过去这一年,行业里最不缺的就是惊艳的Demo和跑分霸榜的模型,但真到了要交付的时候,往往还是一看就会,一做就废。画质经不起大屏审视、长镜头全靠抽卡盲盒、音视频图文工具各玩各的没法协同……
火山 FORCE大会我看完了,这次发布了豆包大模型家族的新升级,可以说是完全踩在了这个趋势的节点上,没有去卷虚头巴脑的概念。
说下最核心的视频线,也是我这次比较关注的Seedance系列。2.0版本直接上了原生4K,我身边不少接商单的朋友都吐槽过,以前的AI视频小样看着还行,一交付就露馅。靠后期超分硬拉的分辨率,发丝、面料纹理一推近就发糊。这次原生4K加10bit 高位深直出,等于从生成源头就把画质底线拉到了工业级,导出来直接就能进专业后期流程,不用先花大半天补画质的窟窿。
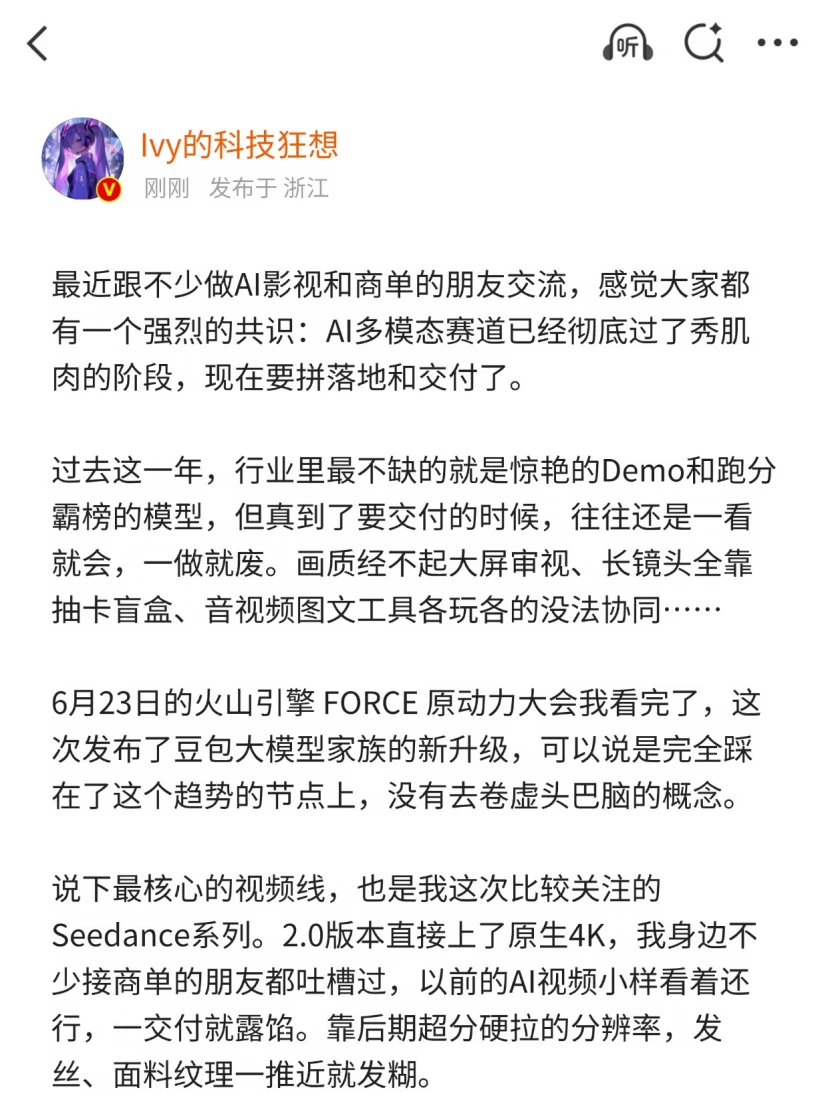
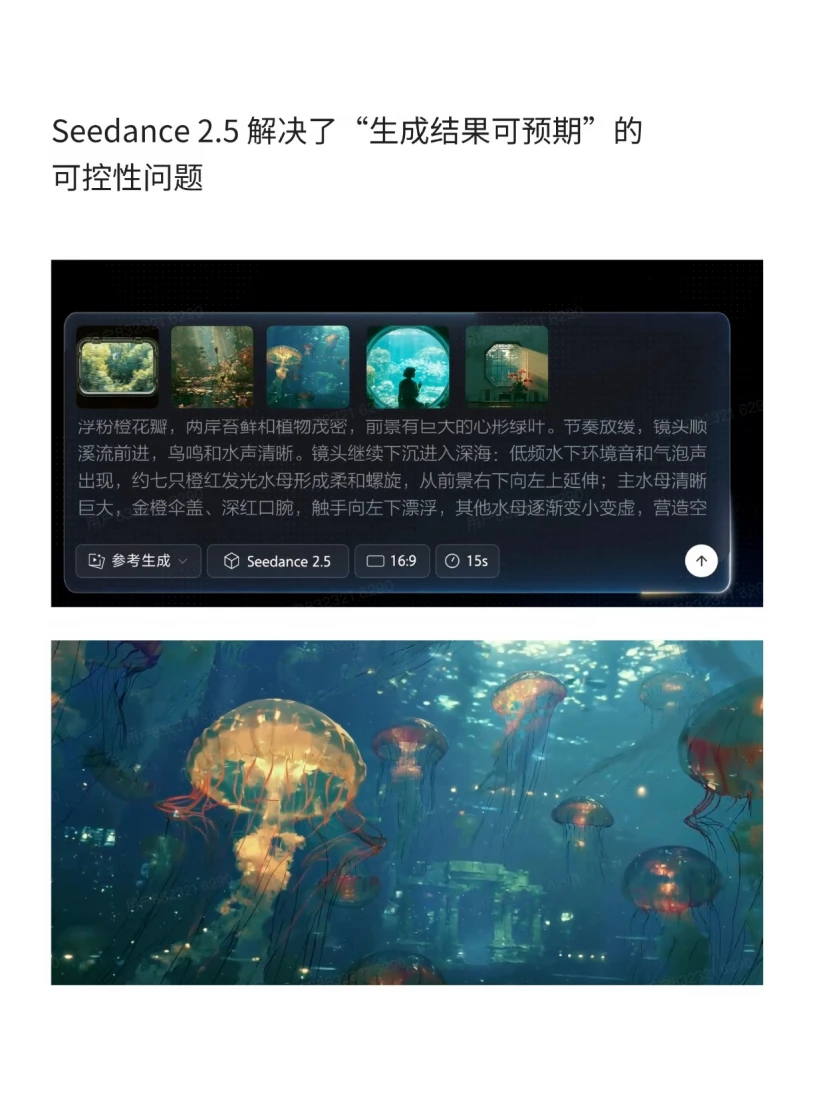
Seedance 2.5,解决的是另一个更磨人的痛点,可控性。做AI视频的都懂哈,长镜头只能拆成几段生成再拼接,光影和人物动不动就穿帮,想改个局部细节就得整条重跑,抽卡成本高得离谱。现在能直出30秒完整镜头,还支持局部编辑,大画面不动,单独换个人物、改个商品都可以。生成结果终于不是开盲盒了,真的要结果可预期,才敢真的用到商用项目里。
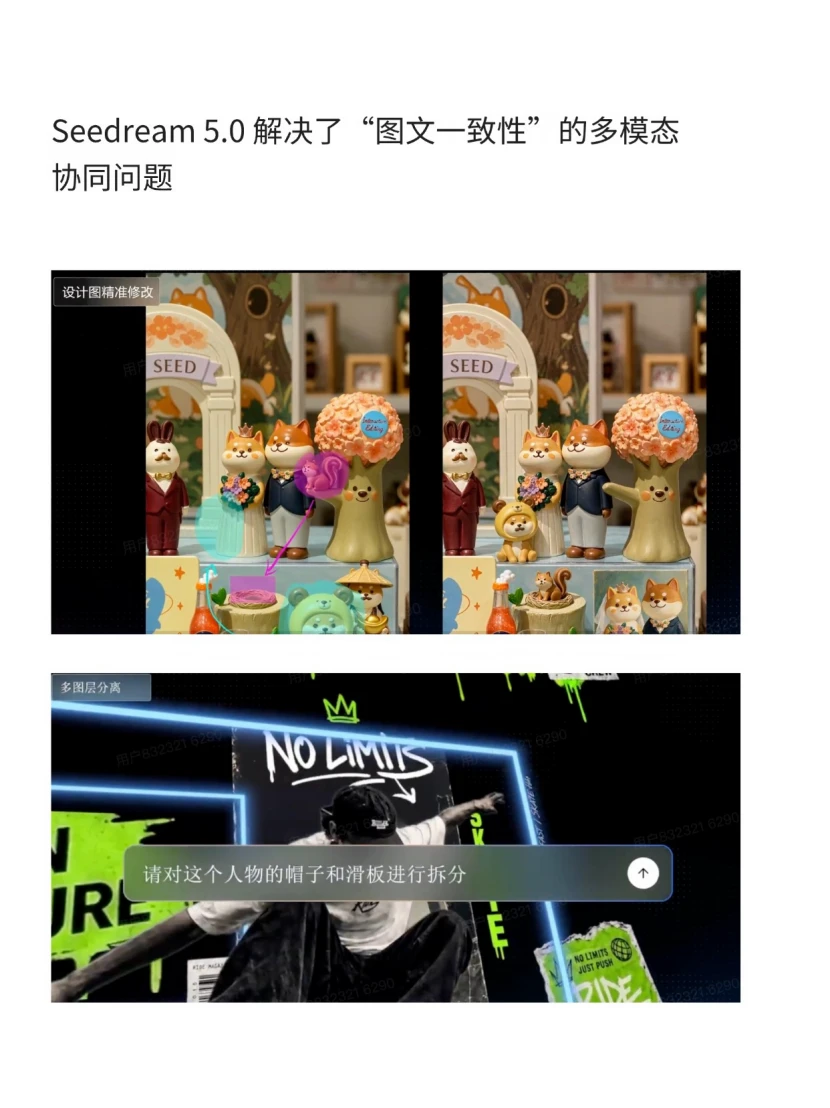
光视频能打还不够,全链路得打通吧。Seedream 5.0 Pro就把图文端的短板也补上了,支持直接在画面上框选编辑、任意分层拆解,连PPT和信息图这种高密度文字内容都能生成得精准清晰,还能直接对接Seedance转视频。同体系出的素材,风格一致性有保障,不用跨好几个工具来回磨合。
最后补上闭环的就是豆包音频生成模型1.0了,不再是单句配音的小工具,一条指令就能把多角色对白、情绪语气、背景音乐和环境音效一次性端到端生成。长内容音色也稳,省了分轨混音和逐句对齐的一堆麻烦。
其实现在不少厂都在做多模态,但大多是单点各玩各的。我觉得火山引擎这次真正的厉害之处,是视频、图像、语音四块生产力同时落地,打的是一套工程化的组合拳。
行业以前比的是谁的上限更高、样片更炸,现在拼的是谁的下限更稳、流程更顺。总之,火山引擎这一波已经把整套生产工具的实用性拉满了,这真的是实打实的差距哈。