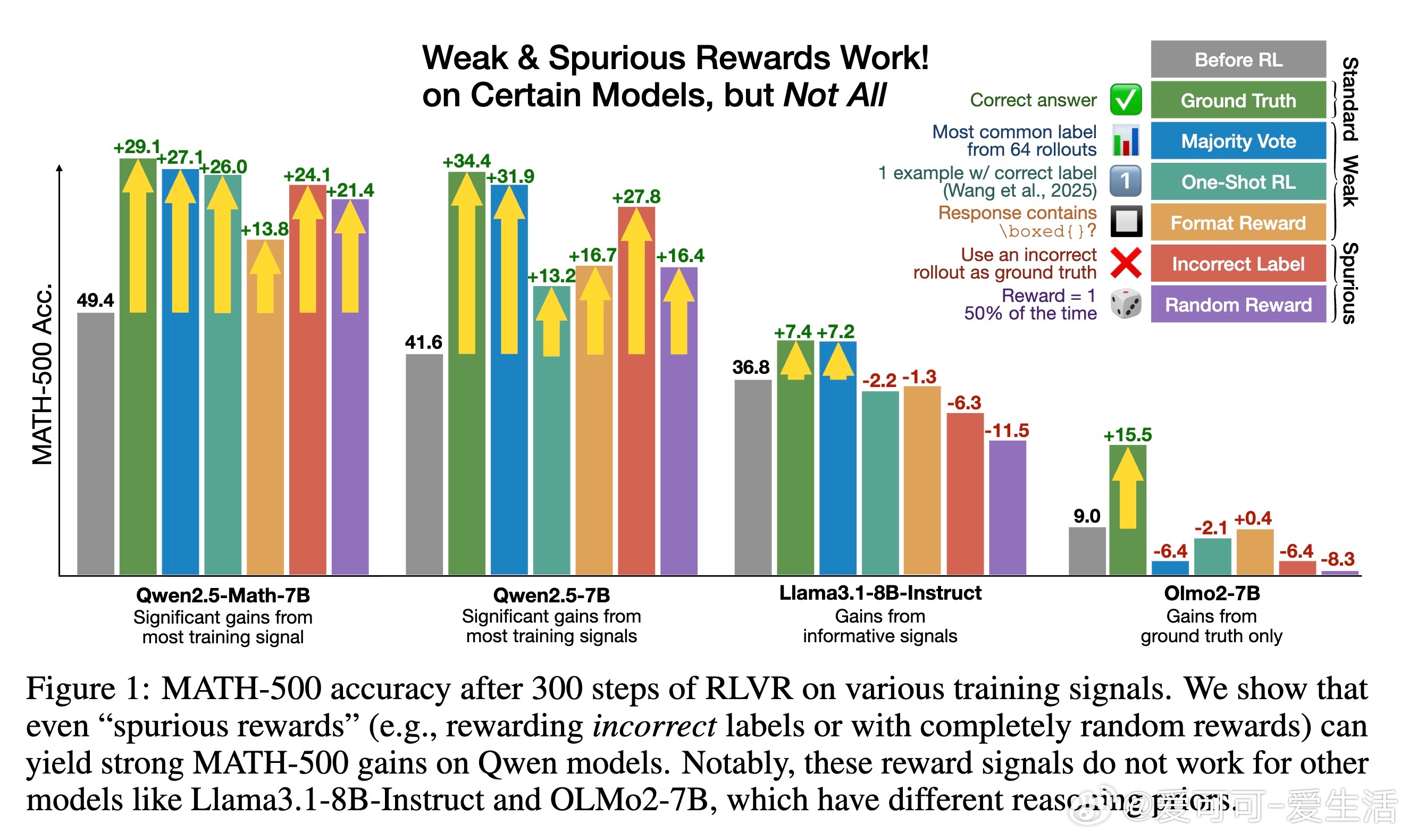
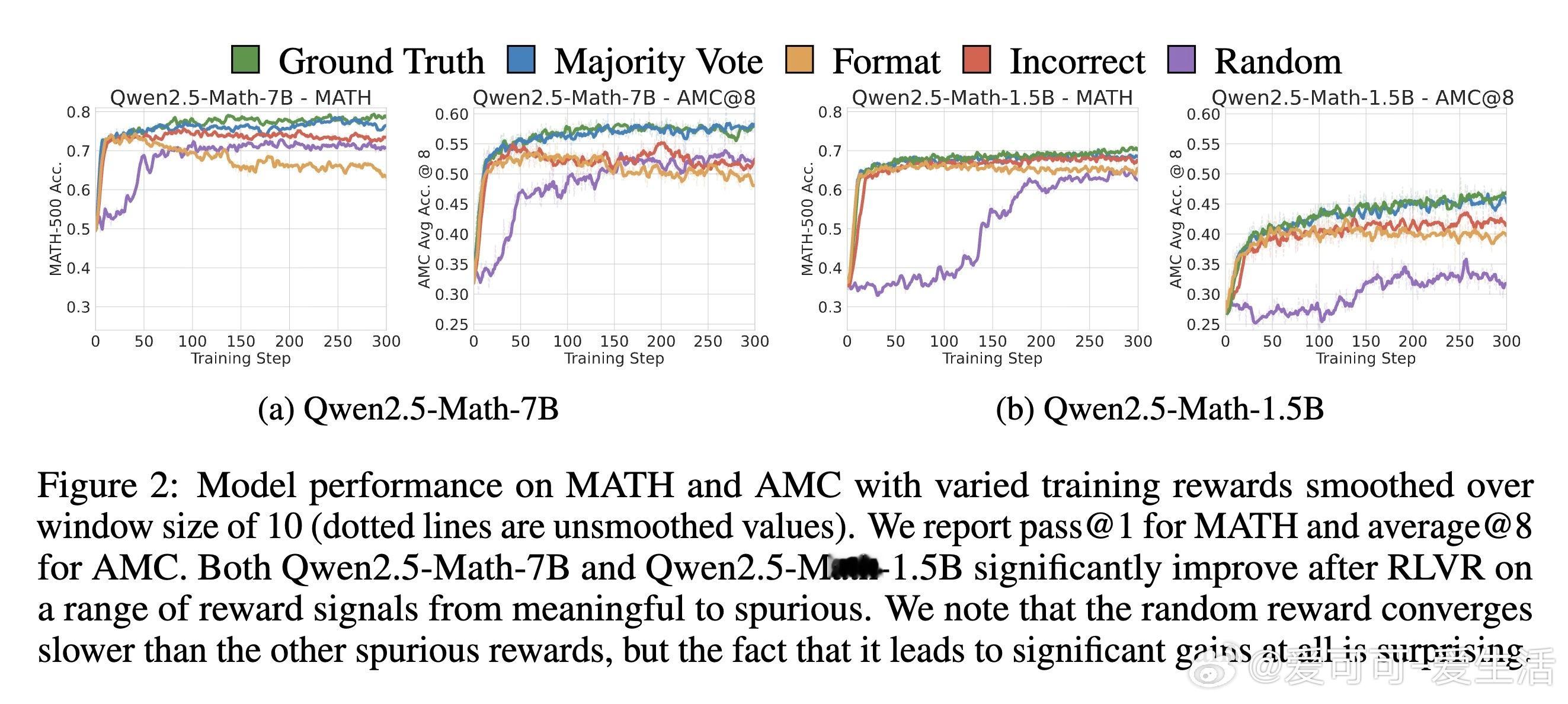
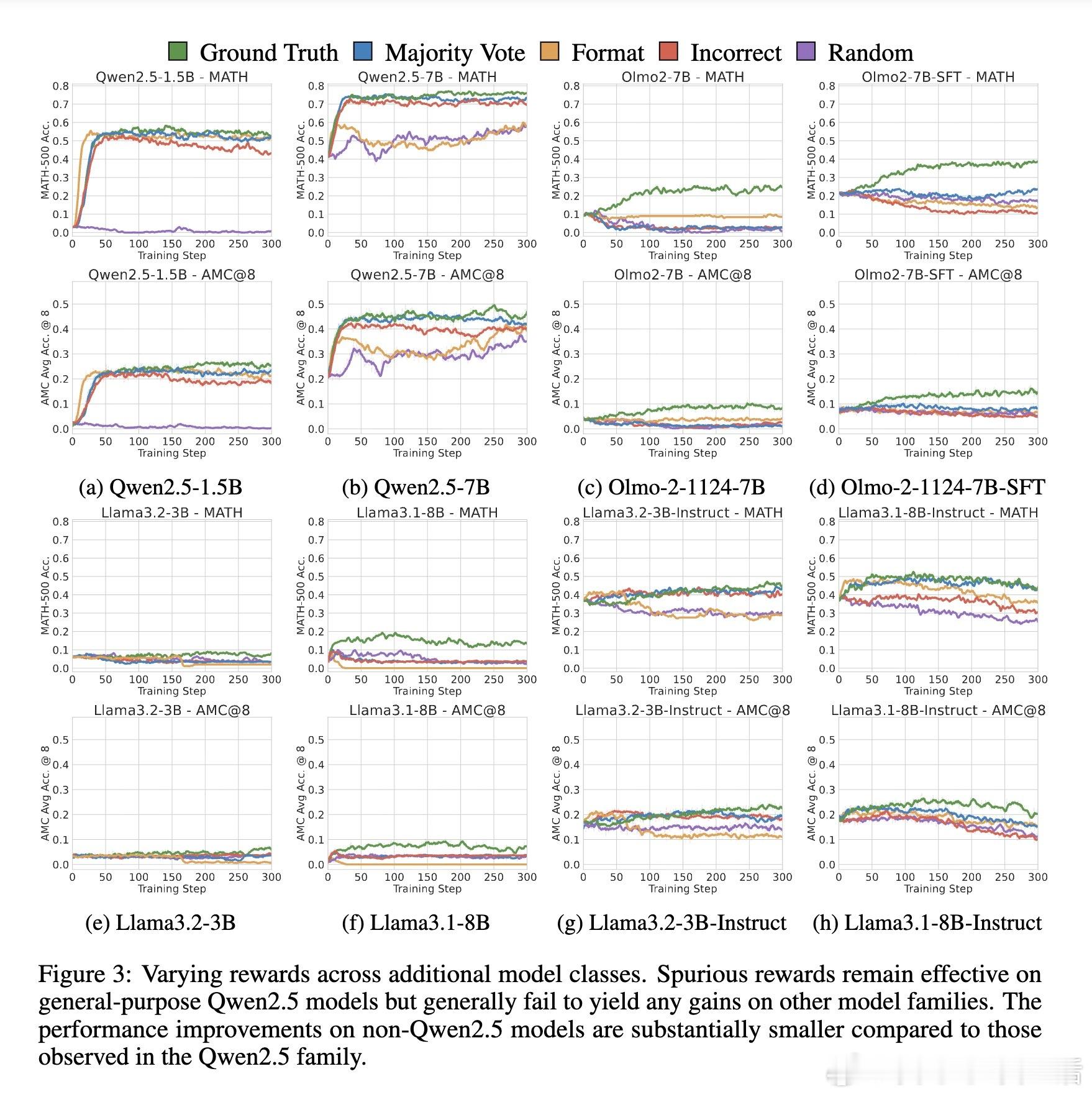
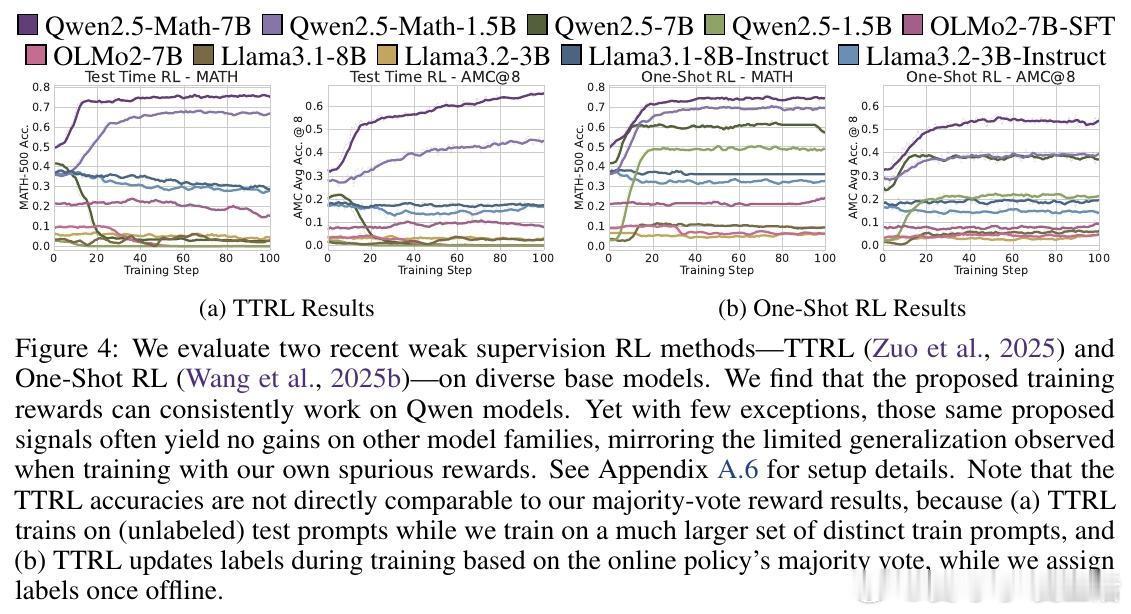
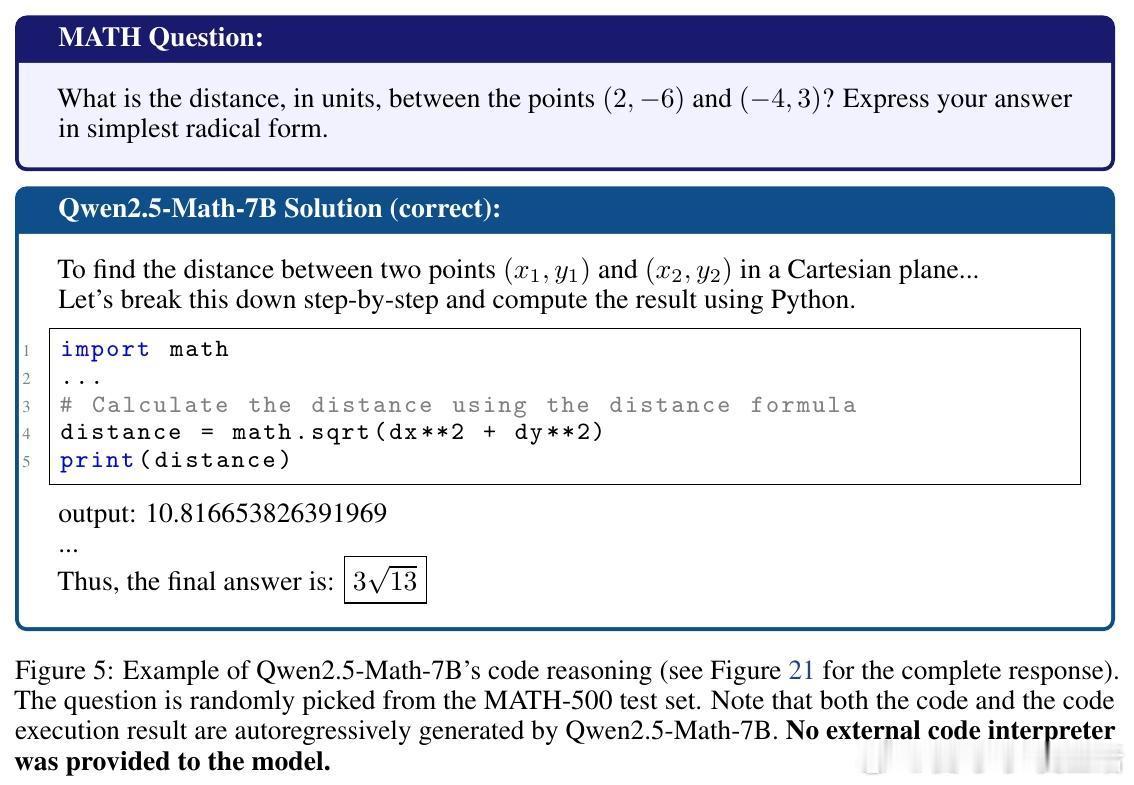
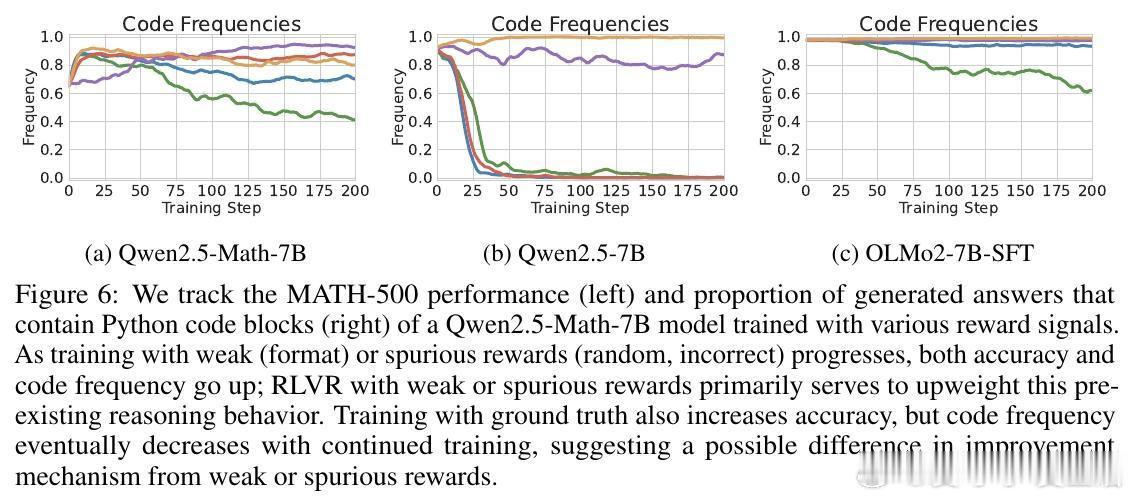
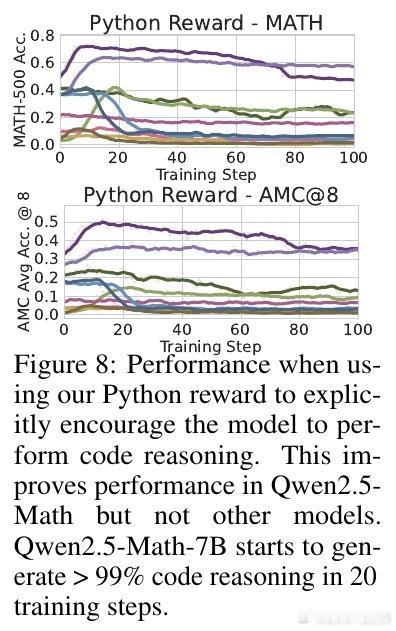
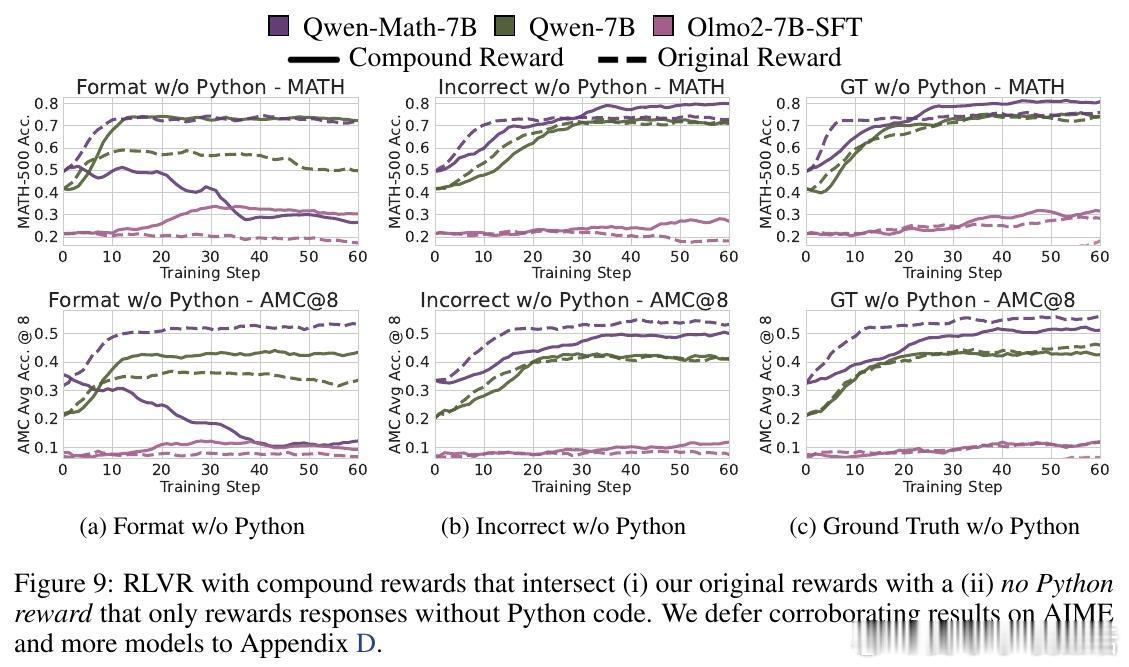
[LG]《Spurious Rewards: Rethinking Training Signals in RLVR》R Shao, S S Li, R Xin, S Geng... [University of Washington] (2025) 强化学习在数学推理领域的成功,或许并非完全源于精准的奖励反馈,而是一场关于唤醒潜能的奇妙实验。最近一项关于RLVR(可验证奖励强化学习)的研究揭示了一个反直觉的现象:即便给模型提供完全随机、仅看格式、甚至完全错误的奖励信号,Qwen2.5-Math等模型依然能在数学竞赛题目上取得惊人的进步。以下是这项研究带给我们的深度思考与技术启发:1. 奖励信号的幻觉在传统的认知中,强化学习依赖于准确的对错反馈。然而实验显示,Qwen2.5-Math-7B在接受随机奖励时,其MATH-500的准确率提升了21.4%;在接受错误标签奖励时,提升了24.1%。这几乎逼近了使用正确标签训练带来的29.1%的涨幅。这意味着,对于某些模型而言,奖励信号有时只是一个启动开关,而非导航地图。2. 预训练决定的天花板这种乱发奖也能提分的奇迹并非普适。研究发现,同样的随机奖励在Llama3.1或OLMo2上几乎毫无作用,甚至会导致性能下降。这说明RLVR的效果高度依赖于模型在预训练阶段积累的知识底蕴。如果模型本身没有埋下推理的种子,再多的强化也开不出花。3. 隐藏的利器:代码思维为什么Qwen系列表现如此特殊。研究者发现,Qwen在预训练中习得了一种独特的代码思维。即便没有代码执行环境,它也会在推理过程中自动生成Python代码辅助思考。RL训练的过程,本质上是把这种高效的推理表征从模型的深处打捞出来。当代码思维的频率从65%提升到90%以上时,模型的逻辑能力也随之跃迁。4. 强化学习的本质是筛选而非创造这项研究提出了一个深刻的假设:当前的RLVR技术可能并没有教会模型新的推理能力,而是在庞大的概率空间中,通过某种机制(如GRPO的裁剪偏差)将模型预训练中已经学会的高质量路径筛选并固化了下来。5. 对研究者的警示目前开源社区过度依赖Qwen模型进行RLVR研究。但由于Qwen对噪声奖励具有极强的鲁棒性,很多看似有效的创新算法,可能只是吃到了模型底座的红利。未来的研究必须在更多样化的模型家族上进行验证,才能区分什么是算法的功劳,什么是底座的恩赐。启示:- 奖励信号有时只是噪音,真正的力量早已埋藏在预训练的深处。- 强化学习不是在荒地上盖楼,而是在森林里开路。- 优秀的模型底座,本身就具备自我修正的逻辑惯性。论文链接:arxiv.org/abs/2506.10947