在当前的大模型技术节点下,开源模型(如 GLM-5.2)在各类软件工程(SWE)基准测试中超越顶级闭源模型(如 GPT-5.4/5.5 的部分版本、Gemini 系列)的新闻频繁引发行业轰动。然而,技术宣传的“高光时刻”往往与实际落地的“用户体感”存在巨大脱节。
通过对成本、输出 Token 量以及模型努力程度(Effort Level)的联合分析,我们可以解构出这种脱节的本质:模型为了在打榜时压榨出最后几根百分比的性能,付出了极其高昂的经济与时间代价;而真正的工程真解,隐藏在被宣传掩盖的“次饱和”模式中。一、 现象表象:第三方视角下的“高分低能”陷阱
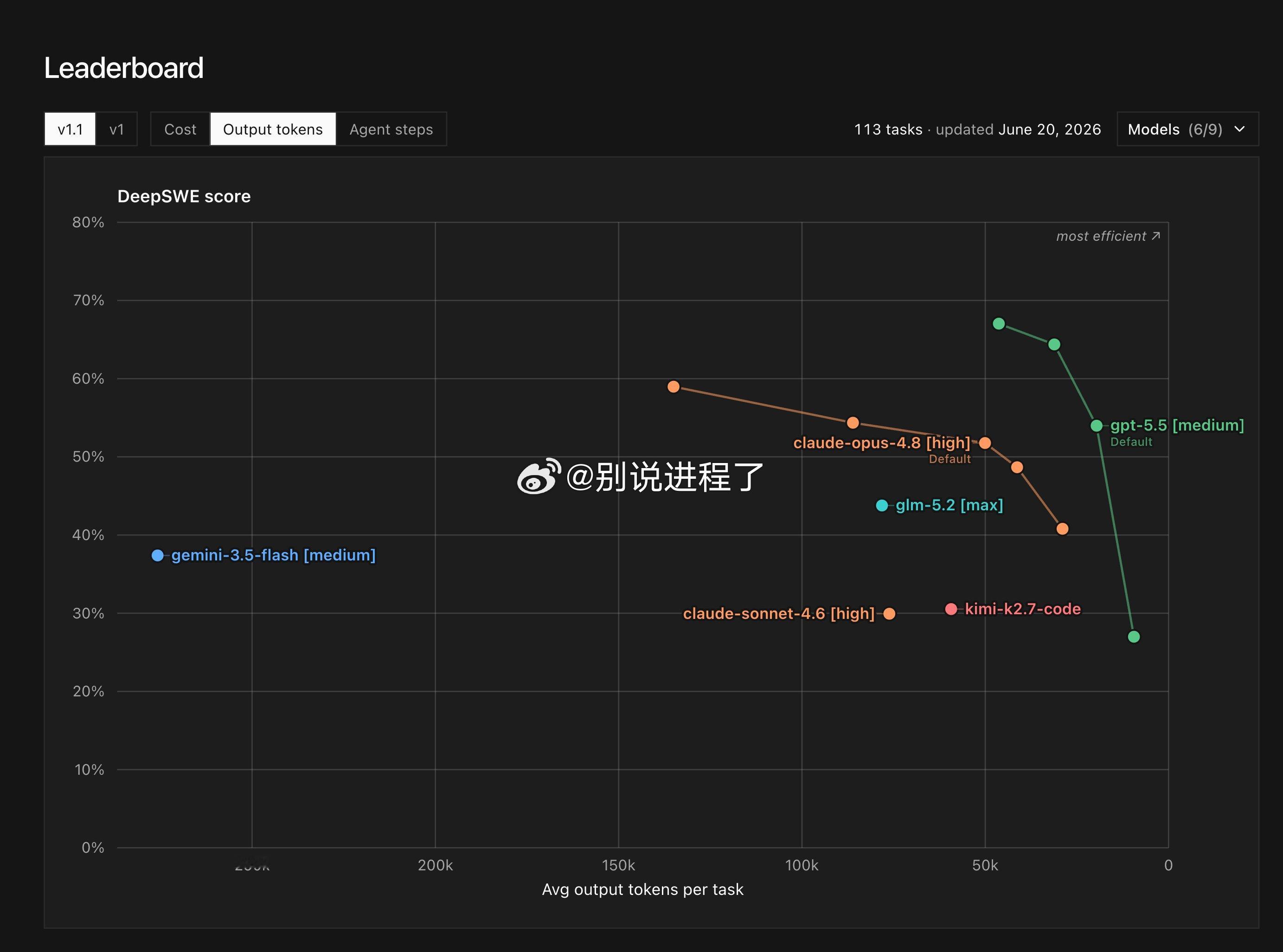
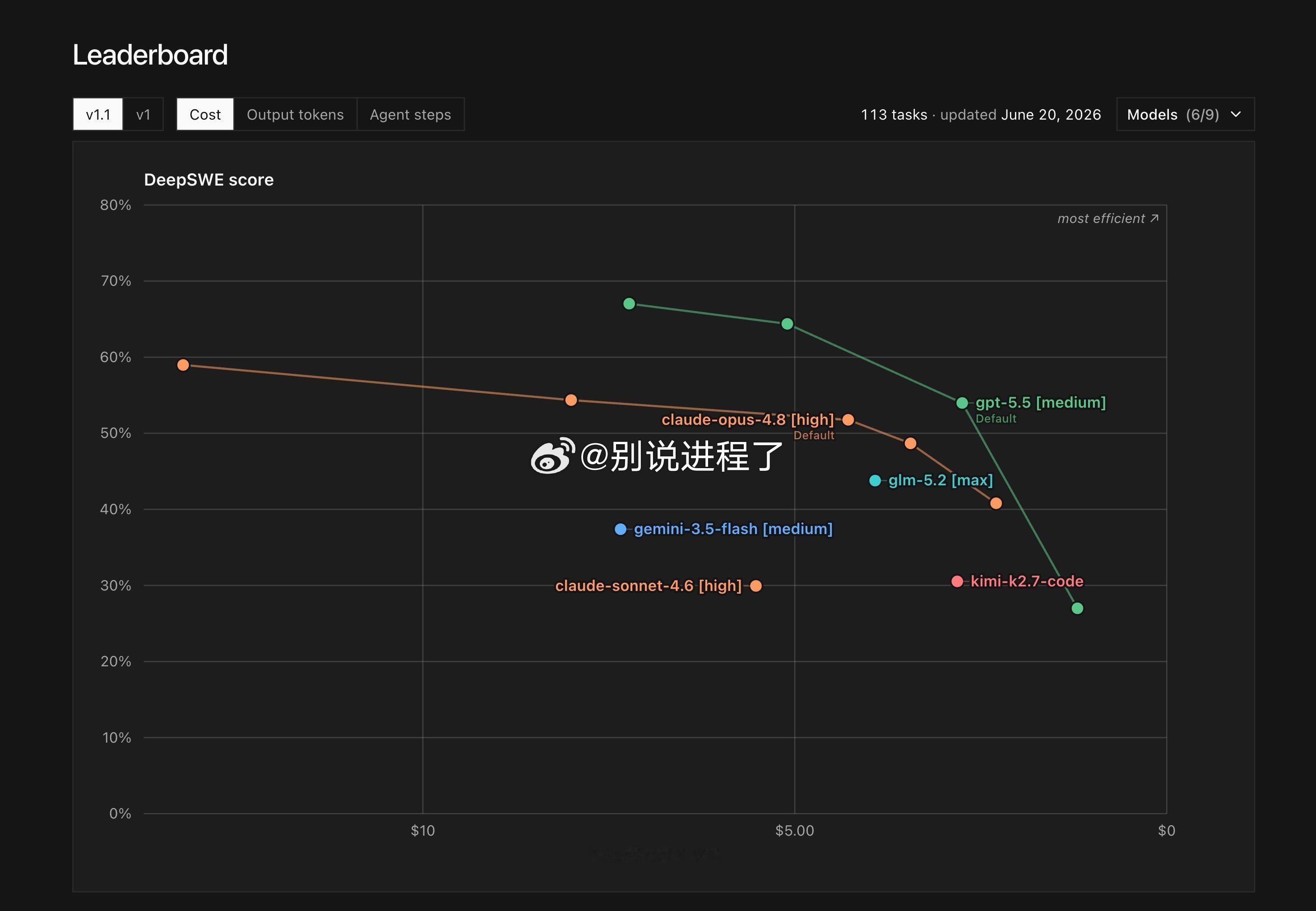
在 图片1(经济成本维度)和 图片2(时间/输出量维度)中,第三方评测提供了一个极其冷静的视角:1. 纸面实力的超越
从纵轴的 DeepSWE 得分来看,处于最大化推理模式下的 glm-5.2 [max] 确实拥有高达 44% 左右的正确率,击败了包括 Gemini 3.5 Flash [medium]、Claude Sonnet 4.6 [high] 以及 Kimi-k2.7-code 在内的一众强敌。这证明了开源模型在纯粹的“解题能力上限”上已经具备了与第一梯队叫板的资格。
2. 性价比前沿面的全方位溃败
然而,一旦引入横轴(由于图表采用了越靠右越高效的反常规设计,即成本和 Token 越低越靠右),GLM-5.2 [max] 的劣势便暴露无遗:
经济成本陷阱:在 图片1 中,GLM-5.2 [max] 的单次任务平均成本(约 $3.50)显著高于位于其右上方的 gpt-5.5 [medium](约 $2.50)和 claude-opus-4.8 [high](约 $3.00)。它并没有展现出开源模型理论上应有的“价格护城河”。
时间延迟陷阱:在 图2 中,破案了成本高昂的底层原因——GLM-5.2 [max] 平均每项任务要疯狂吐出 80k(8万)个输出 Token,而 GPT-5.5 [medium] 仅需要 25k 左右。大模型生成的物理速度是相对固定的,这意味着使用 GLM-5.2 [max] 的用户,在电脑前等待代码生成的“盲盒时间”是竞品的 3倍以上。
阶段性结论:如果单看商业打榜宣传,GLM-5.2 [max] 是一枚重磅炸弹;但在实际工程落地中,它在商业巨头精细化运营的 Medium 模式面前,显得又慢、又贵、又碎嘴。
二、 根源解密:边际效应递减与“打榜潜规则”
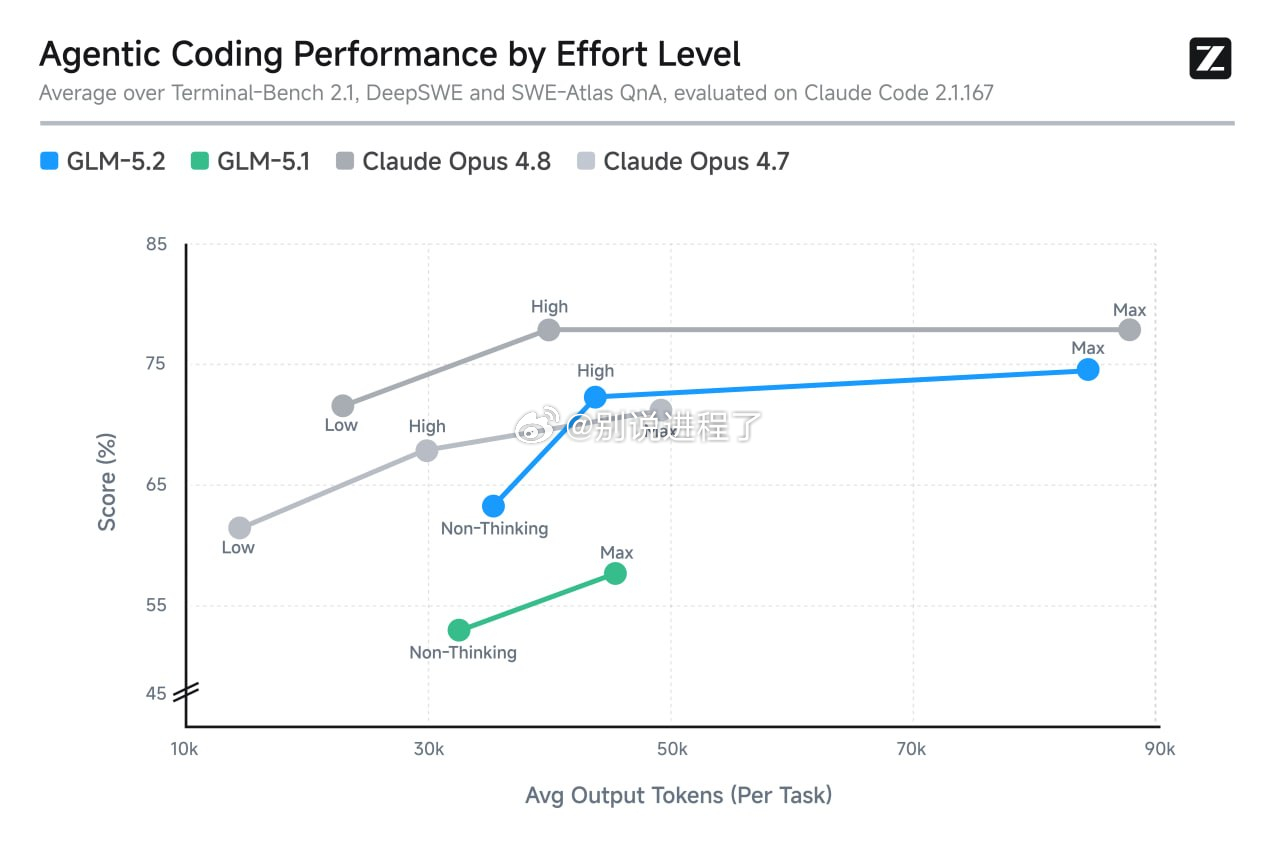
官方博客披露的 图3.jpg(Agentic Coding Performance by Effort Level)则彻底撕开了上述现象的遮羞布,展示了模型在不同“努力程度(Effort Level)”下的性能演进曲线。
1. 边际效应递减(Diminishing Returns)
在大模型引入“思考/推理(Thinking/Reasoning)”机制后,模型的智能和输出量不再是线性的。GLM-5.2 的蓝线展现了完美的边际递减轨迹:
黄金增益区间(Non-Thinking → High):模型从不思考升级到 high 模式,输出 Token 仅温和增长了约 10k(达到 45k 左右),但换来了正确率从 63% 到 72% 的阶跃式暴涨。这是一个极具性价比的爆发点。
无效内卷区间(High → Max):模型从 high 强行拉满到 max 模式,输出 Token 出现了近乎翻倍的恐怖暴增(从 45k 飙升至 85k),但最终换来的分数提升却极其微弱(仅从 72% 蠕动到 74% 左右)。
2. 厂商与用户的利益错位
厂商的逻辑:为了在竞争激烈的市场中拿到最亮眼的公关(PR)通稿,厂商(如 Zai)在参与外部评测或默认宣传时,必然会选择把参数拉满的 max 模式。哪怕多吐一倍的废话、多烧一倍的算力,只要能把 benchmark 的绝对分数刷高 2%,在商业叙事上就是值得的。
用户的逻辑:用户需要的是生产力。在实际开发中,多等一倍的时间去换取 2% 的微弱正确率提升,其边际机会成本是绝对亏损的。
三、 系统总结:如何正确设定预期与打开开源模型
综合三张图表与专业评论,我们可以得出两点最核心的系统性启示:
破除“单价便宜”的迷信: 在 Agent(智能体)和长文本思考时代,评估一个模型的成本不能再只看“每百万 Token 多少钱”(Per M Tokens Price),而必须看“解决单个实际问题消耗的总 Token 量”(Total Volume per Task)。高吞吐、多废话的模型,会迅速吃光单价低的红利。
开源模型的“正确打开方式”: 正如评论者所言,不要被官方宣传里的 max 评分带偏了预期。在实际生产环境里,主动将 GLM-5.2 的努力程度限制在 high(甚至在特定简单任务下限制在 non-thinking),才是真正的“真香法则”。 当我们把 GLM-5.2 降到 high 模式时,它将在保持接近 72% 的顶级工业级正确率的同时,砍掉近一半的输出量和等待延迟。此时,它才真正回归了一个开源模型应有的、足以抗衡闭源巨头的超高性价比前沿。