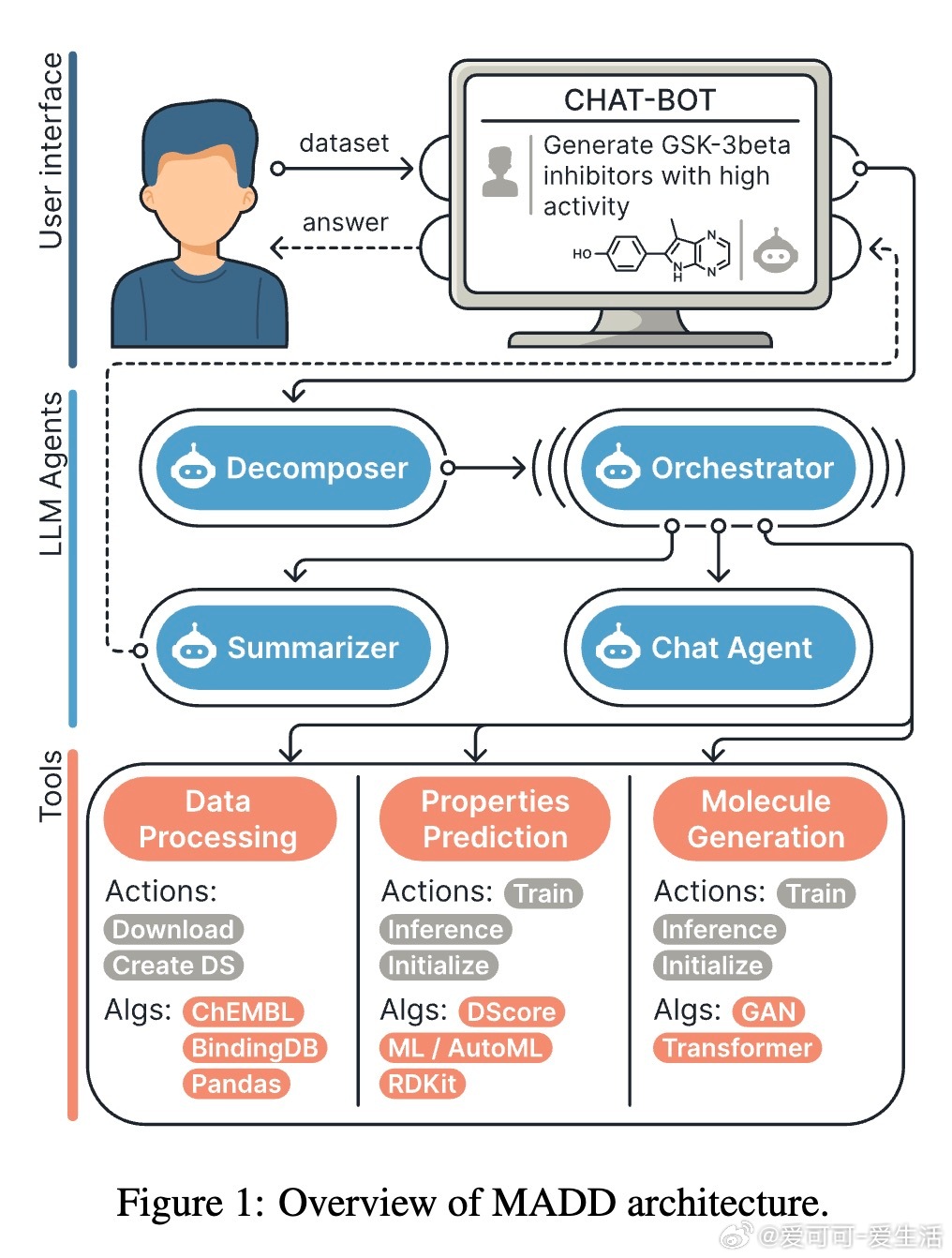
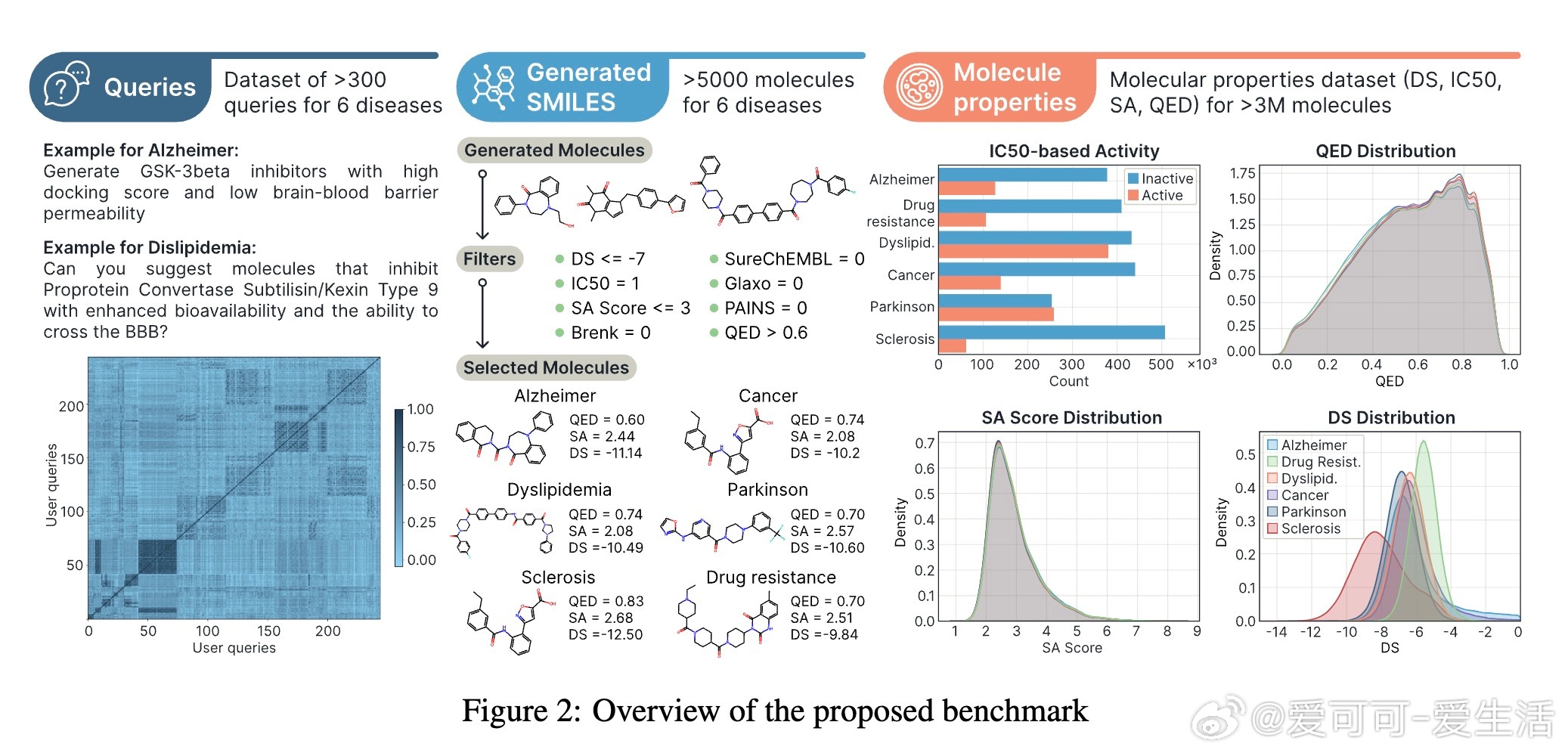
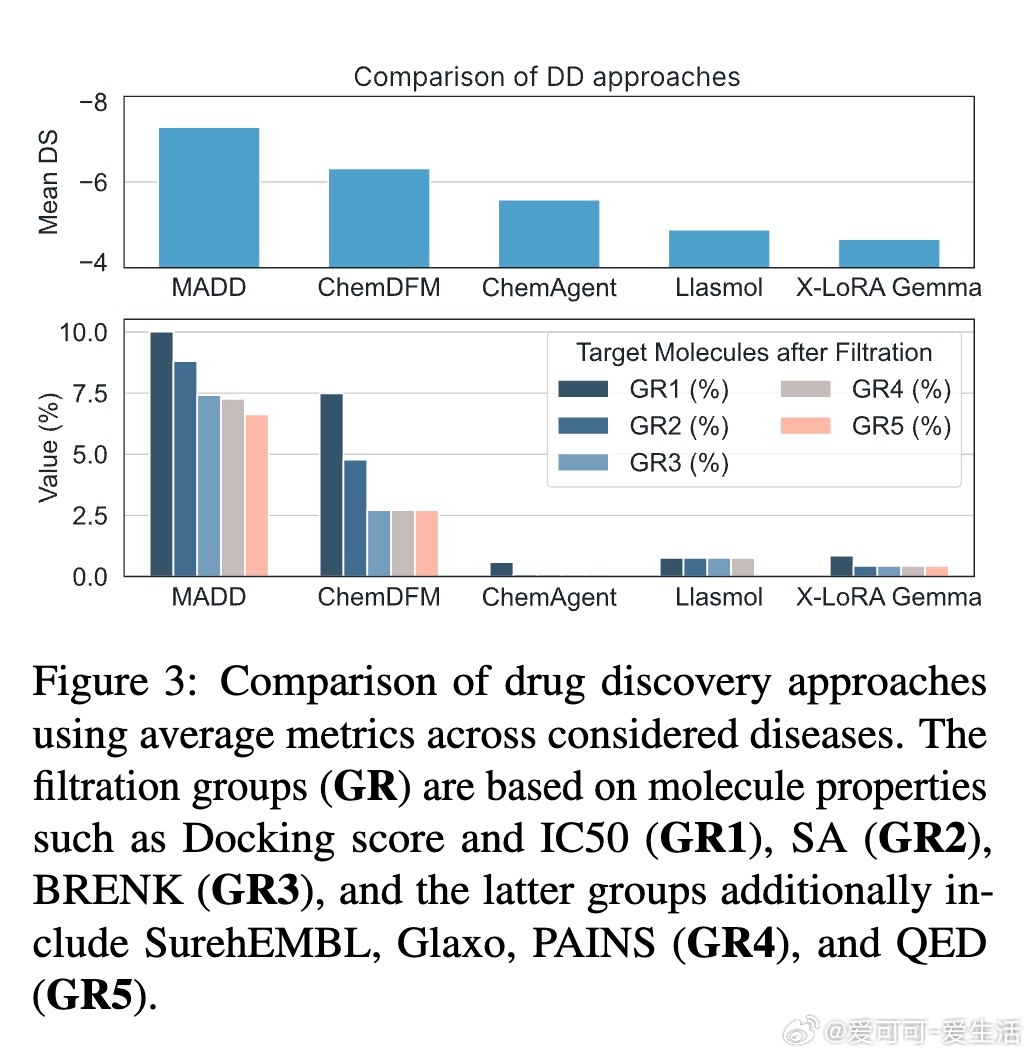
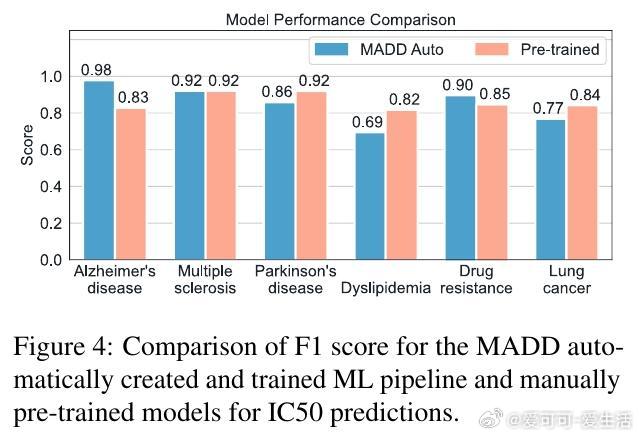
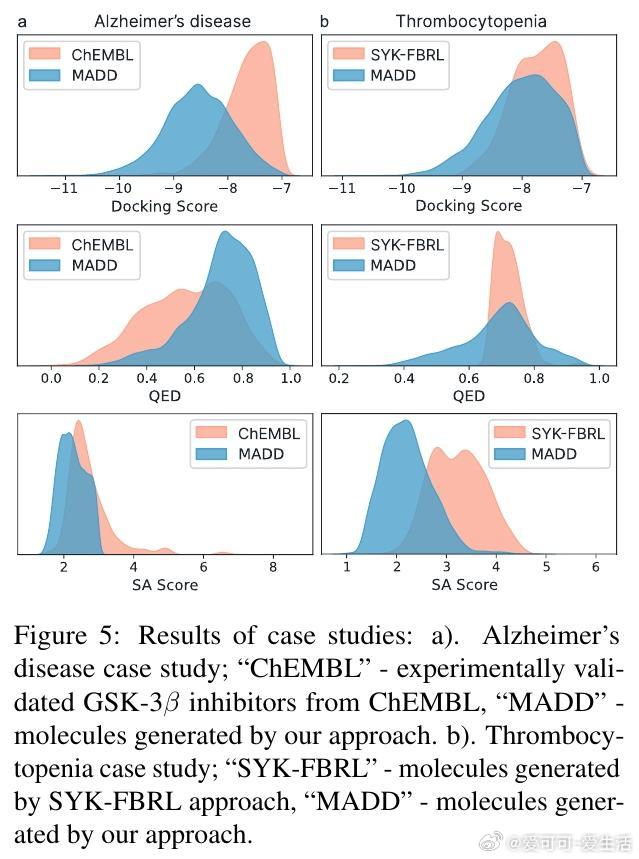
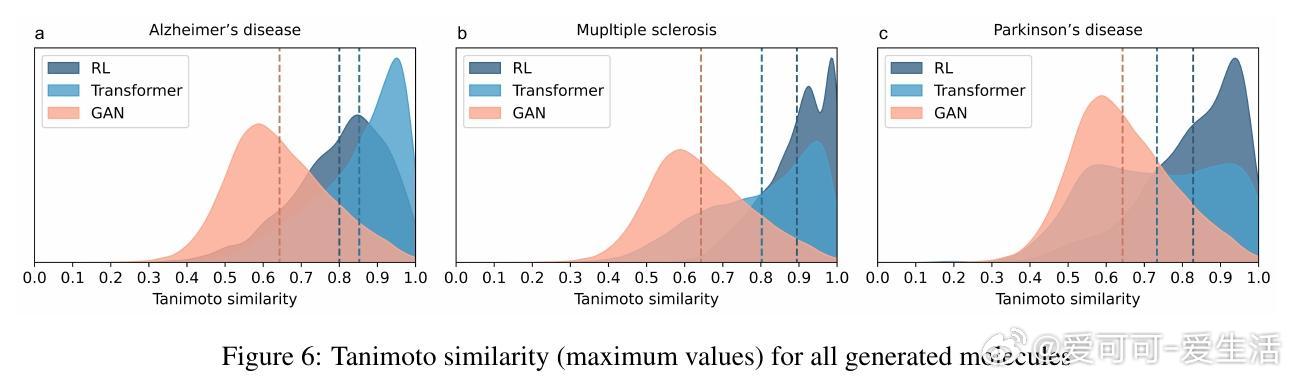
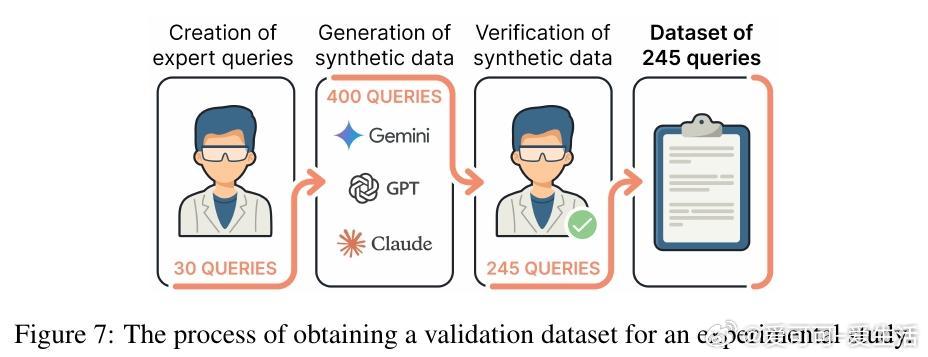
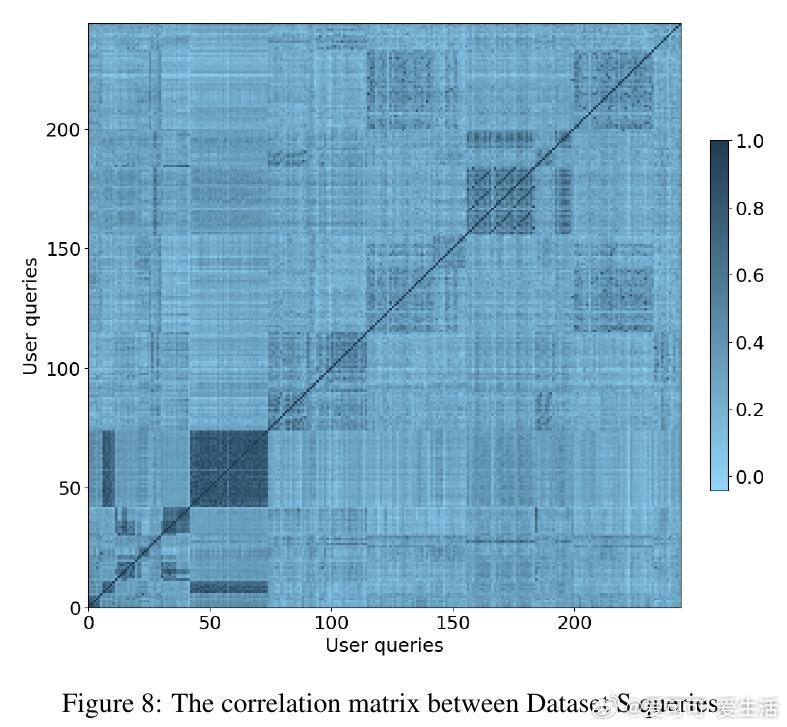
[LG]《MADD: Multi-Agent Drug Discovery Orchestra》G V. Solovev, A B. Zhidkovskaya, A Orlova, N Gubina... [ITMO University] (2025) 在早期药物发现中,“命中分子”识别一直是核心难题,传统方法依赖大量实验资源。随着人工智能,尤其是大型语言模型(LLM)的发展,虚拟筛选技术大幅提升了效率并降低了成本,但复杂的AI工具门槛高,难以被实验室研究者充分利用。为此,本文提出了MADD(Multi-Agent Drug Discovery Orchestra)——一个多智能体系统,集成四个专职代理,能够从自然语言查询自动构建和执行定制的命中分子识别流程。MADD通过分工明确的代理分别承担任务拆解、工具调度、结果总结和用户交互,结合预训练和自动微调的分子生成模型(如GAN和Transformer CVAE)、机器学习预测模型及分子筛选工具,实现了从语义解析到生成、验证及筛选的端到端流程。该系统在阿尔茨海默症、帕金森病、多发性硬化、肺癌、血脂异常、药物耐受性等七个真实药物发现案例中表现优异,较现有LLM解决方案准确率提升显著,尤其在复杂多任务查询下最终准确率达近80%。研究团队还发布了一个包含超过300万化合物的查询-分子对及对接评分的新基准数据集,推动未来智能药物设计的标准化。MADD支持自动机器学习(AutoML)功能,能自动训练并优化生成及预测模型,提升了模型适应新疾病的能力。两项重点案例研究显示,MADD生成的分子在合成可行性、药物相似性及靶点结合亲和力方面均优于现有实验验证的化合物。此外,MADD还成功应用于未曾设计过的血小板减少症案例,验证了其强大的泛化能力和自我训练潜力。尽管MADD展现出卓越的虚拟筛选能力,其依赖用户提供高质量数据集和已知靶点信息,尚未实现对完全未知靶点的开放式发现。未来工作将致力于自动化数据整理、假设生成模块的集成,以及与实验室验证的深度结合,推动AI设计从“计算机内”走向“实验室中”,真正缩短药物开发周期。总结而言,MADD以多智能体协同架构有效整合复杂药物设计工具,实现自然语言驱动的高效分子命中识别,开创了AI优先药物发现的新篇章,其代码和数据均已开源,欢迎领域内研究者共建未来。详细内容及开源资源请见:arxiv.org/abs/2511.08217 GitHub:github.com/ITMO-NSS-team/MADD 数据集:huggingface.co/datasets/ITMO-NSS/MADD_Benchmark_and_results