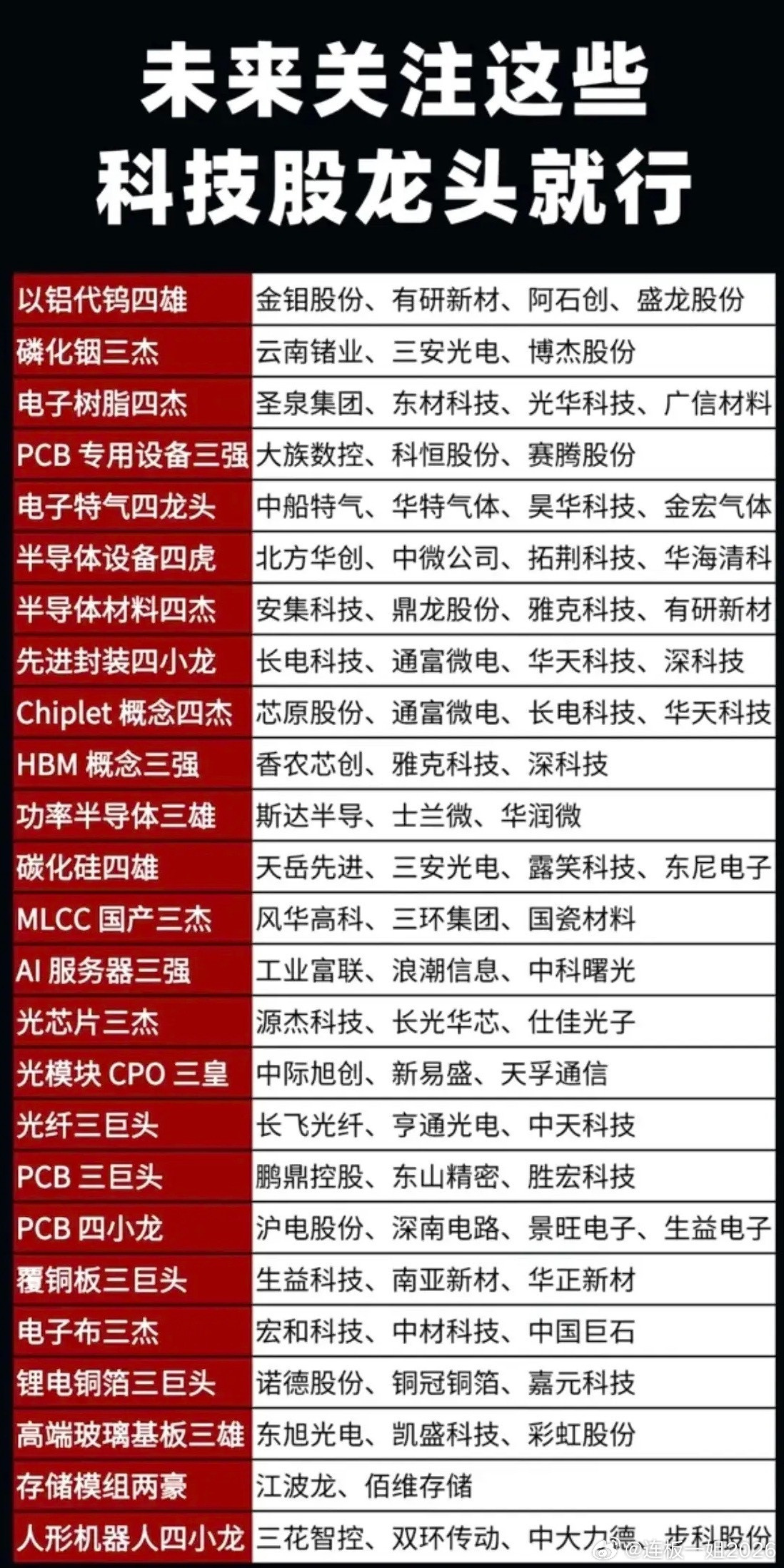
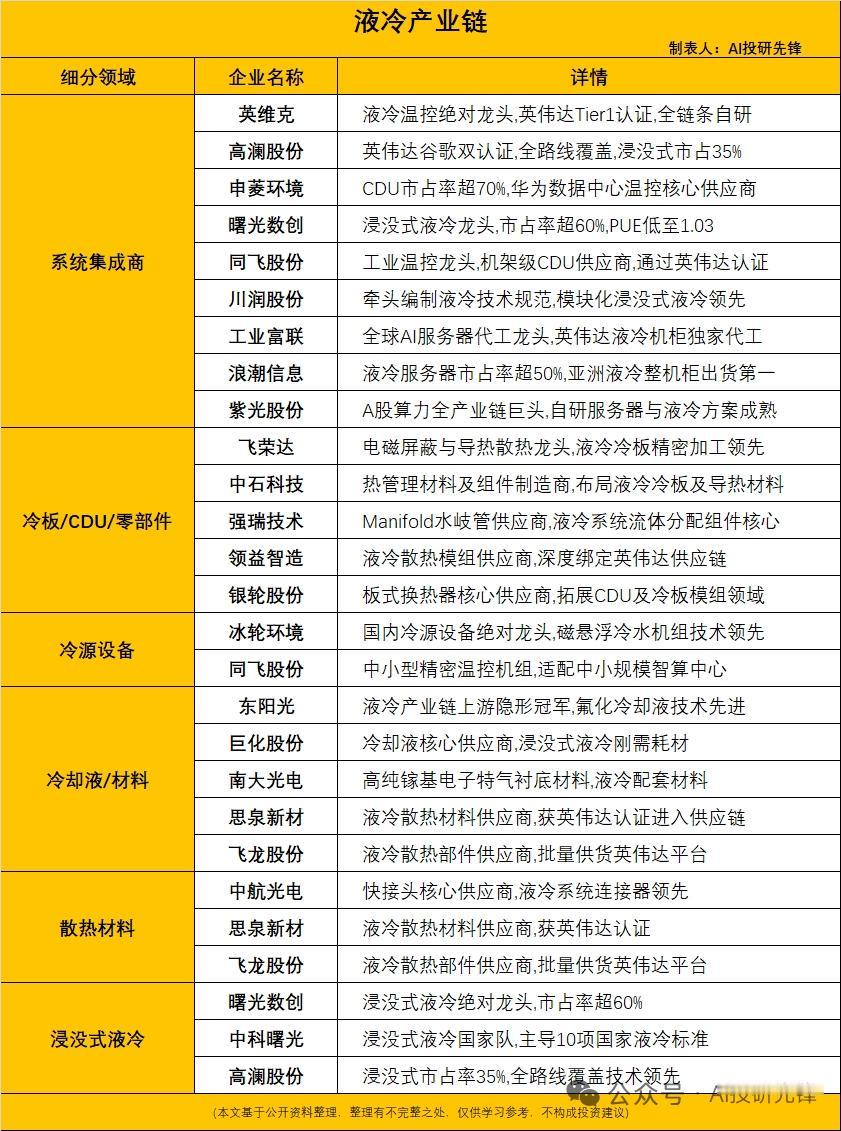
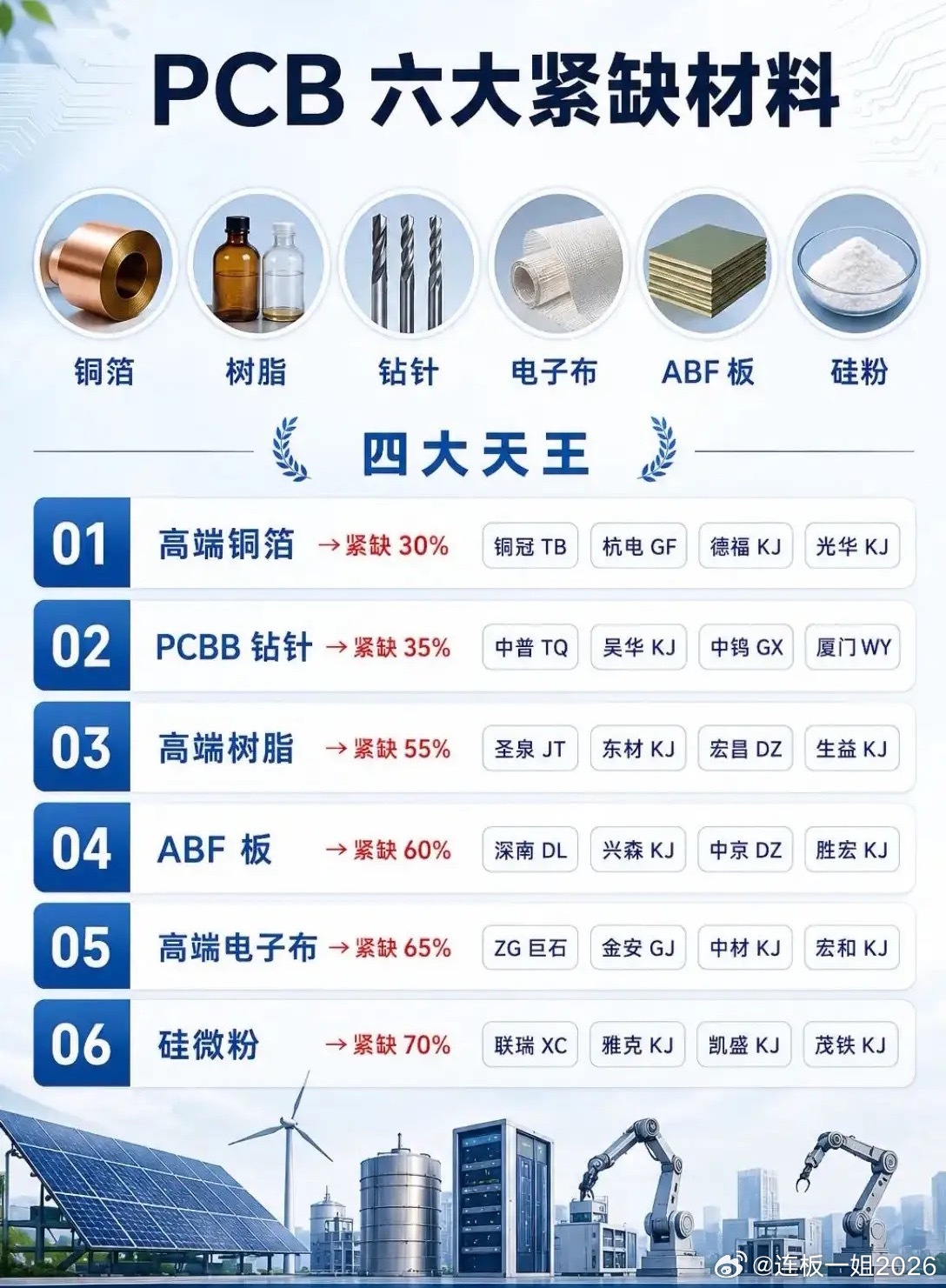
朋友们好,我是烽屿。
美国商务部曾限制中国购买高端AI芯片,但中国AI大模型运行却愈发顺滑,上周中国AI大模型周调用token量达18.42万亿,稳居全球第一。
芯片被卡脖子,算力反而实现逆袭,背后是中国工程师重构算力体系的底层逻辑。过去算力领域迷信单高端芯片的“大卡车”模式,而中国转向“车队+调度”的协同思路。

把小算力资源整合起来统一调度,让每一份算力都满负荷运行,几百台小算力设备的总运力未必输单一高端芯片。
中兴ZTE26530G3服务器就是这种思路的体现,它能插20个单宽GPU且不限品牌,通过技术手段压榨每一块GPU的性能,让小算力资源发挥最大价值。
 调度破局
调度破局光有车队还不够,还需打通数据迁移、传输、存储等隐形环节。中兴的“5加X协同设计”让算力资源像货运网络一样智能调度,拥堵时绕道,仓库空时优先配送。

每个环节提升15%效率,五个环节叠加总效率超30%。这种优化在金融场景中尤为关键,银行每天几亿笔交易,合规风控、反欺诈都依赖AI,算力底座直接决定AI的运行能力。
现在银联、六大行、12家股份制银行都用这套逻辑训练AI,头部证券和保险也开始规模化部署,信贷审批从3分钟变成毫秒级响应。
 超级节点
超级节点为解决算力集群的“拥堵”问题,中国工程师进一步创新,推出中兴OEX超节点。
传统GPU服务器靠网线连接容易负载拥堵,OEX采用零线缆设计,缩短信号路径30%,就像把国道变成高速轨道。
同时,机柜的GPU容纳量从60个翻倍到128个,密度提升却省电37%,大幅降低成本。
更重要的是,OEX支持多品牌芯片混集群,英伟达、AMD、海光DCU都能协同工作,打破了单一芯片生态的限制,让算力像水电一样自由汇入网络,系统自动分配资源。

这套技术支撑下,中兴方案能组建16384个GPU的超级万卡集群,过去只有顶尖巨头敢想的事现在轻松实现。
训练千亿参数大模型的时间从6个月缩短到1个月,这正是国产大模型越来越顺滑的根本原因——不是买到高端芯片,而是重构了算力体系的底层逻辑。

中国算力的逆袭不是简单替代高端芯片,而是换道超车。通过车队协同、智能调度和技术创新,中国不仅解决了芯片被卡的问题,还建立起全球领先的算力能力,支撑金融命脉和AI产业的独立自主。