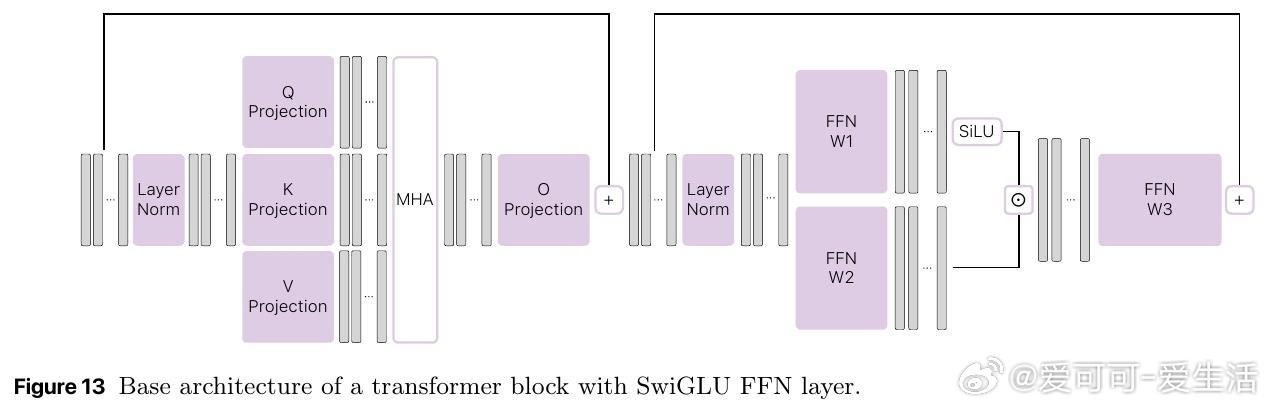
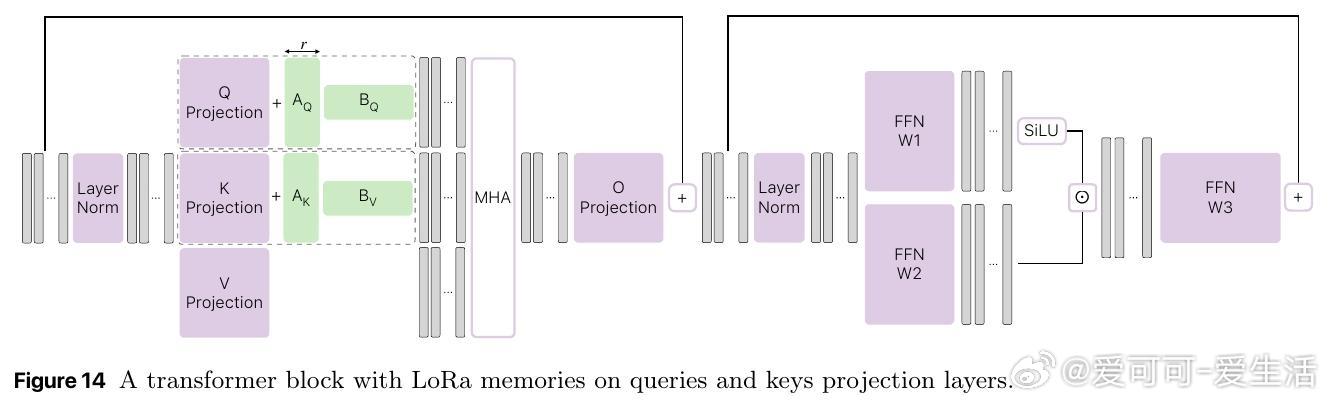
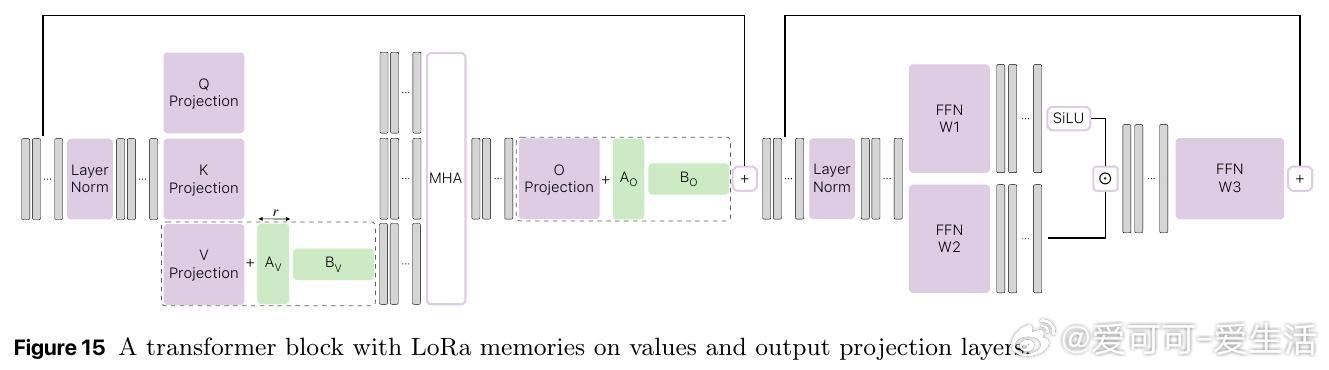
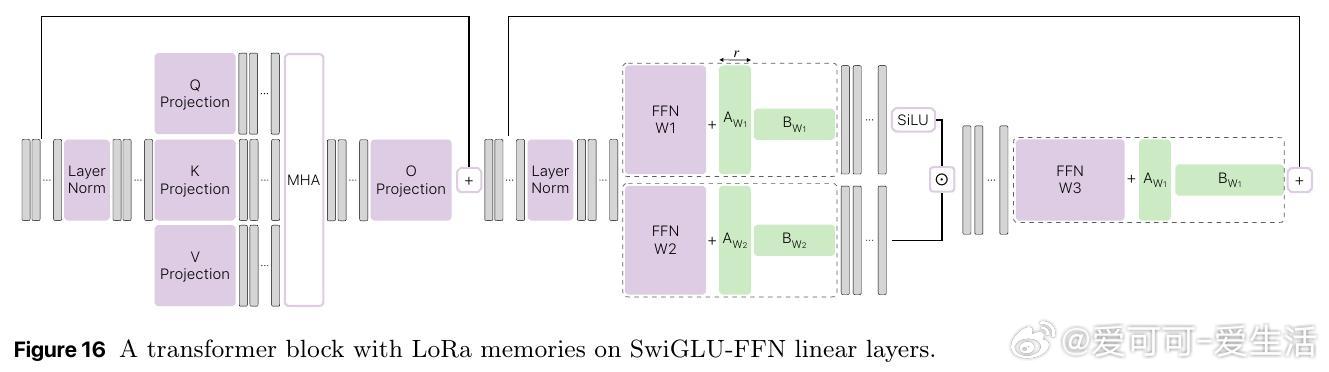
[CL]《Pretraining with hierarchical memories: separating long-tail and common knowledge》H Pouransari, D Grangier, C Thomas, M Kirchhof... [Apple] (2025)
预训练新突破|层级记忆助力语言模型高效掌握长尾知识
现代大语言模型(LLM)性能提升多靠参数规模扩大,但全面压缩世界知识进模型参数既不必要也不实用,尤其是边缘设备受限于内存和计算资源。苹果团队提出“带记忆的预训练”新架构:
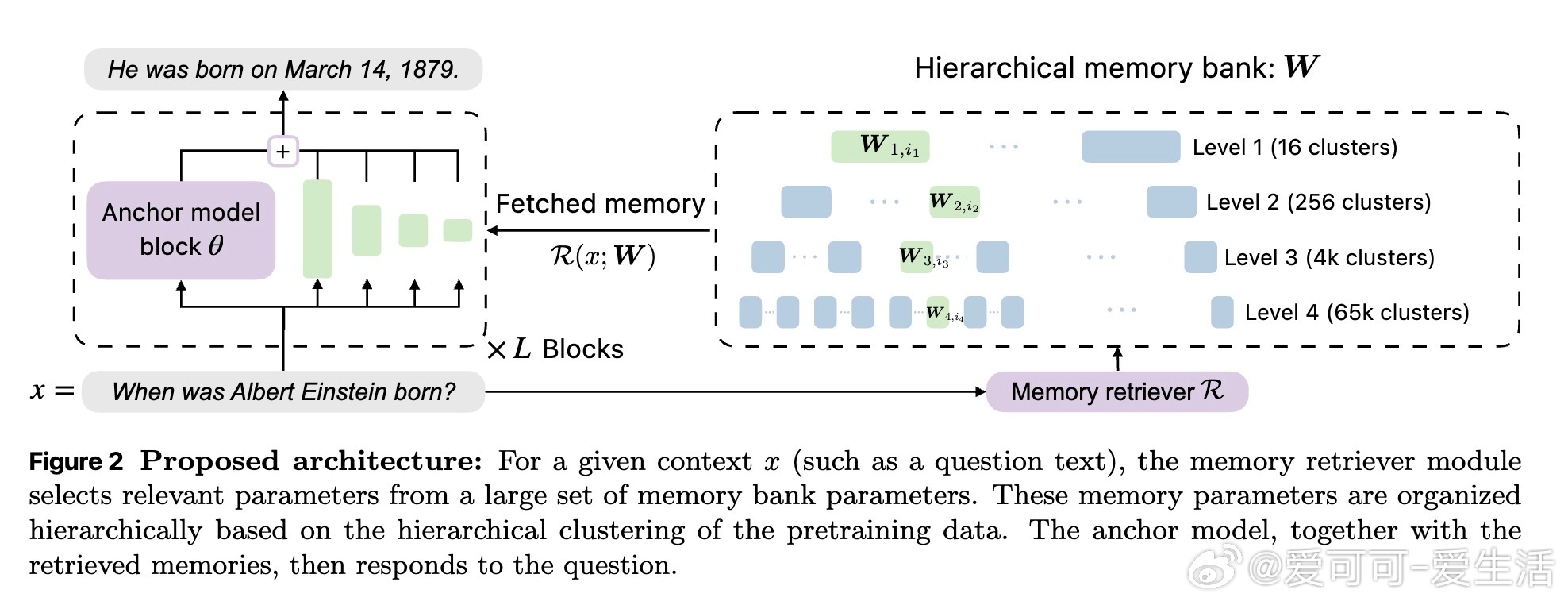
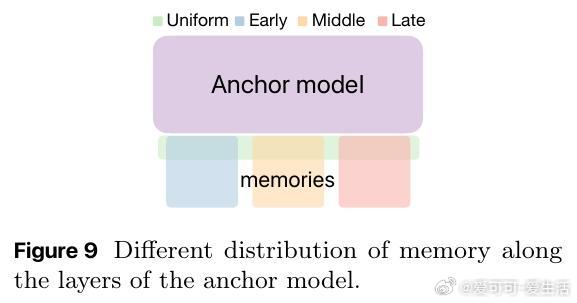
🔹核心思路:用小型“锚模型”负责常识和推理能力,配合超大层级记忆库存储长尾知识。推理时只调用与上下文相关的记忆块,极大节省资源。
🔹技术亮点:
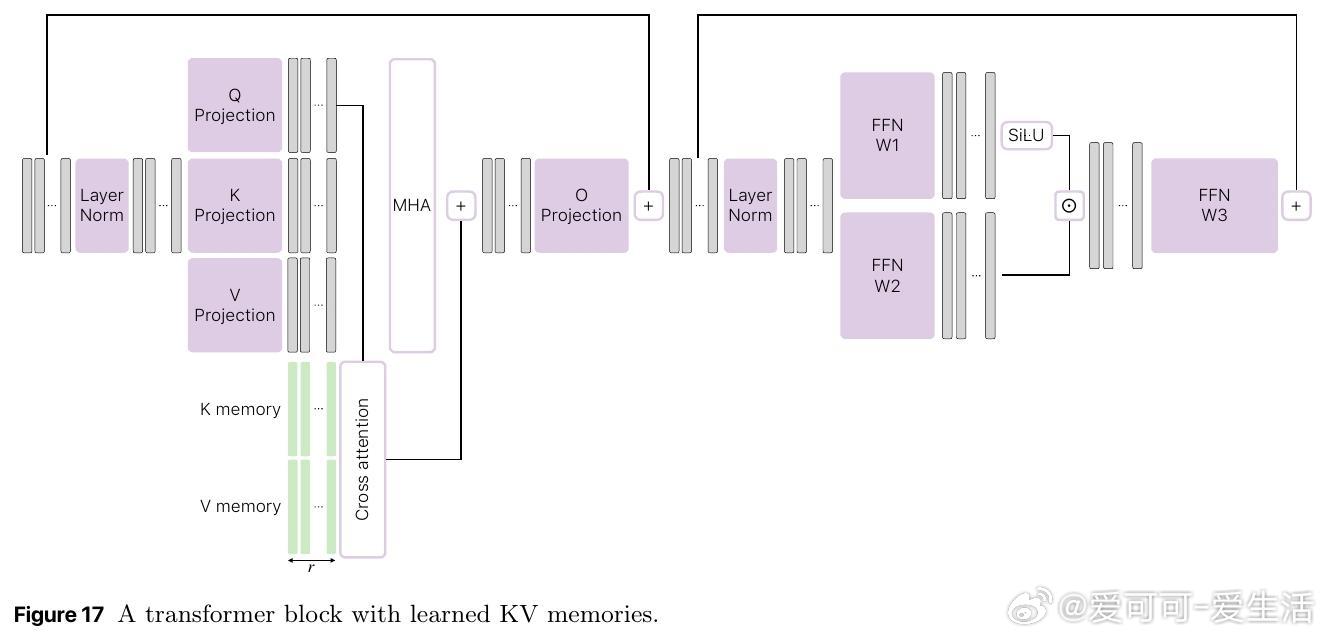
- 采用层级聚类对海量训练文档分层存储记忆参数(多达210亿参数),实现语义相关记忆稀疏激活,缓解遗忘问题。
- 记忆参数仅对相似内容激活更新,锚模型捕获通用知识。
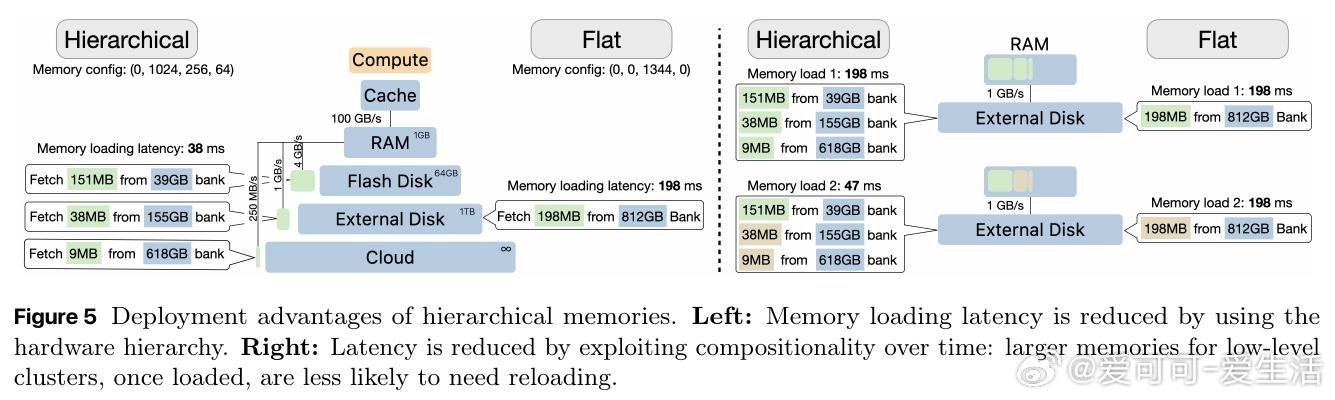
- 记忆结构天然适配硬件层级存储(RAM→闪存→外部硬盘),提升加载效率和推理速度。
- 支持隐私保护和知识编辑:可针对特定记忆块进行删除、更新,甚至实现私有知识动态扩展。
🔹实验效果:
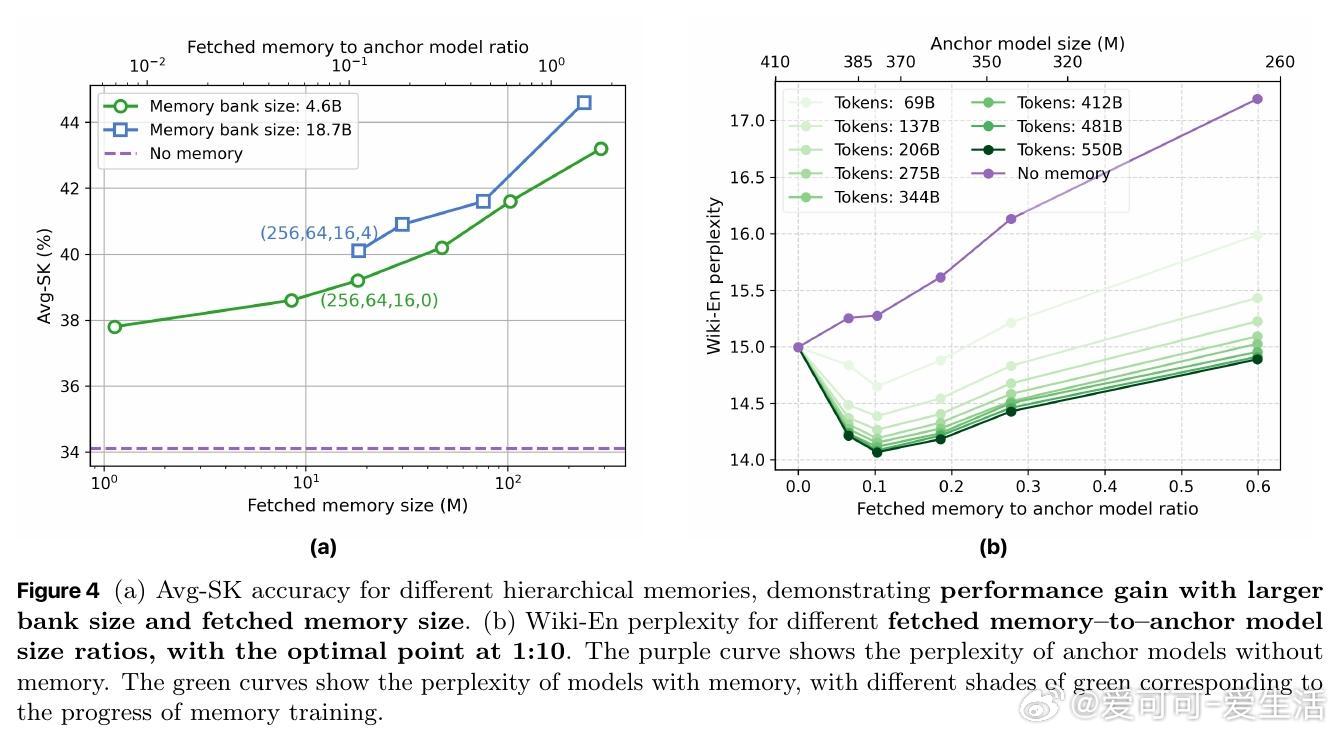
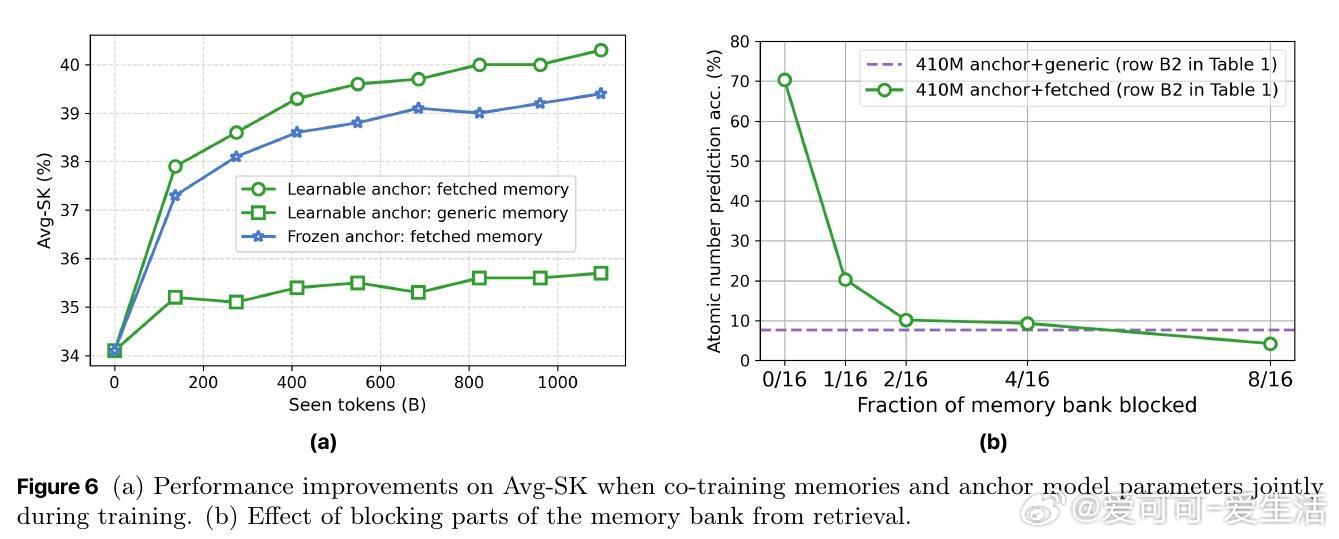
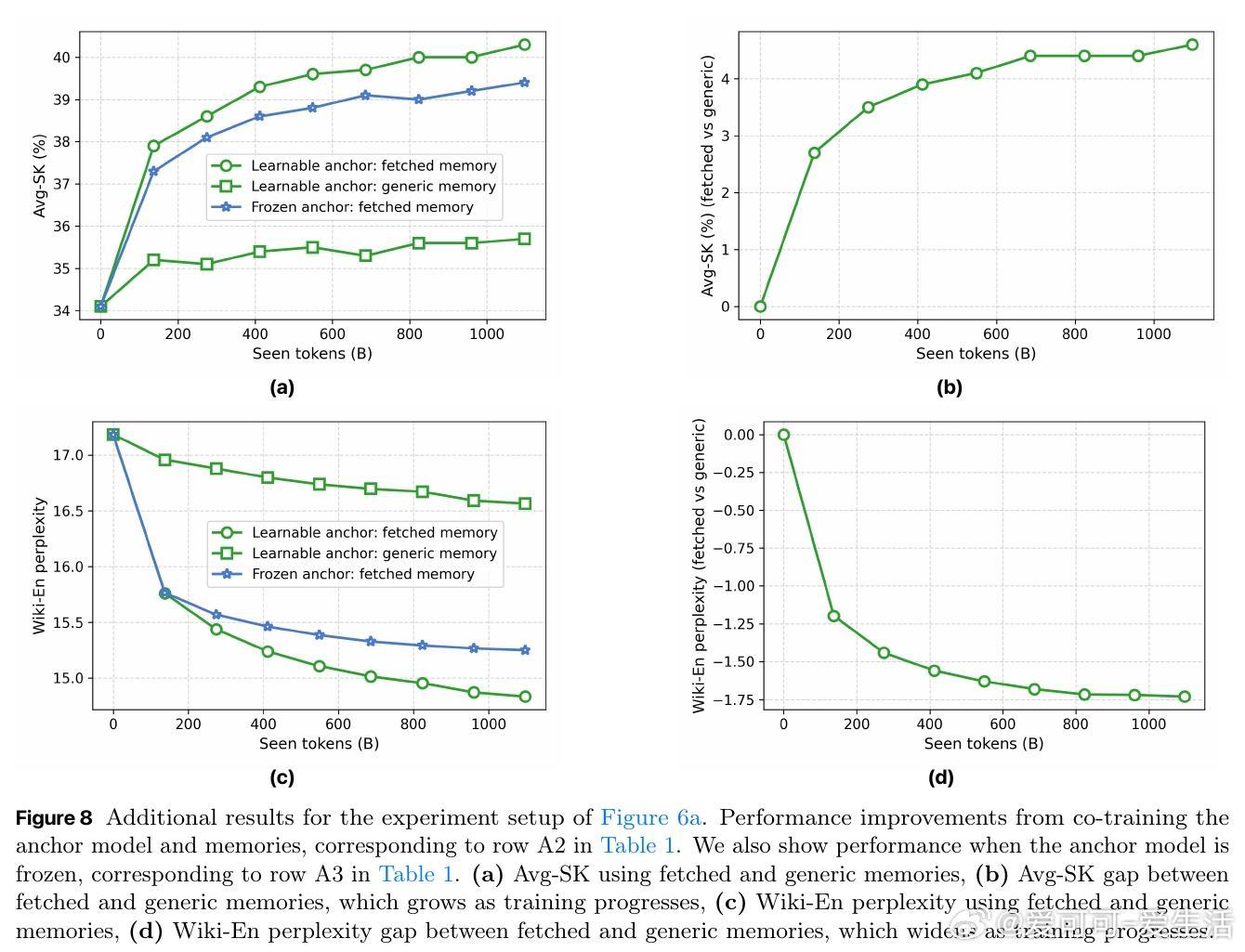
- 仅用160M参数的锚模型+18M记忆参数(从46亿参数记忆库检索)即可匹敌常规410M参数模型性能;
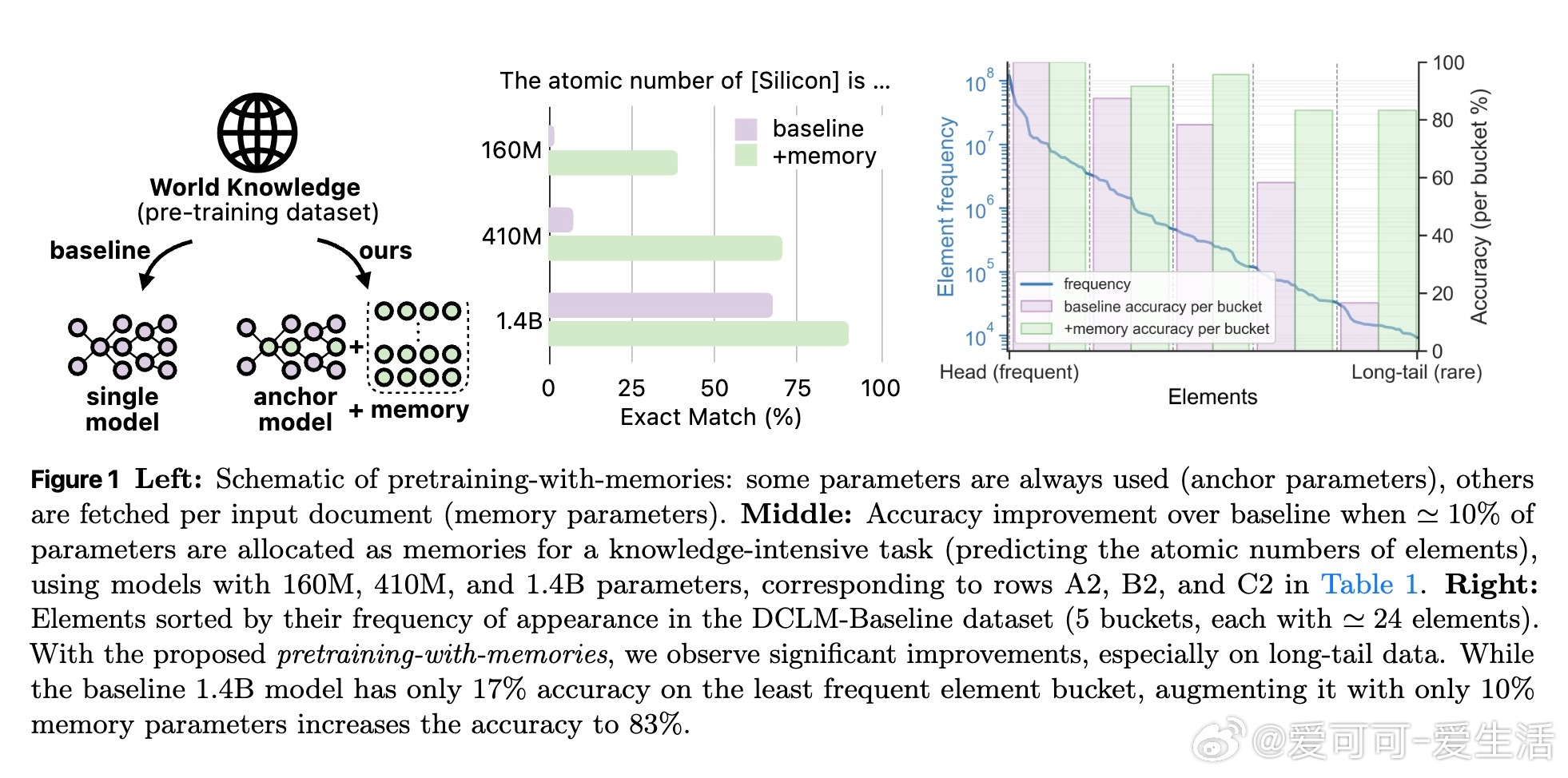
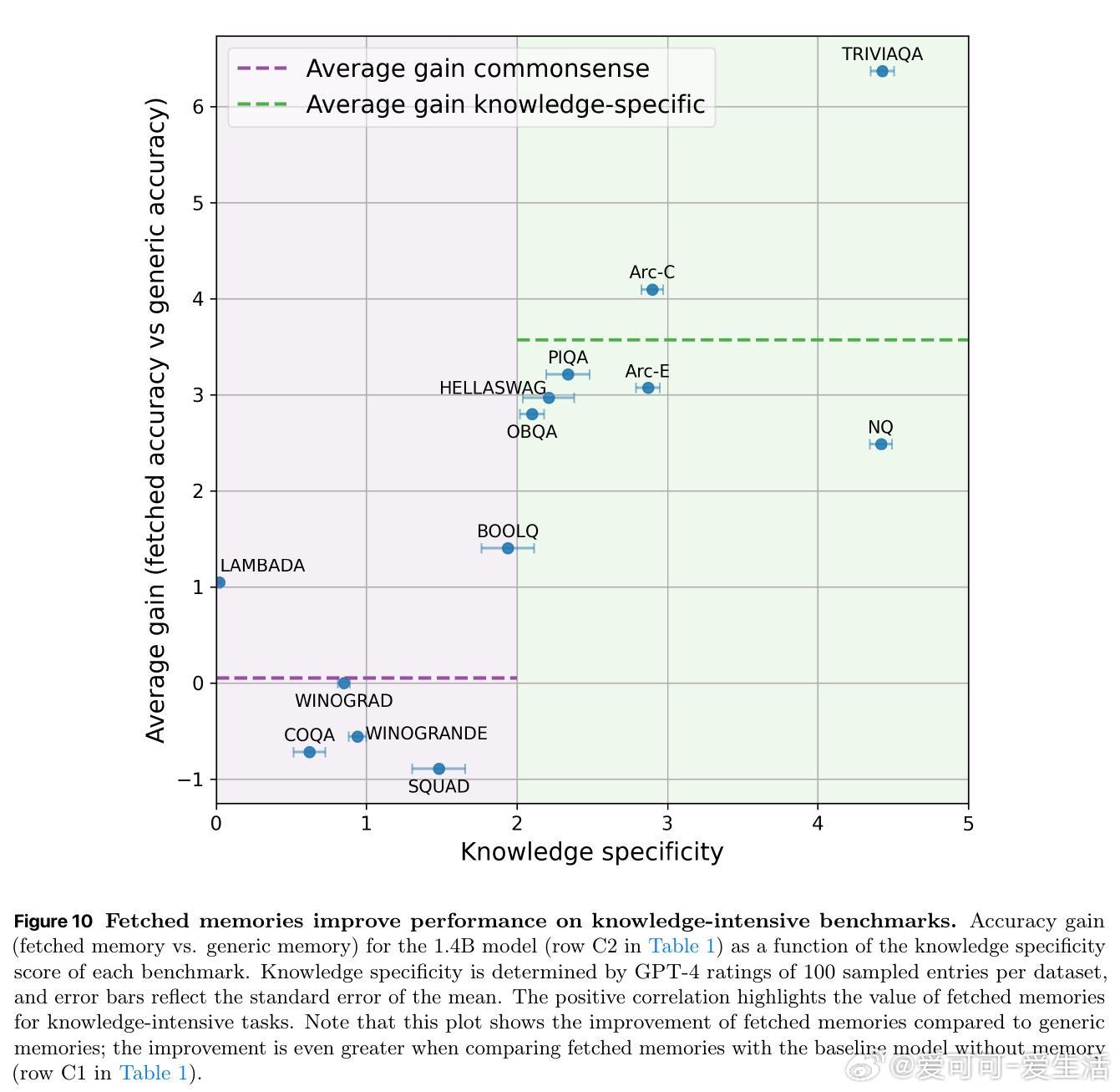
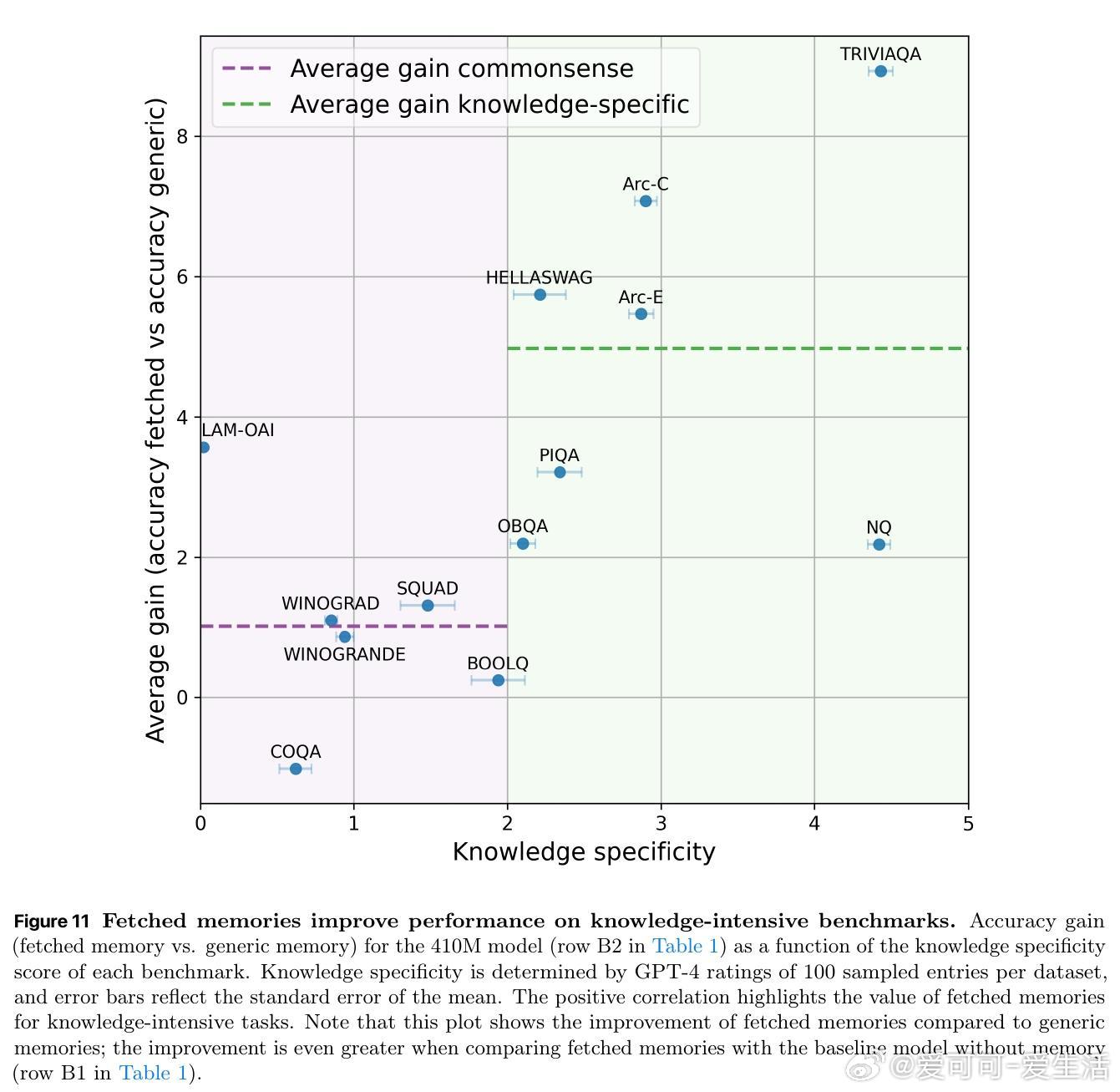
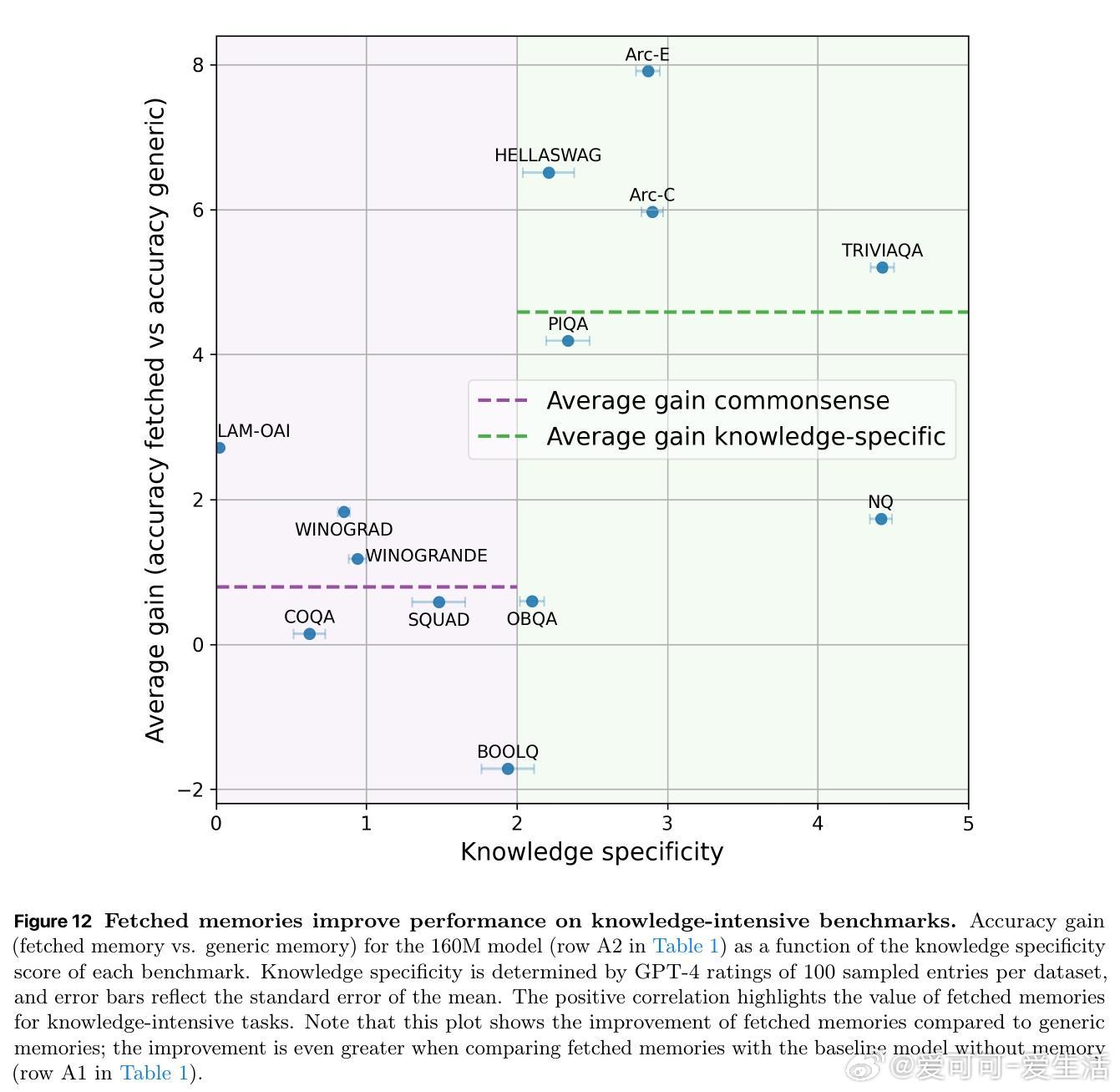
- 层级记忆对知识密集型任务(如元素原子序数预测)提升明显,尤其对低频长尾知识准确率提升超4倍;
- 同时提升了推理效率和训练通信效率,适合大规模分布式训练。
🔹探索与未来:
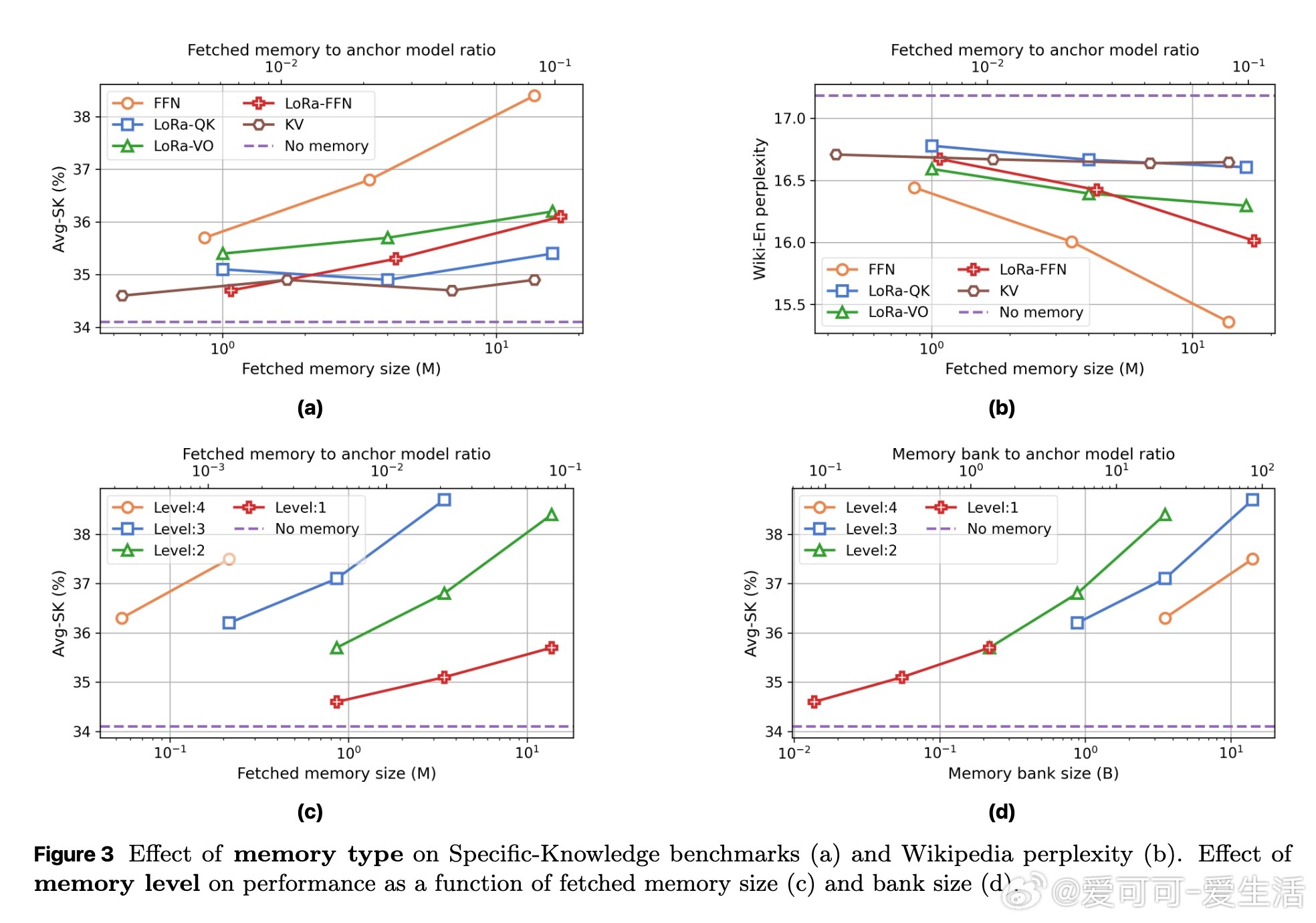
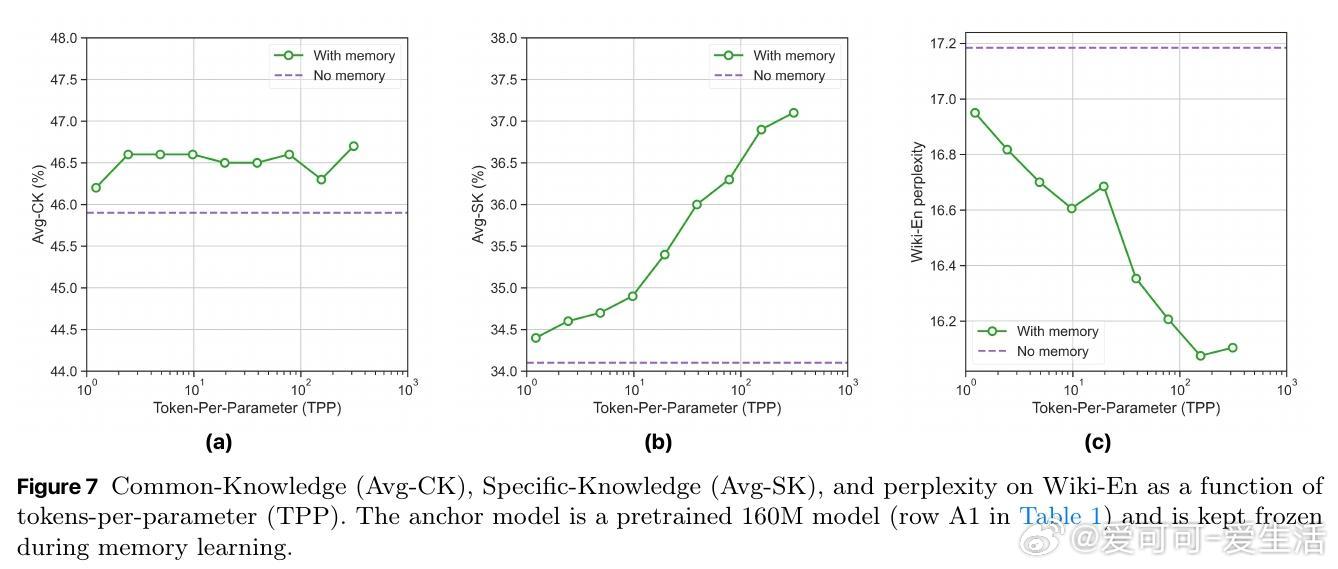
- 详细分析不同记忆类型(FFN记忆表现最佳)、层级深度、大小配置对性能的影响;
- 支持后期给开源模型(如Llama、Qwen)无缝加记忆提升能力;
- 未来将探索多语言和多模态扩展、记忆学习的规模定律等。
这项研究从根本上重新定义了知识与推理的模型结构分离,为边缘部署和大规模知识更新开辟新路径。
📄 阅读原文详解:arxiv.org/abs/2510.02375
大语言模型 预训练 机器学习 人工智能 知识存储 边缘计算 苹果AI