[LG]《Front-Loading Reasoning: The Synergy between Pretraining and Post-Training Data》S N Akter, S Prabhumoye, E Nyberg, M Patwary... [NVIDIA & CMU] (2025)
🔍 研究焦点:
- 大语言模型(LLMs)推理能力提升,传统侧重后期高质量推理数据的微调(SFT)。
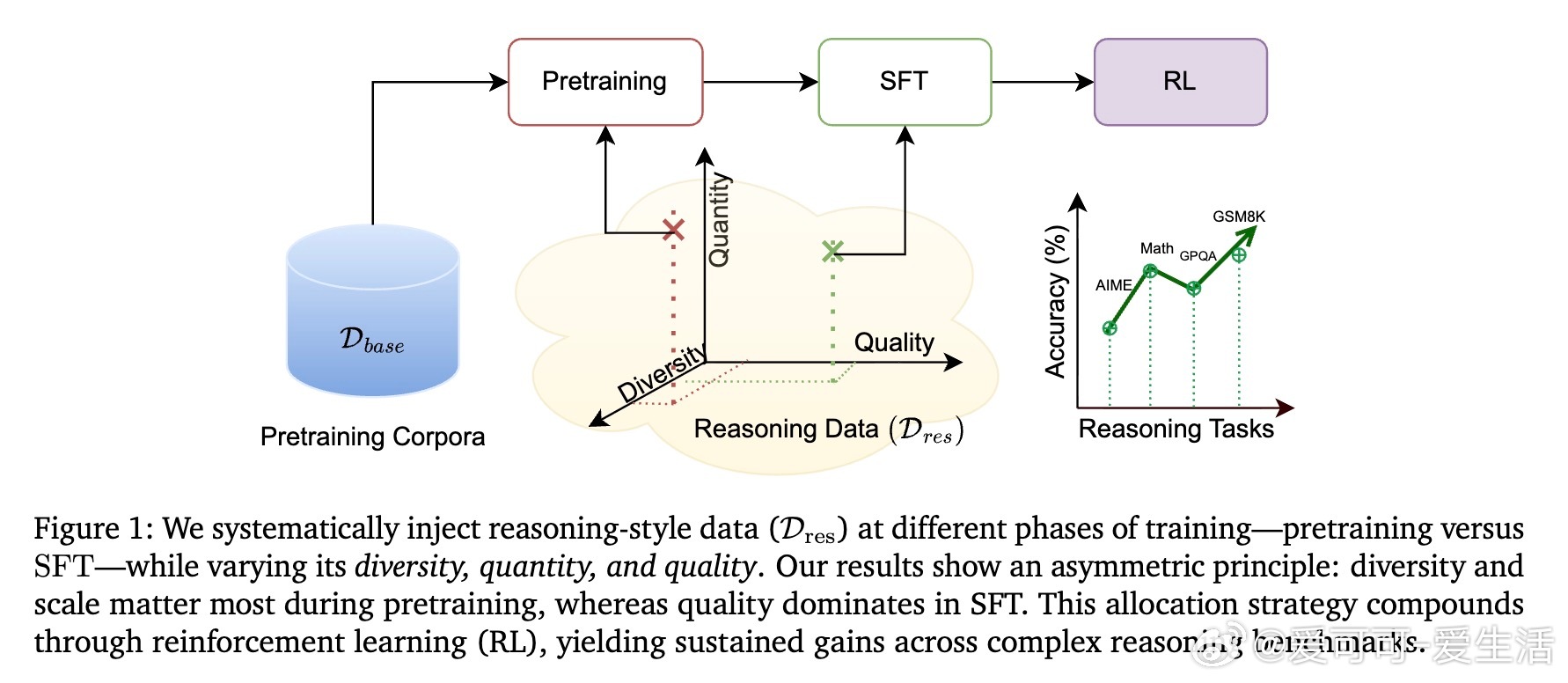
- 本文首次系统探讨在预训练阶段注入推理数据的效果及其与后期微调的协同作用。
- 关键问题:推理数据早期注入(预训练)是否优于后期注入(SFT)?是否存在过拟合风险?数据多样性与质量在不同阶段的作用如何?
⚡ 核心发现:
1️⃣ “前置推理数据”至关重要:预训练阶段加入推理数据,平均提升19%准确率,建立坚实基础,后续微调无法完全弥补预训练缺失。
2️⃣ 数据策略不对称:
- 预训练阶段更依赖**推理数据的多样性和规模**(带来约11%提升),有助于模型形成广泛推理能力。
- SFT阶段更注重**数据质量**(约15%提升),高质量长链推理示例更能促进模型专精。
3️⃣ 盲目扩大SFT数据量反而有害,尤其是质量混杂时,可能降低数学推理能力。
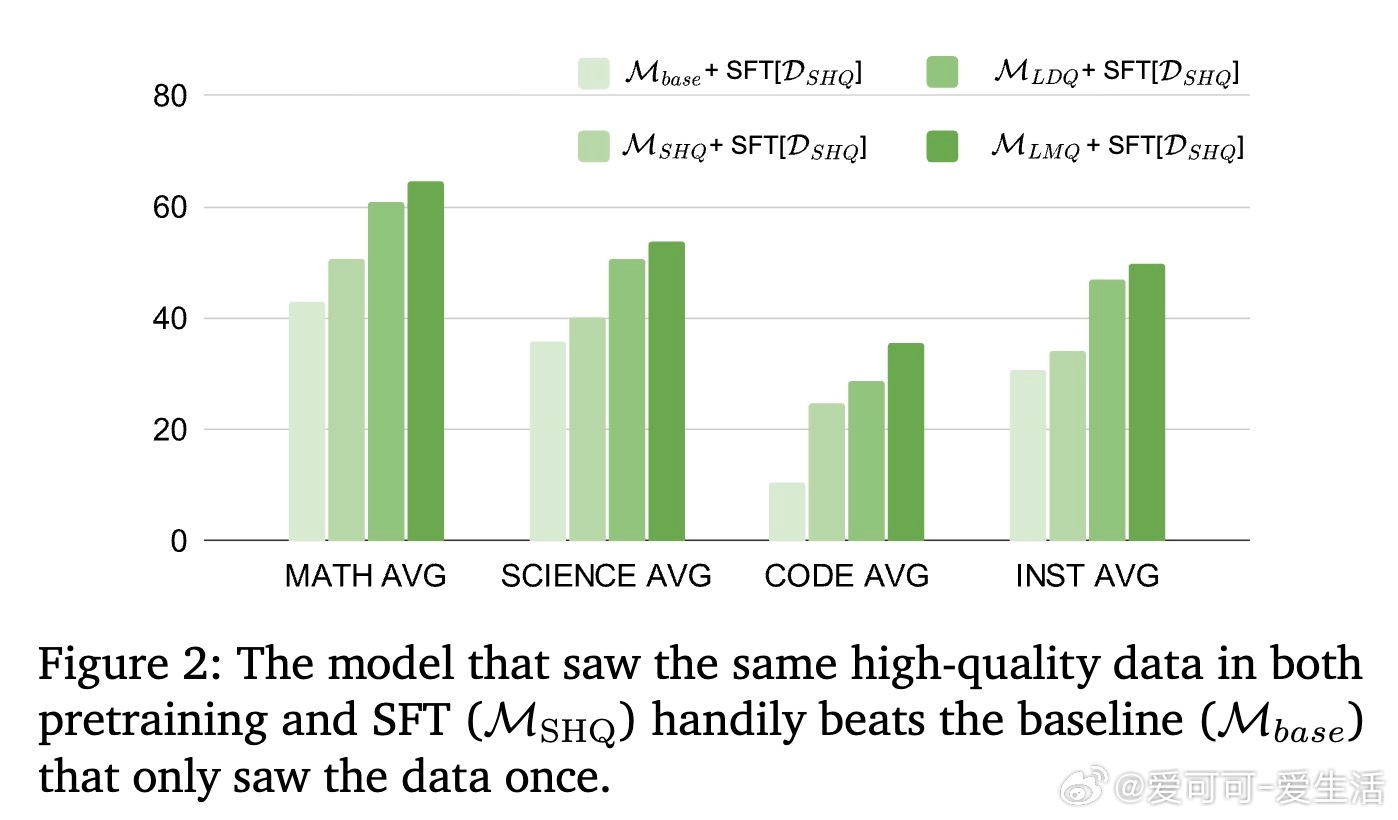
4️⃣ 高质量预训练数据在SFT阶段“激活”潜力,带来额外提升。
5️⃣ 预训练和SFT阶段使用同一高质量推理数据不会导致过拟合,反而强化模型基础技能。
🛠️ 方法与实验:
- 使用8B参数混合Transformer模型,预训练1万亿tokens。
- 预训练数据分为基础通用语料与不同规模、质量、复杂度的推理数据集(大规模多样、少量高质、大规模混合、长链推理筛选)。
- 设计三阶段训练:预训练、监督微调(SFT)、强化学习(RL)。
- 严格控制推理数据总量预算,探索不同阶段数据分配策略的效果。
- 评测涵盖数学、科学、代码、通用推理等多领域多任务。
📈 结果亮点:
- 预训练注入大规模多样推理数据,数学准确率提升28.4%,代码提升9%。
- SFT阶段高质量数据显著提升模型表现,尤其在数学、科学和代码任务上。
- 预训练阶段缺推理数据的模型,SFT加倍数据量也难以追赶预训练含推理数据的模型。
- 强化学习阶段进一步放大预训练优势,顶尖模型在AIME数学竞赛中领先39.3%。
📌 实践启示:
- 构建高性能推理型LLMs,应重视推理数据的“前置加载”——预训练阶段大量多样推理数据支撑基础能力。
- 后期微调应聚焦于精炼高质量推理示例,避免简单增量扩张低质数据。
- 预训练与微调阶段的数据策略应差异化对待,扬长避短。
🧠 思考扩展:
- 本文挑战了传统“预训练语言模型+后期推理微调”的分离思路,提出“推理意识预训练”是构建高效推理模型的关键。
- 未来研究可探索更多推理数据的生成方式、跨领域迁移能力及更大规模模型的适应性。
- 数据多样性与质量如何权衡,是否存在更精细的阶段划分和策略,值得深挖。
全文链接👉 arxiv.org/abs/2510.03264
大语言模型 预训练 推理能力 机器学习 NLP 数据策略 AI研究