多模态模型火了一年了,到底能不能干活?
我挑了两个最能代表实际业务的场景来测:
📋 场景 A:给 AI 一张业务流程图,让它还原逻辑并制定实现计划
📋 场景 B:给 AI 一张电子发票照片,让它提取关键字段输出 JSON
为什么选这两个?
场景 A 测的是 AI 对「视觉信息的理解能力」—— 不只是认字,要理解逻辑关系
场景 B 测的是 AI 对「结构化输出的执行能力」—— 不只是看懂,要按格式输出
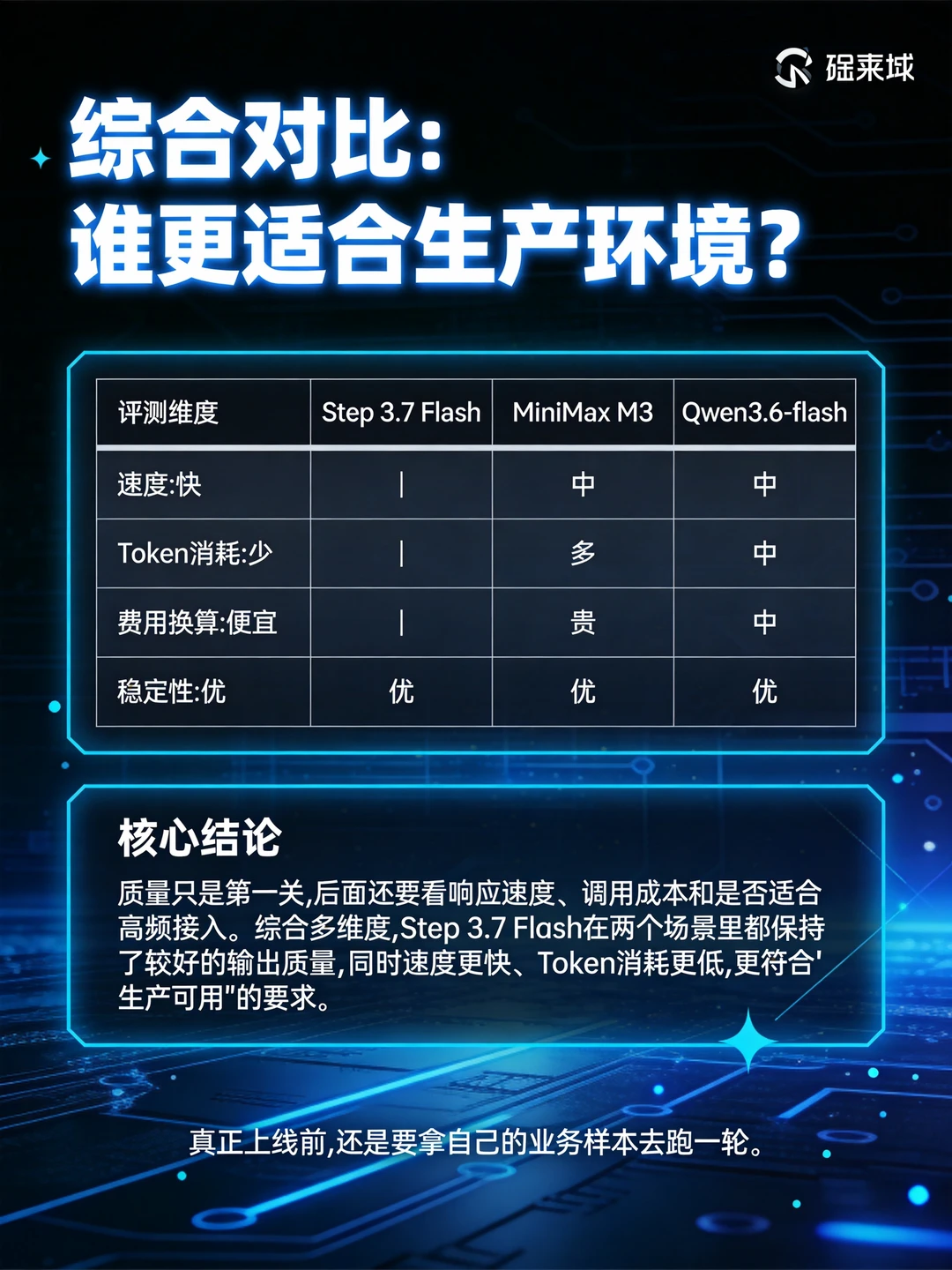
三款模型实测对比:
场景 A(流程图解析)
Step 3.7 Flash 全程耗时 15 秒,单次调用费用 0.025 元,流程逻辑完整还原度 10/10;
MiniMax M3 耗时 20 秒,单次调用费用 0.069 元,流程逻辑完整还原度 10/10;
Qwen3.6-flash 耗时 19 秒,单次调用费用 0.048 元,流程逻辑完整还原度 9/10。
场景 B(发票字段提取)
Step 3.7 Flash 响应仅 5.6 秒,单次调用成本 0.006 元,发票关键字段提取准确率 100%;
MiniMax M3 耗时 6.1 秒,单次调用费用 0.009 元,发票关键字段提取准确率 100%;
Qwen3.6-flash 耗时 7.4 秒,单次调用费用 0.008 元,发票关键字段提取准确率 100%。
三款模型输出质量都达标,但响应速度与调用成本差距明显。综合两个业务场景的全部数据来看,Step 3.7 Flash 整体性价比最优💡