[LG]《Gaussian Embeddings: How JEPAs Secretly Learn Your Data Density》R Balestriero, N Ballas, M Rabbat, Y LeCun [Meta-FAIR] (2025)
JEPAs 如何秘密学会你的数据密度?论文揭示了自监督学习中的一个惊人发现👇
1、JEPAs(Joint Embedding Predictive Architectures)通过两个核心目标训练:
- 预测潜在空间中轻微扰动样本的表示
- 防止全部样本陷入同一表示(反坍缩)
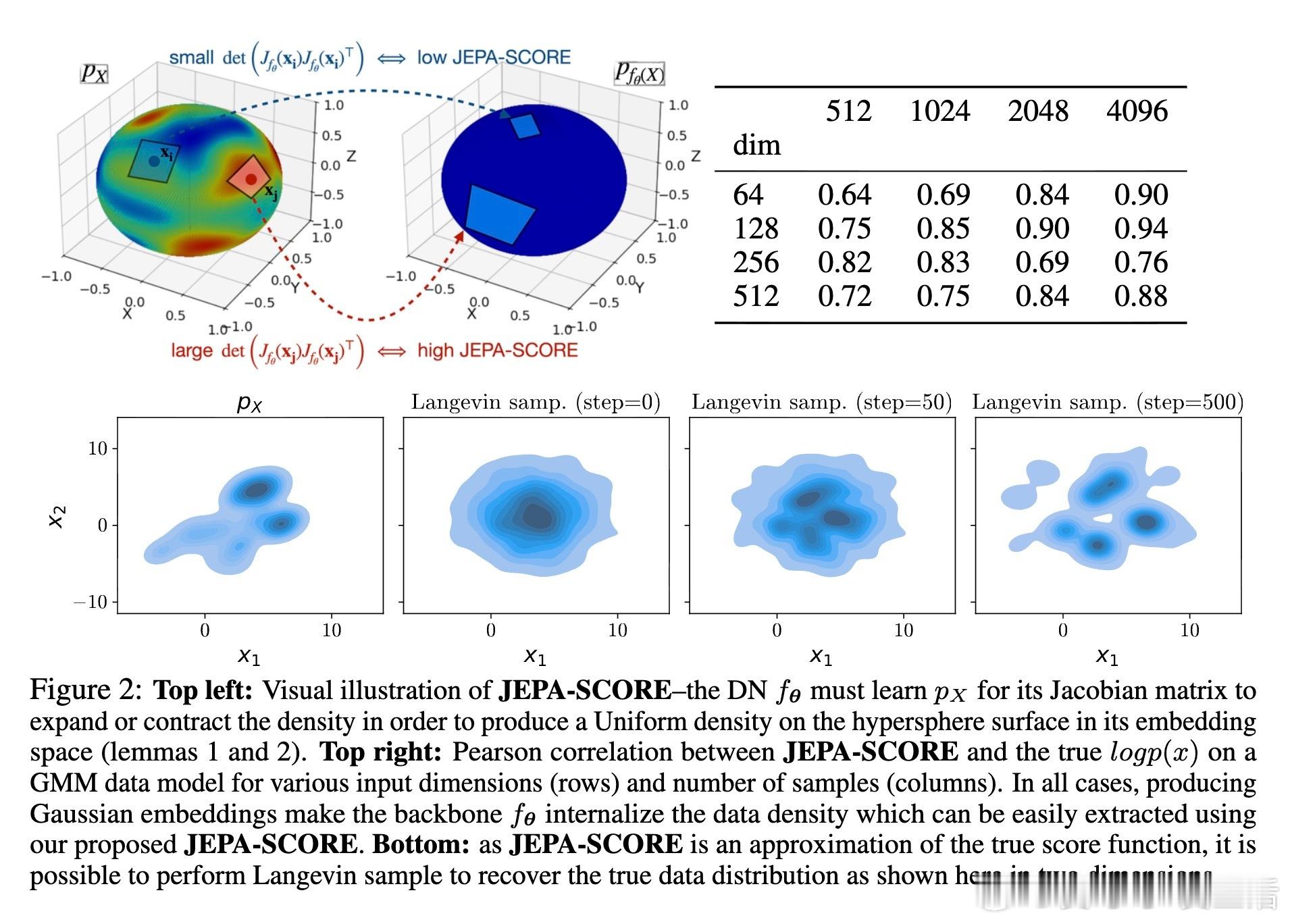
2、传统认为反坍缩只是避免表示退化,但论文证明这一项同时隐式地估计了数据的概率密度!
换言之,成功训练的JEPA能直接给出样本的概率分布,且计算高效,闭式表达通过模型在样本点的Jacobian矩阵实现。
3、这意味着JEPAs不只是学习特征,实际上它们也能做数据密度估计,具备强大应用价值:
- 数据清洗与筛选
- 异常检测
- 密度估计等
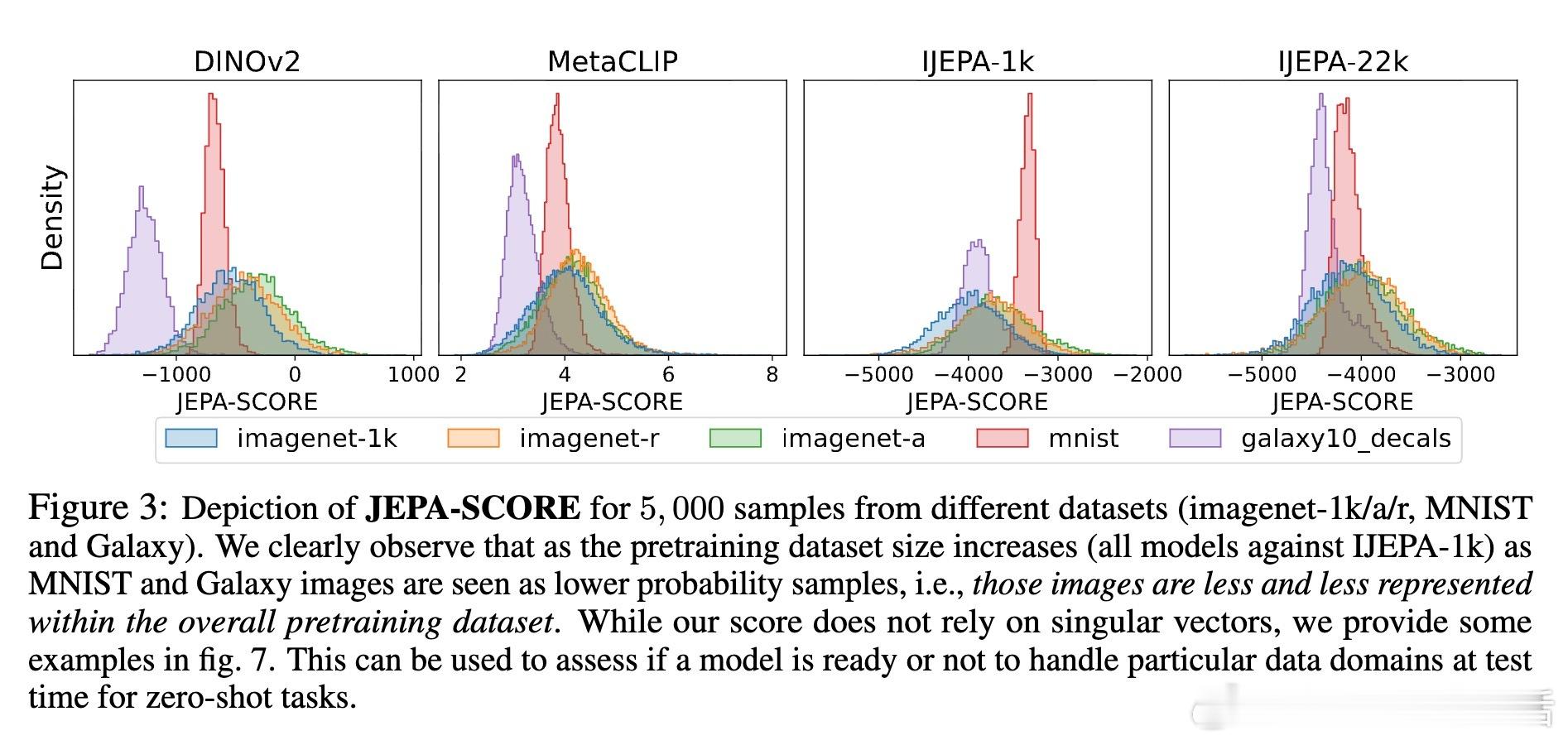
4、理论结果不依赖于数据集或具体模型架构,实验证明在合成数据、Imagenet甚至多模态模型MetaCLIP上均有效。涵盖JEPA家族中的I-JEPA、DINOv2等方法。
5、论文提出了一个提取JEPA学得密度的算法——JEPA-SCORE,开启了自监督学习中密度估计的新篇章!
📖 原文链接:arxiv.org/abs/2510.05949
这项研究为理解和利用自监督表示学习打开了新视角,值得ML和AI领域关注和深入探索!机器学习 自监督学习 数据密度估计 人工智能