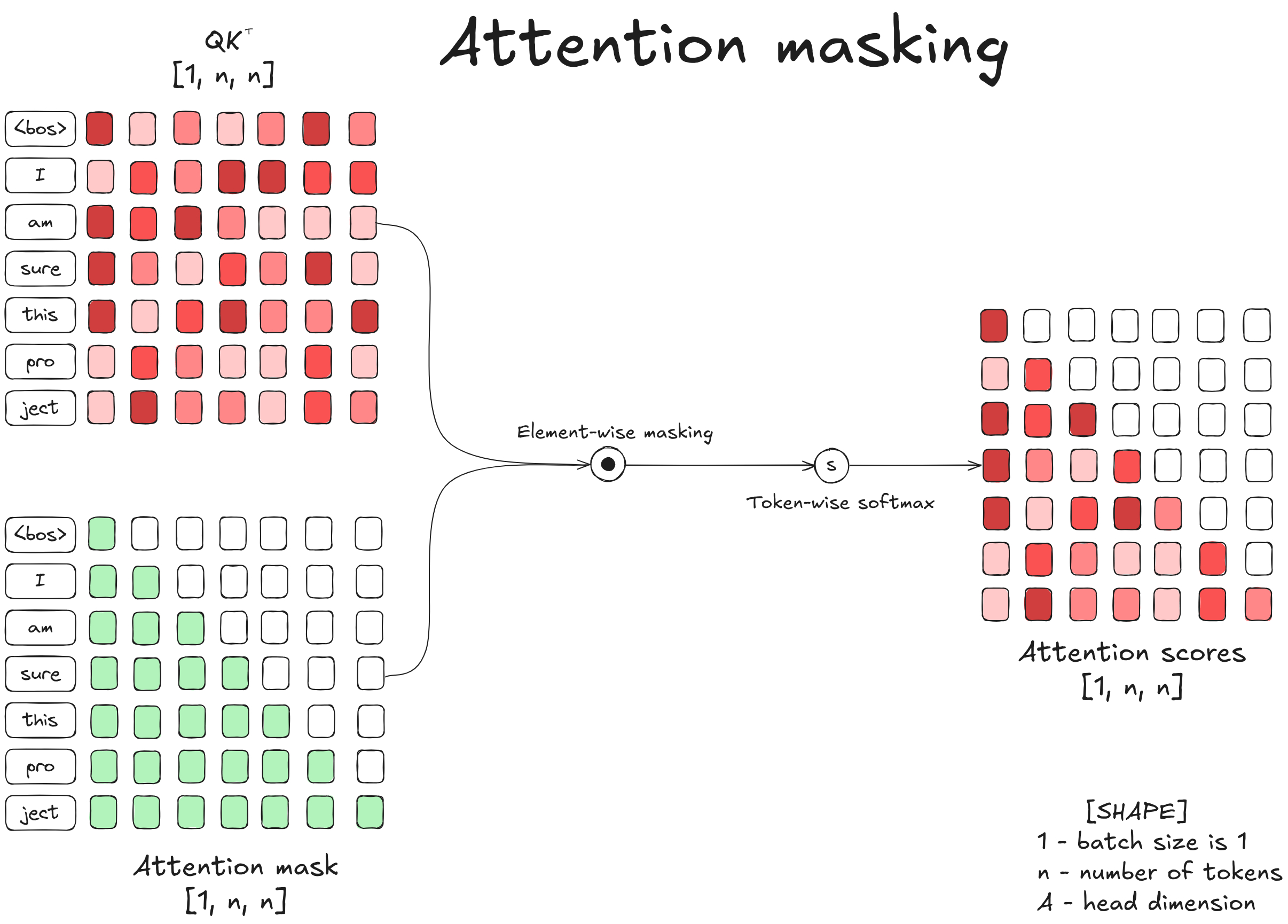
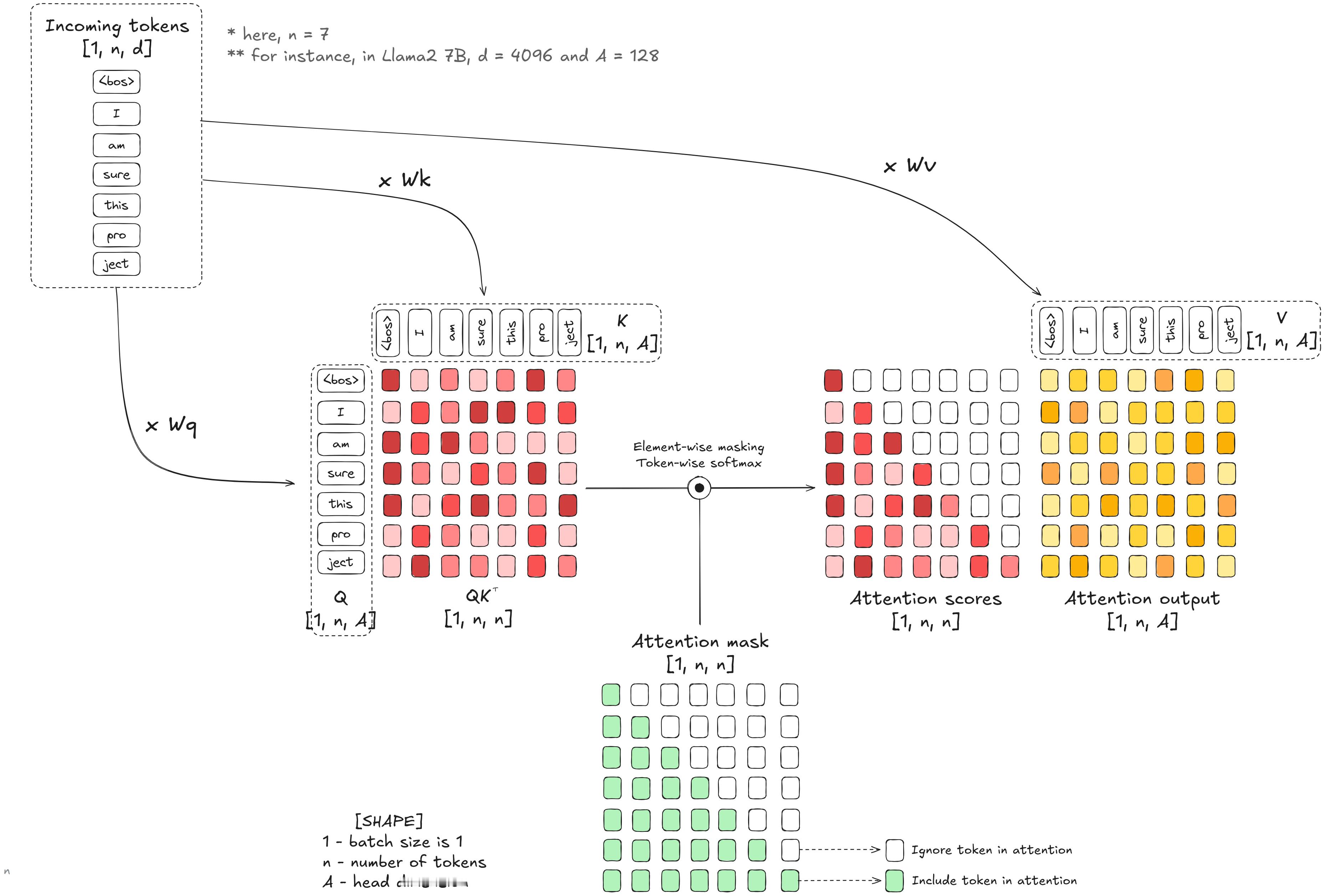
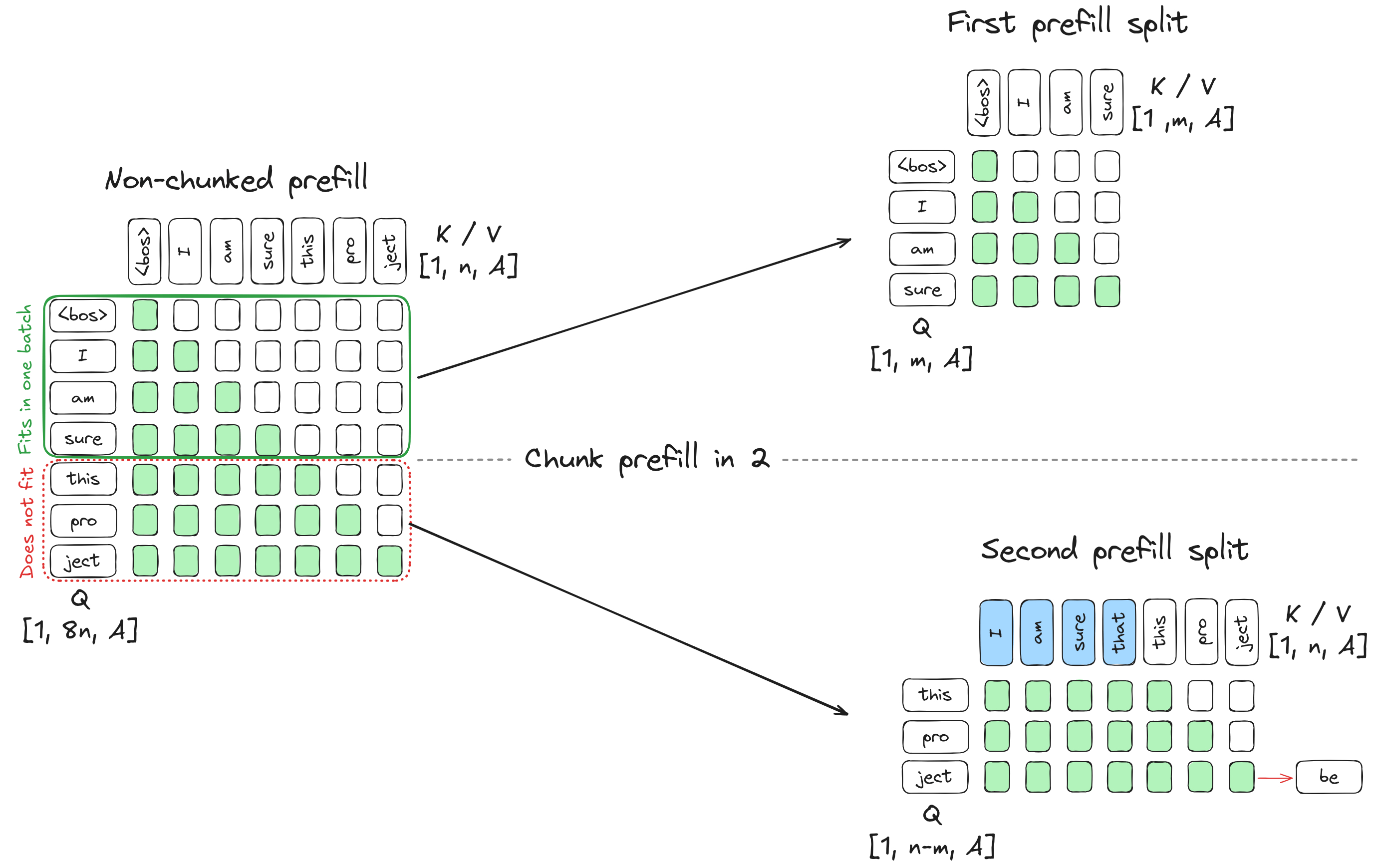
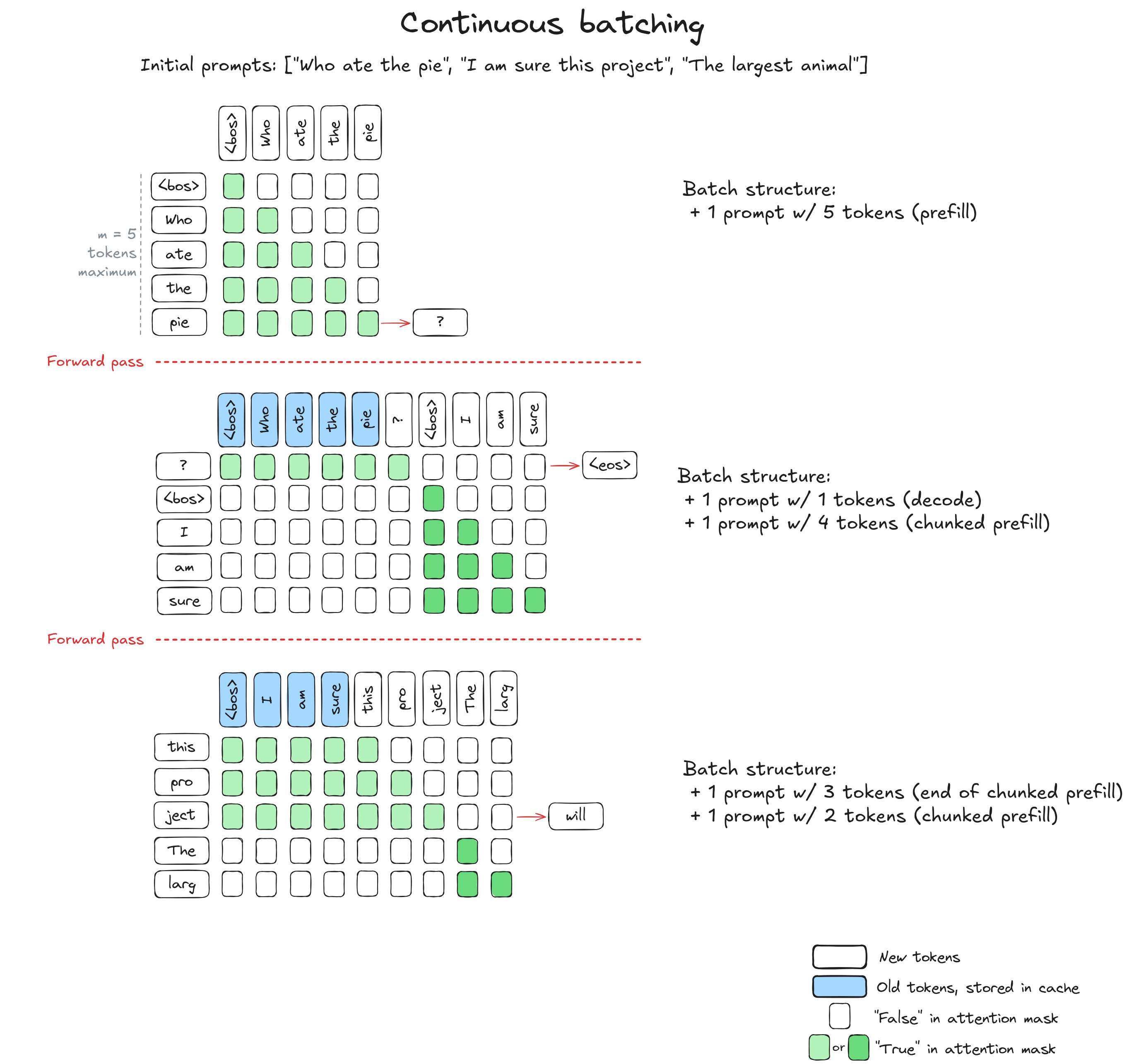
Hugging Face的一篇介绍连续批处理 “ Continuous batching ” 的高质量博文,有大量的可视化图表来帮助理解。huggingface.co/blog/continuous_batching在本篇博客中,我们将从注意力机制和KV缓存出发,通过优化吞吐量推导出连续批处理的原理。如果你曾使用过Qwen、Claude或任何其他AI聊天机器人,你可能注意到了一个现象:回复的第一个词出现需要一段时间,随后词语会一个接一个地出现在屏幕上,且(理想情况下)以稳定而快速的频率输出。这是因为本质上,所有大语言模型(LLM)都只是更高级的“下一个词”预测器。LLM首先处理你的全部输入提示,生成第一个新词元(token)。然后它逐个添加后续词元,每次都会重新读取之前生成的全部内容,直到判定生成过程结束。这一生成过程在计算上开销巨大:每生成一个词元,都需要将输入数据通过数十亿参数进行一次前向传播。为了让这些模型在实际应用中具备可用性,尤其是在需要同时服务大量用户时,研究人员和工程师开发了一系列高效的推理优化技术。其中最具影响力的优化之一是连续批处理(continuous batching),它通过并行处理多个对话,并在对话完成时动态替换,从而最大化系统性能。为了理解连续批处理的工作原理及其在高负载服务场景中为何如此高效,我们将从LLM处理词元的基本机制开始逐步展开。