[CL]《Mixture of Neuron Experts》R Cheng, Y Guan, Y Ding, Q Hu... [Microsoft & Tsinghua University] (2025)
突破传统MoE稀疏激活瓶颈,实现更高效参数利用💡
🔍背景:传统Mixture-of-Experts(MoE)模型通过激活部分专家参数提升大模型计算效率,但其激活参数内部仍存大量冗余。
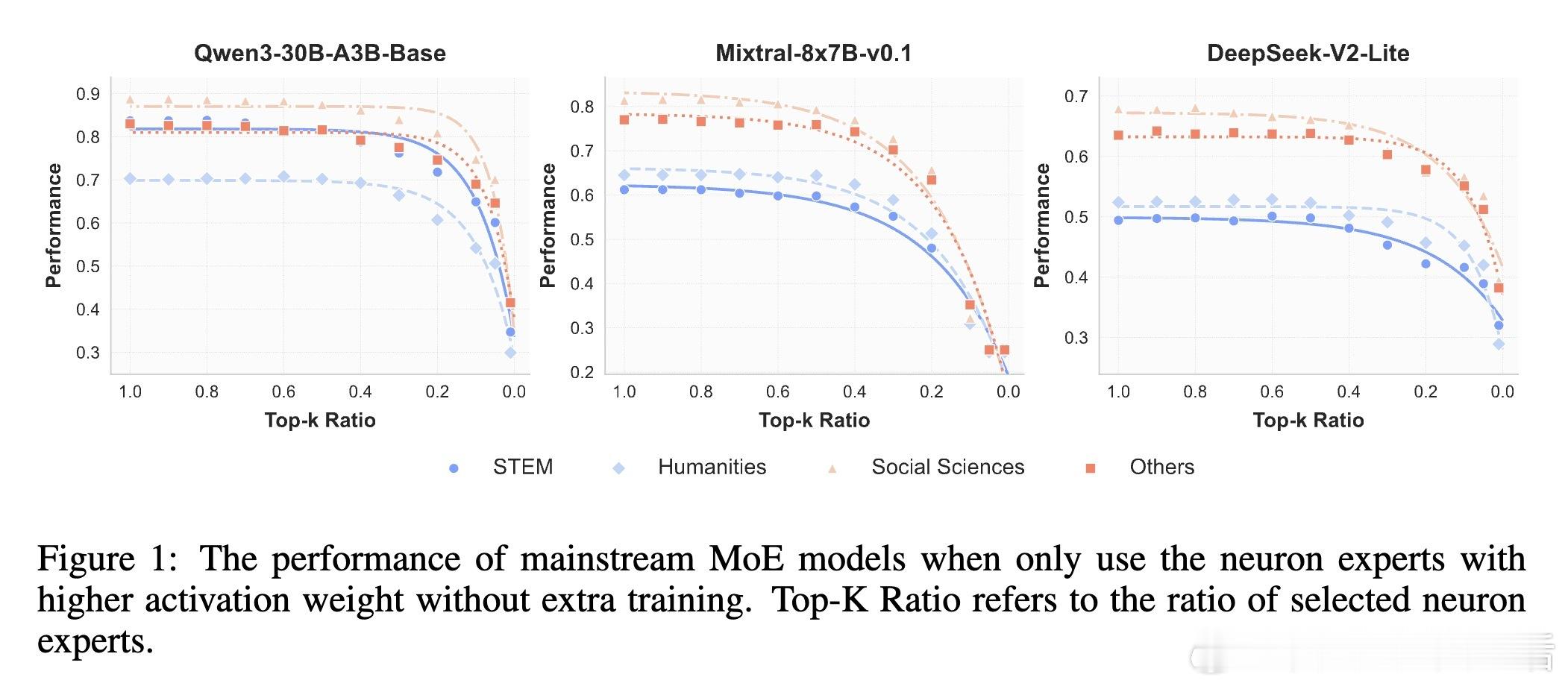
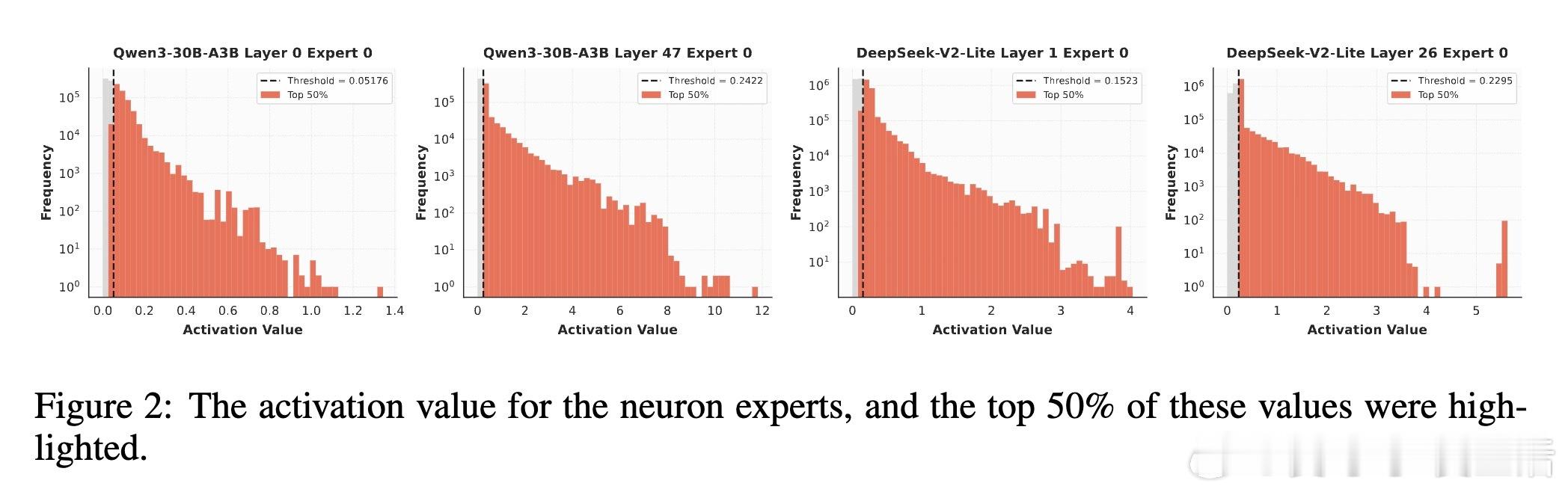
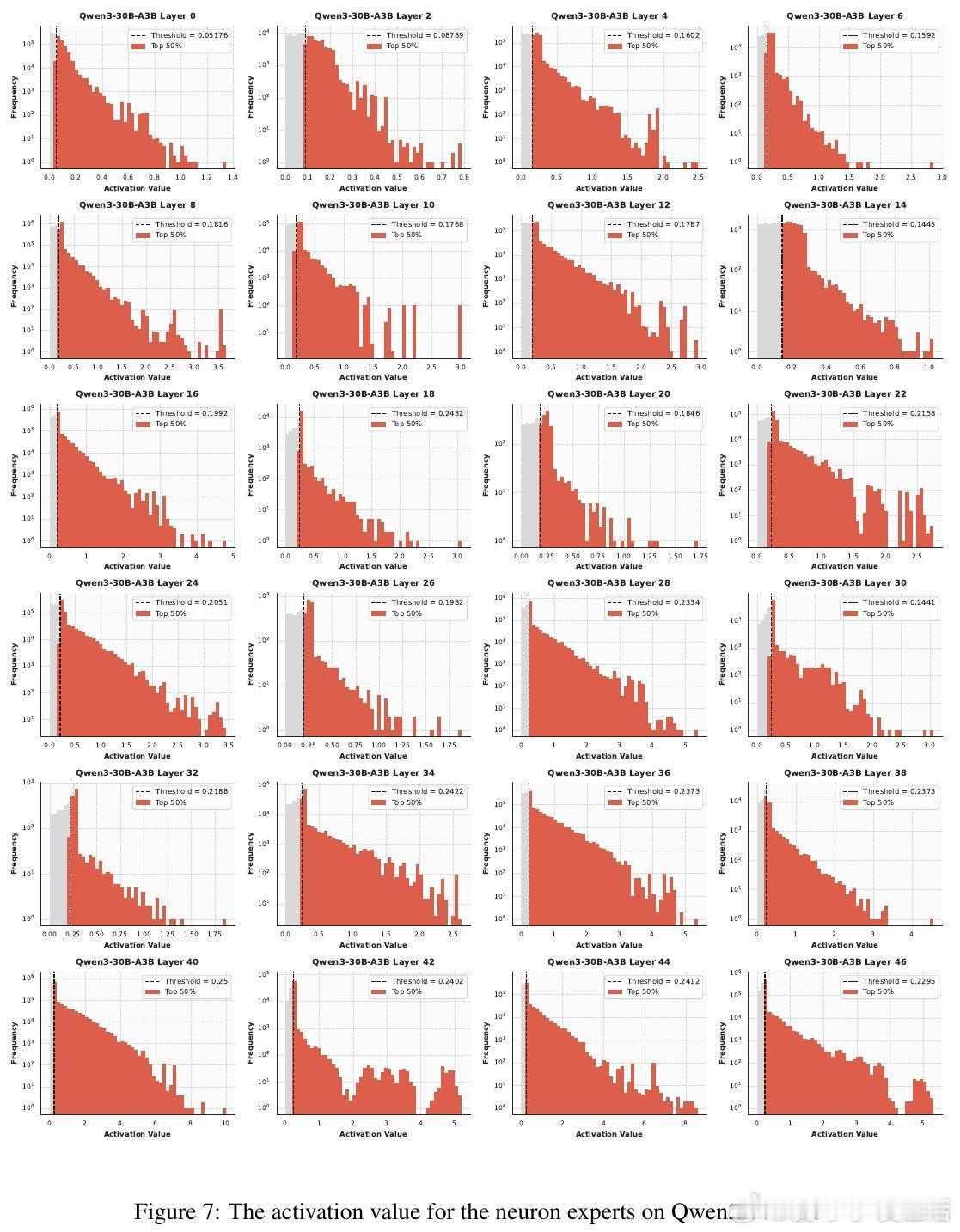
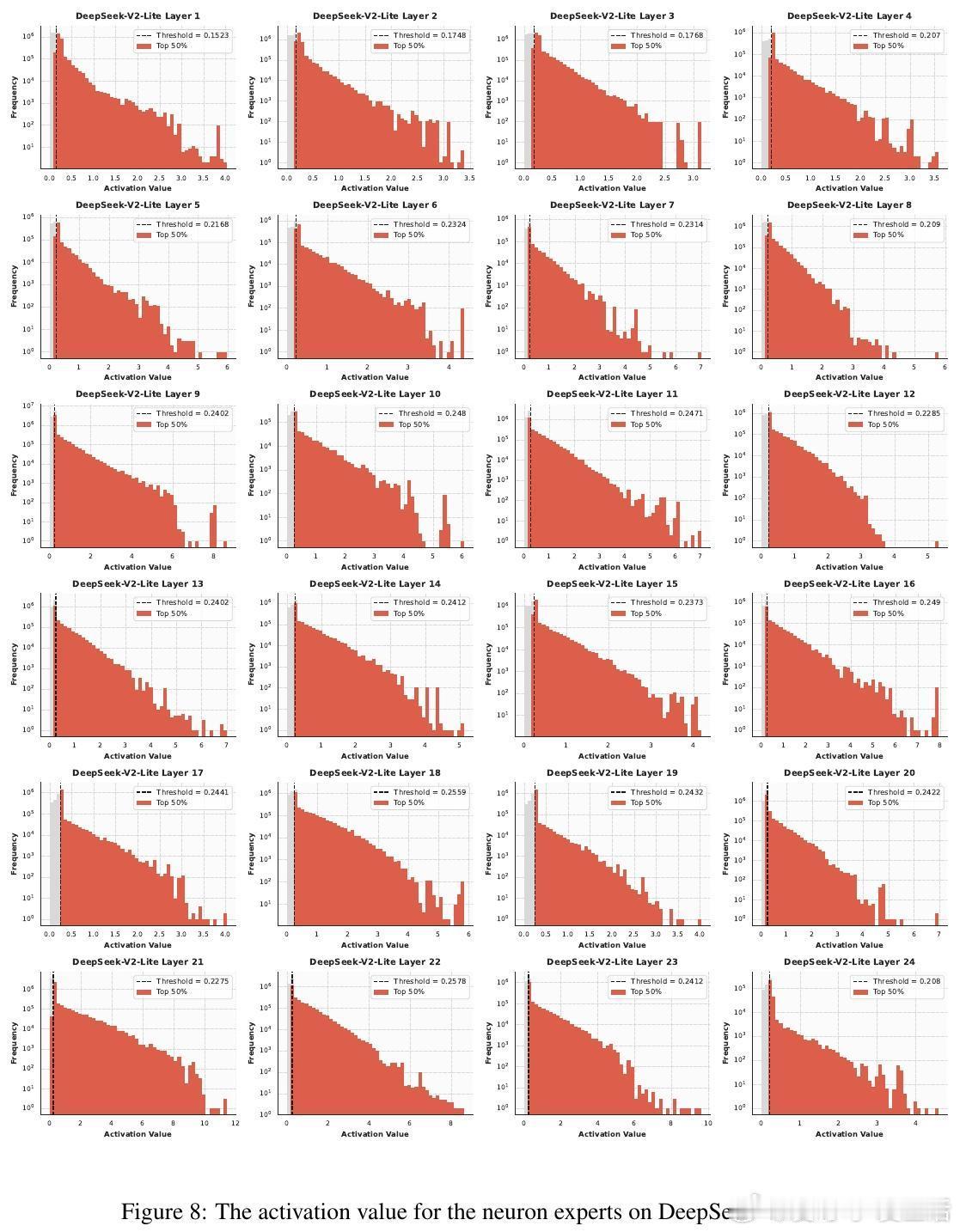
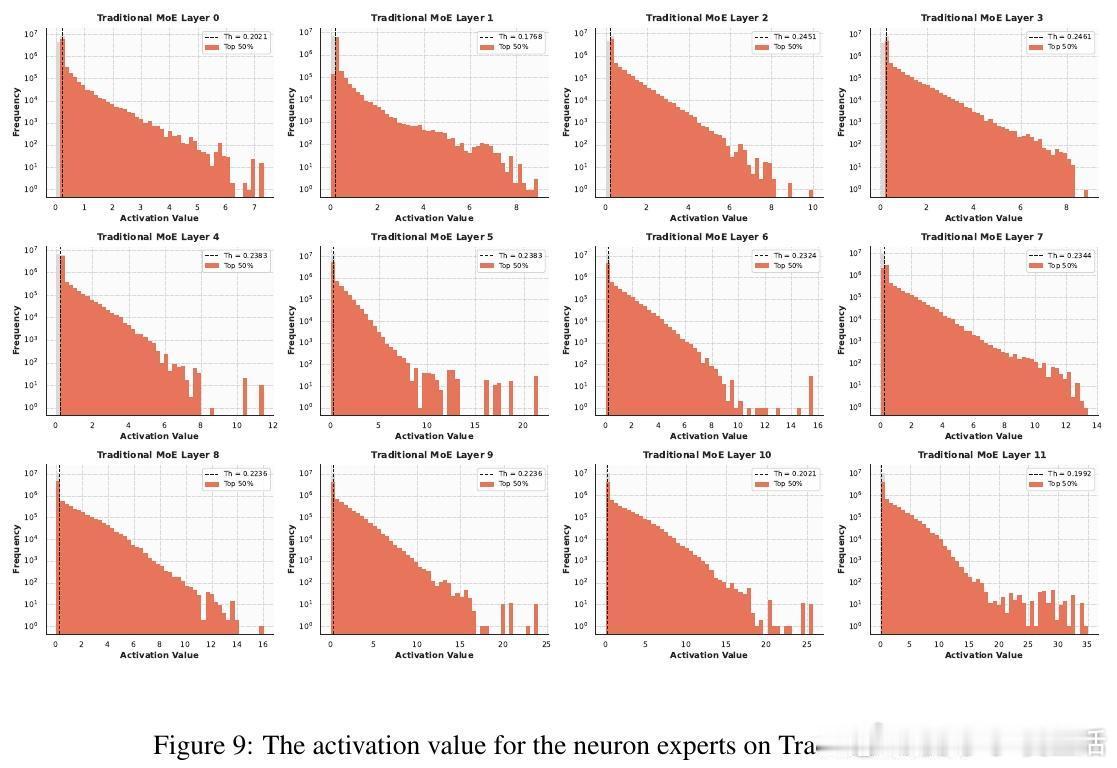
📊发现:实验证明,在推理阶段,MoE层激活的参数依然高度稀疏。对专家内按激活权重排名的神经元进行剪枝,剪掉60%激活参数性能几乎无损,超过90%才显著下降。
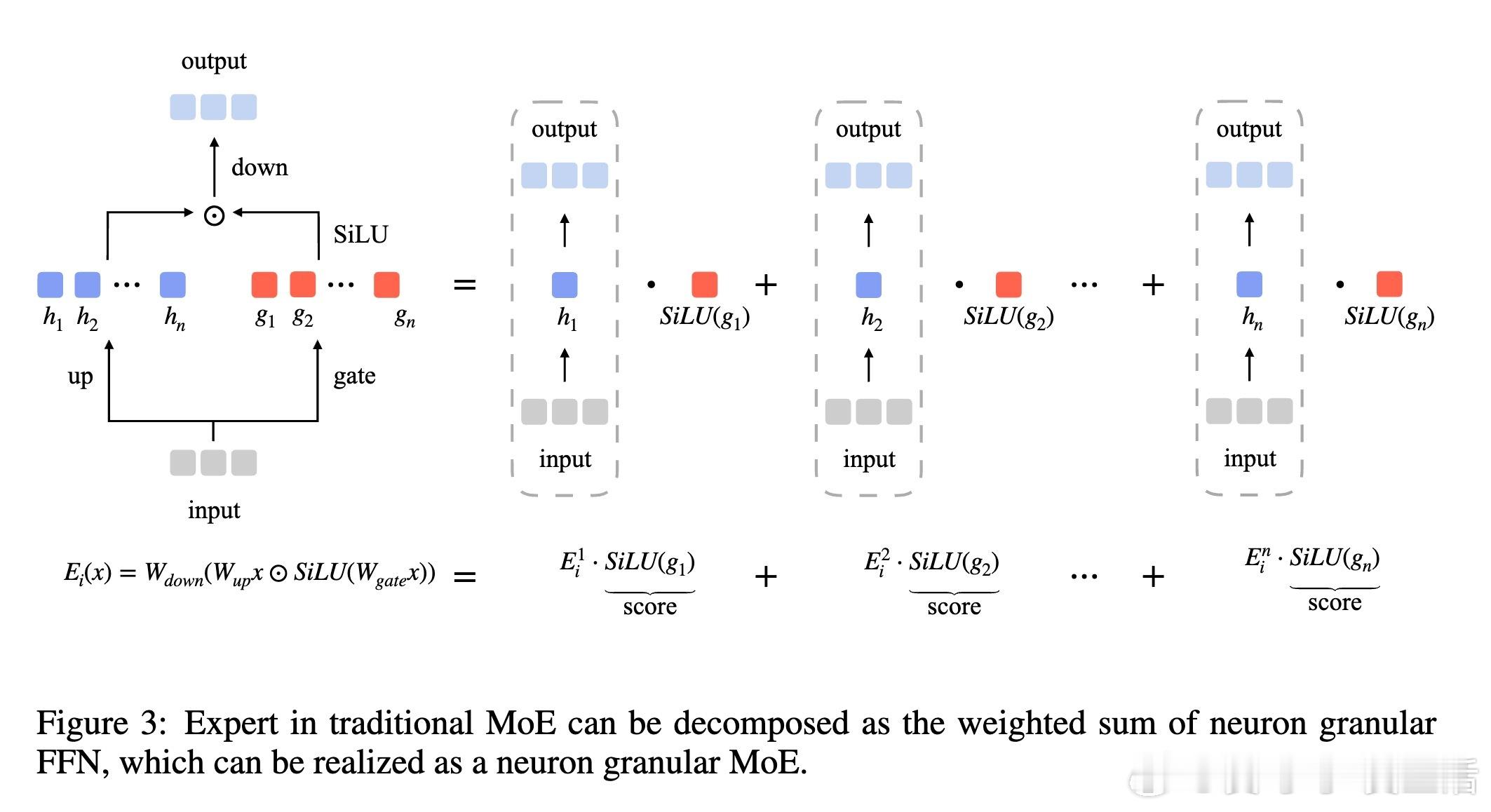
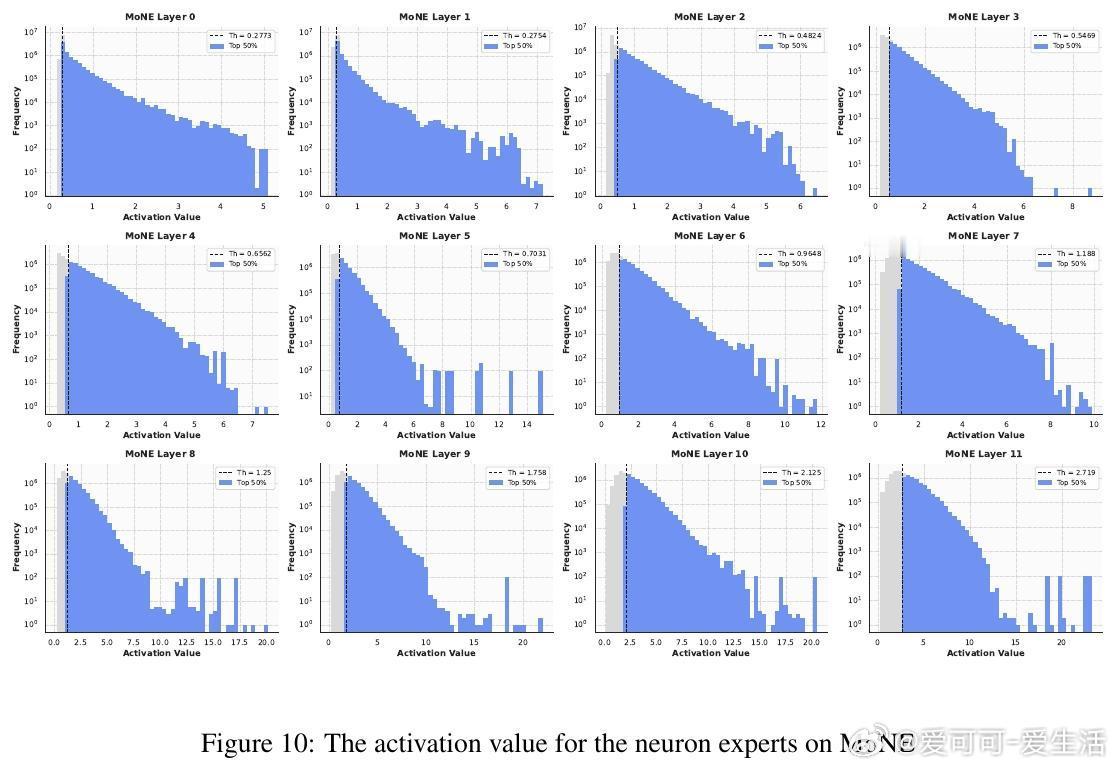
🧠创新:作者提出Mixture of Neuron Experts(MoNE)——将每个专家细分为“神经元专家”,在每个专家内部仅激活top-k神经元,极大提升激活参数利用率,无需额外路由参数或跨专家通信。
🚀优势:
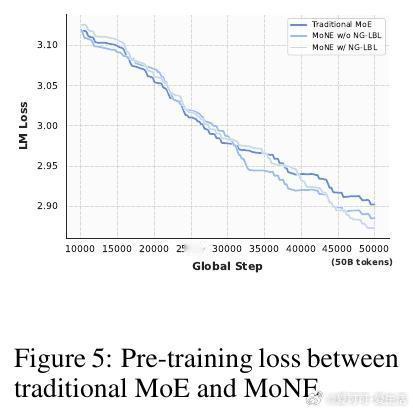
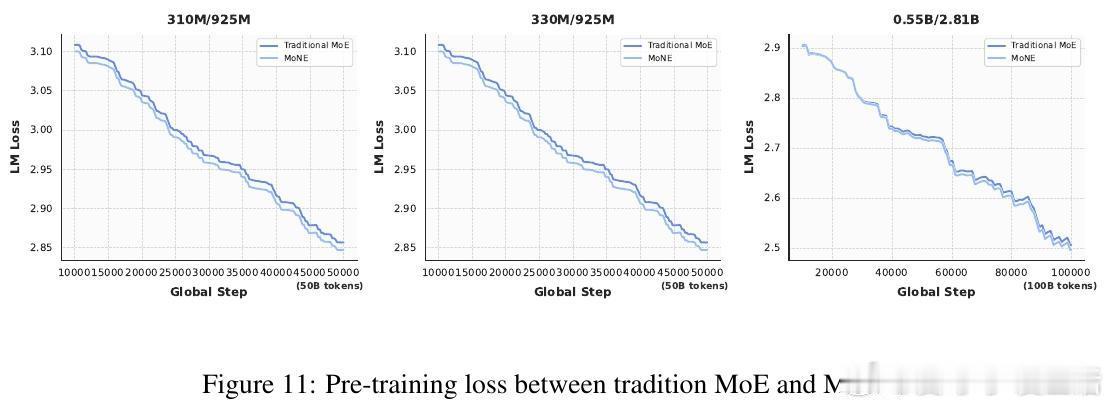
- 激活参数仅为传统MoE的50%,性能不降反升
- 与传统MoE在相同激活参数规模下,MoNE表现更优
- 无额外通信延迟,计算效率持平传统MoE
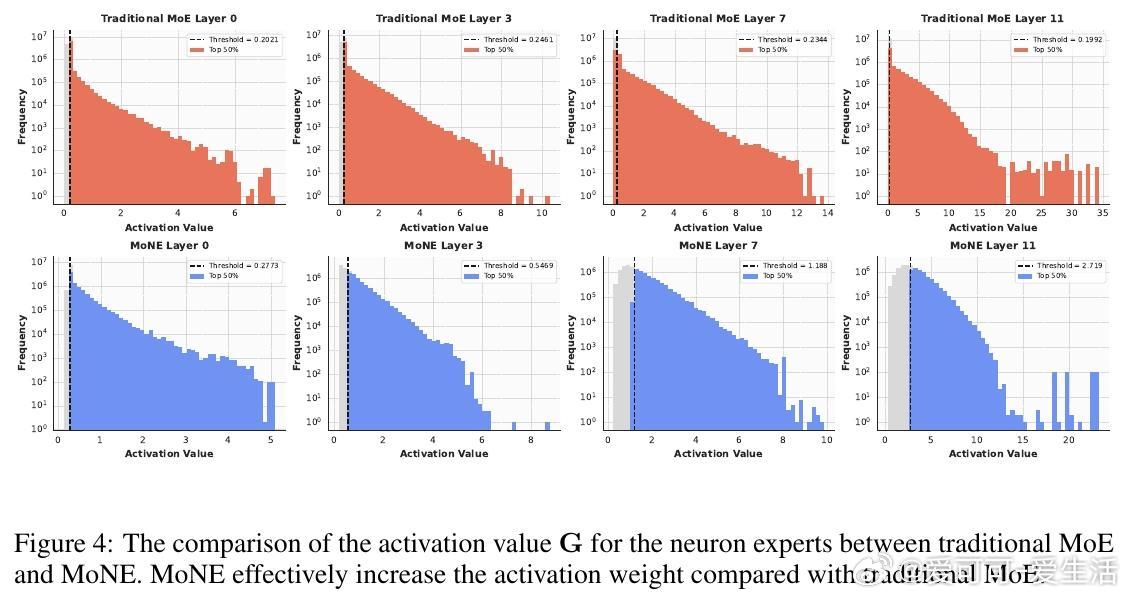
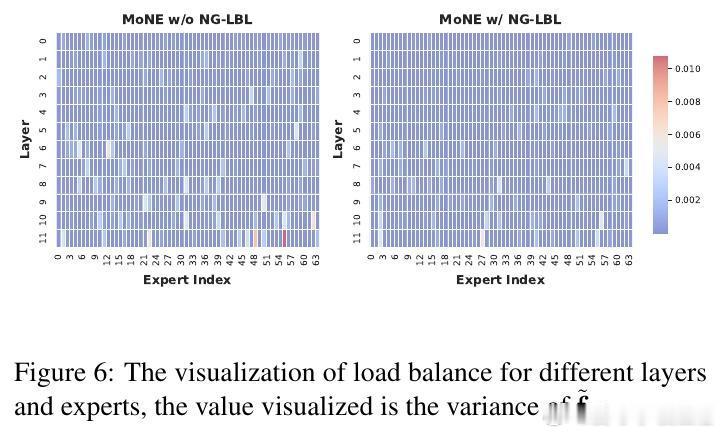
- 引入神经元粒度负载均衡损失,均衡神经元激活,进一步提升性能
🔬实验覆盖925M与2.81B参数规模,涵盖多项下游任务,均验证MoNE的稳健性和效率优势。
✨总结:MoNE通过细化专家粒度,精准激活核心神经元,破解了传统MoE激活稀疏与计算资源浪费的矛盾,是推动大规模稀疏模型实用化与高效推理的实用路径。
阅读全文👉arxiv.org/abs/2510.05781
大模型 MoE 稀疏激活 深度学习 模型优化