[LG]《Closed-Form Last Layer Optimization》A Galashov, N D Costa, L Xu, P Hennig... [Google Deep & MindUniversity of Tubingen & Secondmind] (2025)
用封闭形式优化神经网络最后一层,提升训练效率!
🔹 背景:传统神经网络训练多用SGD,所有层均通过迭代优化。但最后一层是线性的,在平方损失下可直接求解闭式最优解,这为优化带来新机遇。
🔹 核心贡献:
1️⃣ 利用平方损失下最后一层权重的闭式解,将最后一层视作骨干网络参数θ的函数,只对θ做梯度下降,从而等价于交替更新骨干参数和最后一层闭式解。
2️⃣ 针对小批量训练,设计了带近端正则的闭式更新,防止最后一层对单个小批次过拟合,算法与标准训练流程兼容,且具备卡尔曼滤波视角。
3️⃣ 理论上,在神经切线核(NTK)无限宽网络极限下,证明该方法以连续时间形式收敛到全局最优解。
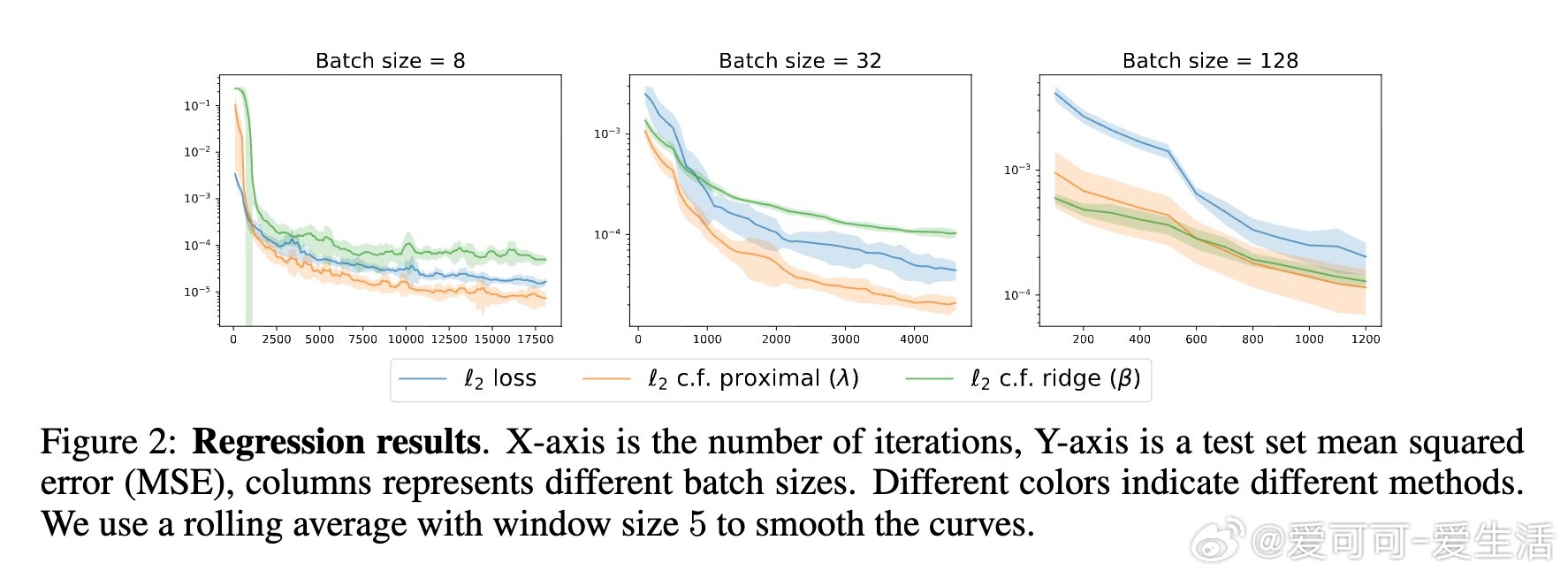
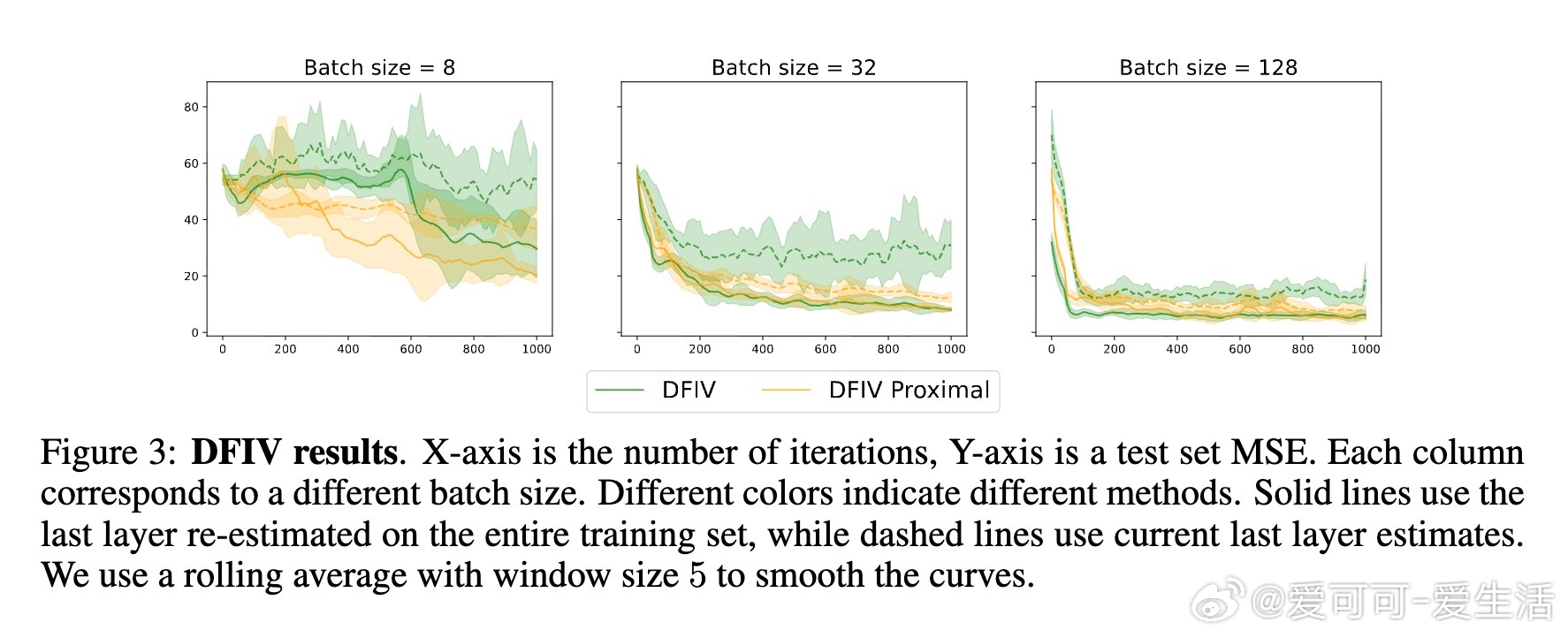
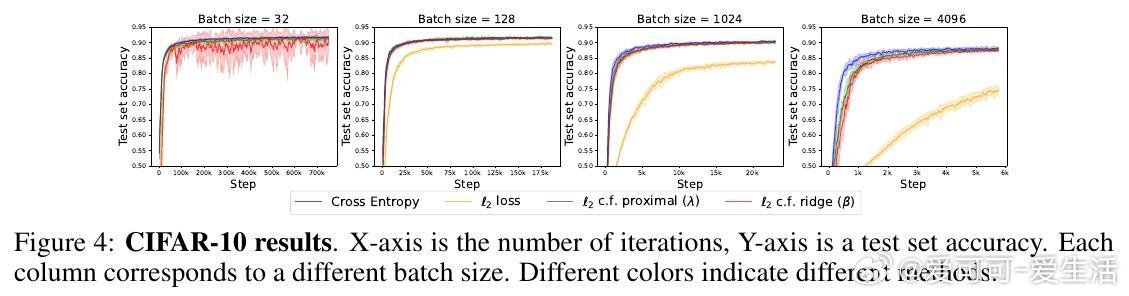
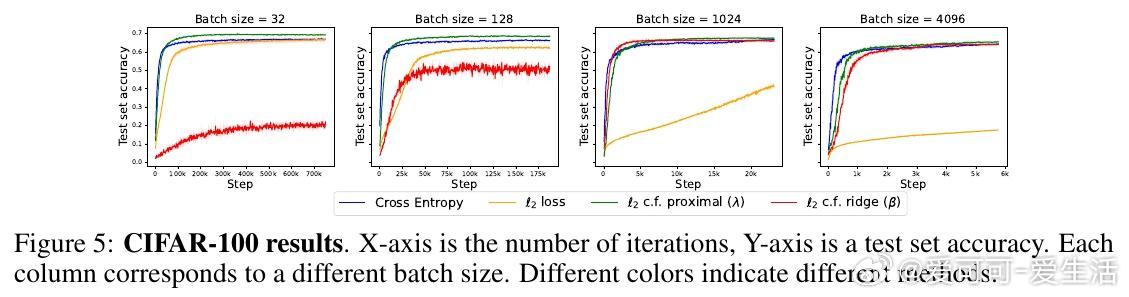
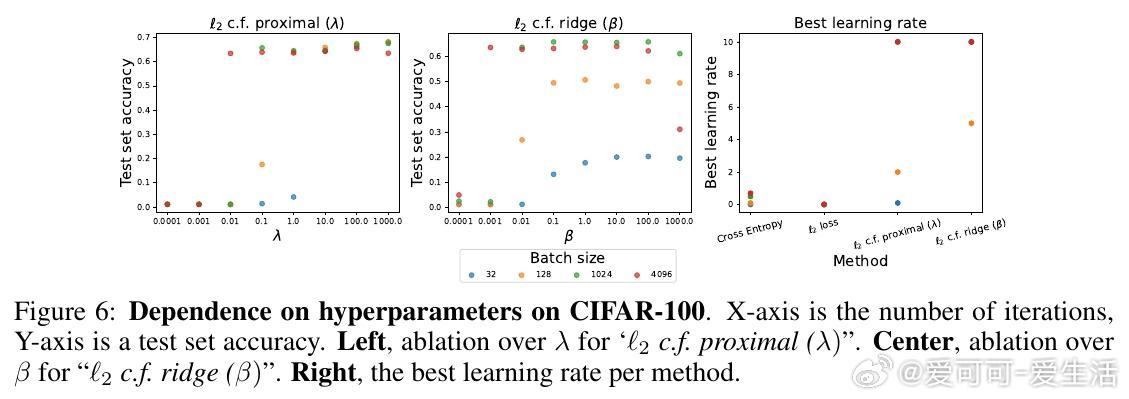
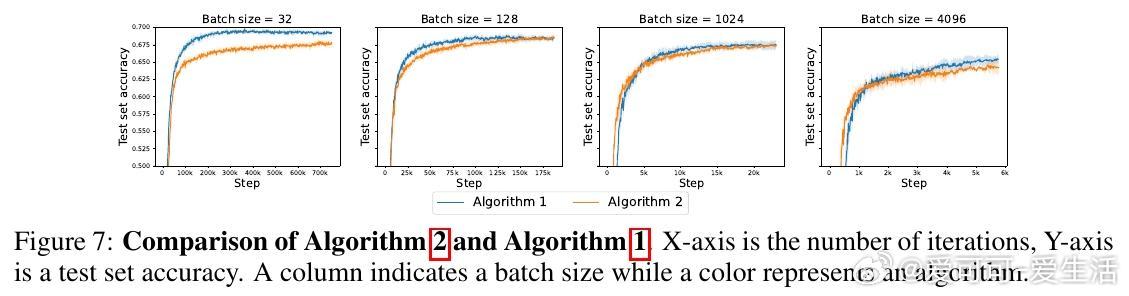
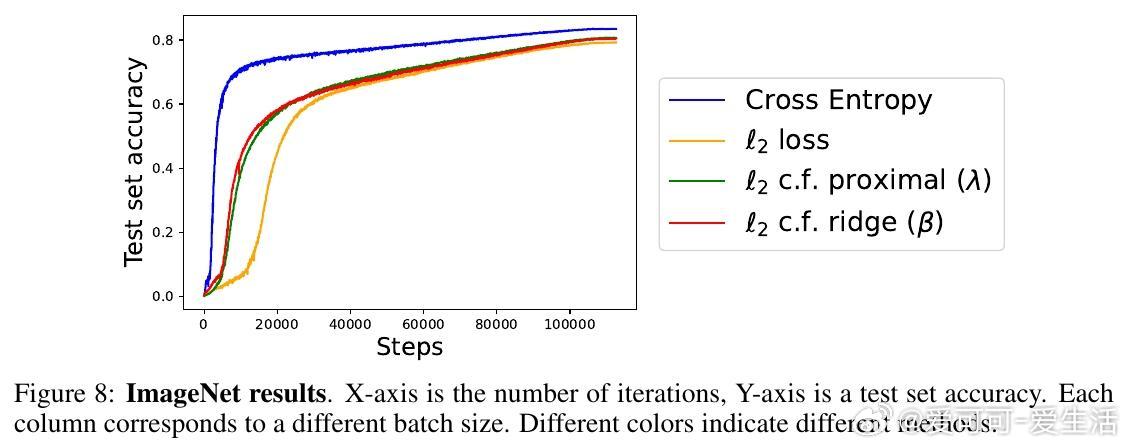
4️⃣ 实验涵盖回归(如傅里叶神经算子)、因果推断的深度工具变量回归、图像分类(CIFAR、ImageNet),结果显示该方法在平方损失下训练更快、泛化更优。
🔹 重要细节:
- 使用近端正则项调整最后一层闭式解,解决小批量不稳定性。
- 不需对闭式解求导,简化反向传播计算。
- 在分类任务中,虽用平方损失,预测时取最大概率类别,表现依然理想。
- 实验中零初始化最后一层效果最好,SGD优于Adam做骨干网络更新。
🔹 实验亮点:
- 小批量下,该方法显著优于传统SGD平方损失训练。
- CIFAR-100上甚至超越了交叉熵训练,ImageNet规模下仍稍逊于交叉熵,但优于普通平方损失。
- 适用多种任务,尤其回归和二阶段因果模型展现强大潜力。
🔹 理论洞察:
- 该损失函数非凸,存在非全局极小点,但在NTK极限下,算法几乎必收敛至全局最优。
- 通过特征空间投影,分析了特征与输出的可达性,说明了训练动态。
🔹 未来方向:
- 探索闭式解在交叉熵等其他损失下的推广。
- 改进自适应正则参数策略,结合Adam优化器。
- 扩展至大型二阶段学习任务,如离线RL和代理变量回归。
📄 原文链接:arxiv.org/abs/2510.04606v1
总结:
这项工作提出了一种高效利用最后一层闭式最优解的新训练范式,理论严谨、实验证明效果显著,特别适合平方损失问题。对于想提升训练速度和稳定性的研究者和工程师,值得尝试!
深度学习 神经网络 优化算法 机器学习 闭式解 NTK 因果推断 傅里叶神经算子 CIFAR ImageNet