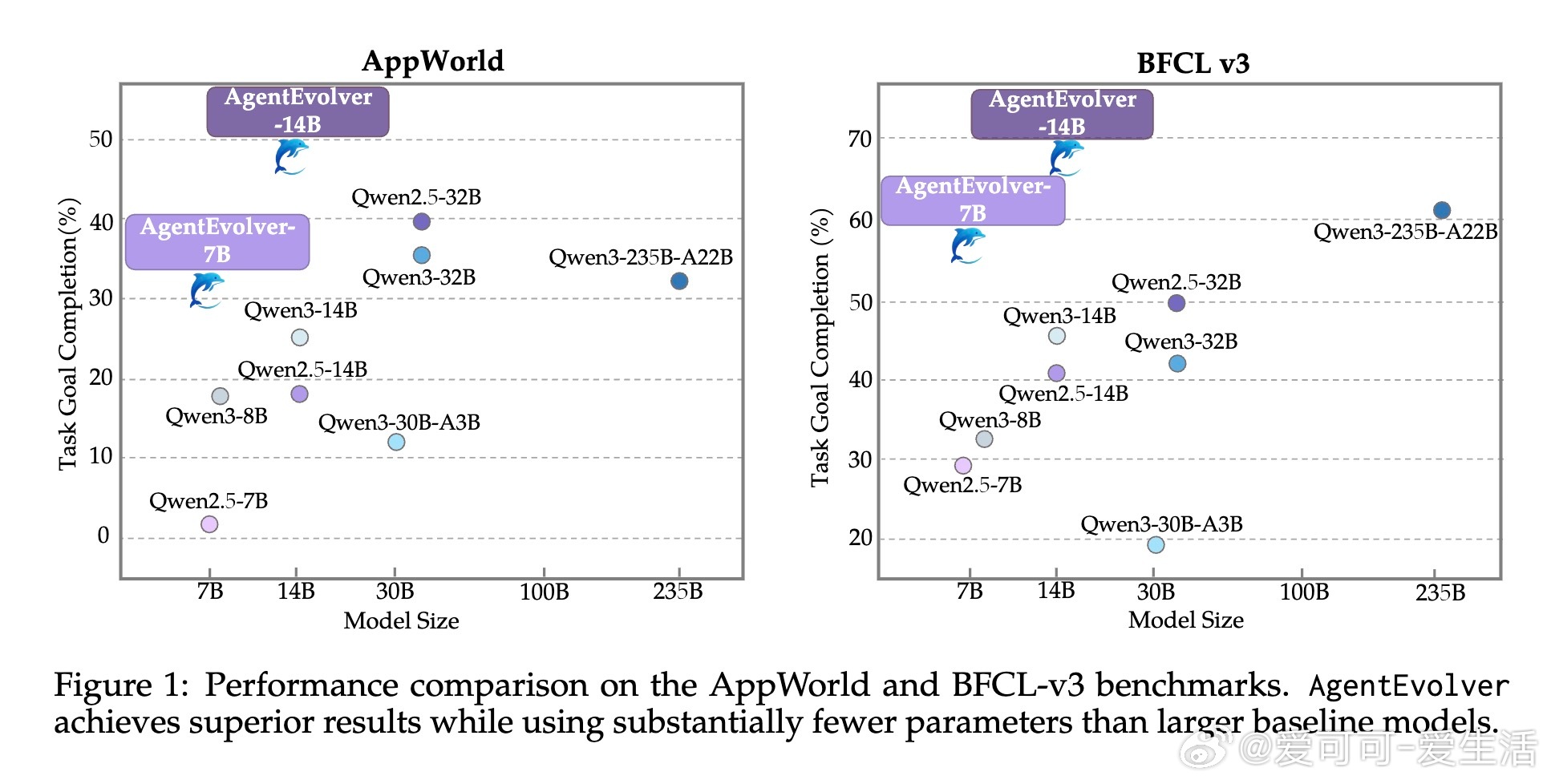
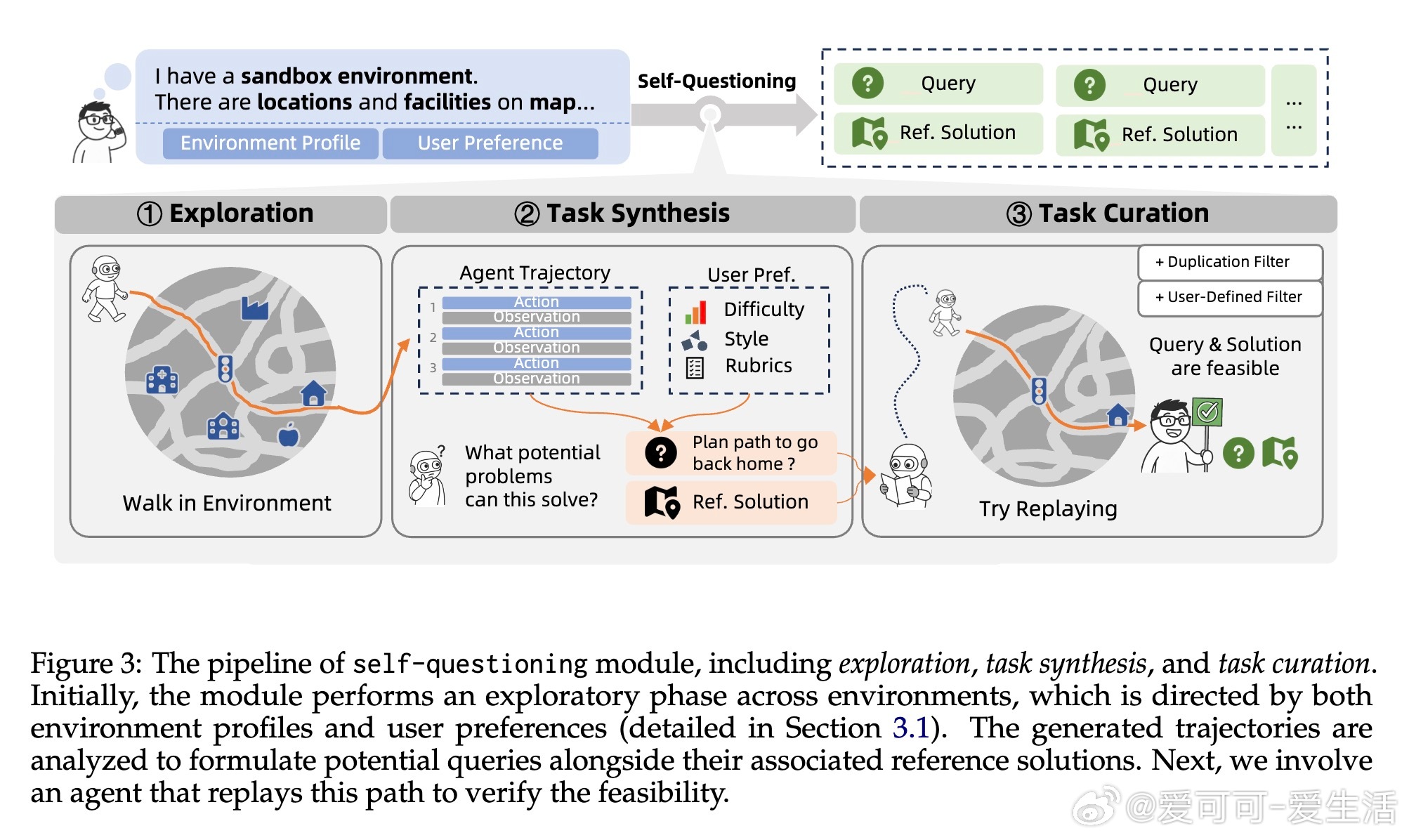
[LG]《AgentEvolver: Towards Efficient Self-Evolving Agent System》Y Zhai, S Tao, C Chen, A Zou... [Tongyi Lab] (2025) AgentEvolver:打造高效自我进化智能体系统随着大语言模型(LLM)在推理、工具使用和复杂任务执行上的突破,自主智能体正成为提升人类生产力的关键驱动力。然而,现有方法依赖人工构建的任务数据和大量随机探索的强化学习(RL)流程,导致数据成本高昂、探索效率低、样本利用率差,难以适应新环境。为此,AgentEvolver提出了一种全新的自我进化框架,充分发挥LLM的语义理解与推理能力,实现智能体的自主学习与能力提升。框架核心包含三大协同机制:1. 自我提问(Self-Questioning):智能体以好奇心驱动,主动探索环境,自动生成多样且符合用户偏好的训练任务,极大降低对人工数据的依赖。2. 自我导航(Self-Navigating):通过构建和检索结构化“经验”,智能体高效复用历史经验,采用混合策略平衡探索与利用,提升样本效率和任务完成质量。3. 自我归因(Self-Attributing):利用LLM对轨迹中每一步的贡献进行精细化评估,赋予差异化奖励,解决传统稀疏奖励无法准确区分关键步骤的问题,显著提升训练效果和样本利用率。AgentEvolver围绕“环境—任务—轨迹—策略”的训练流程,将上述机制有机整合,形成闭环自我训练体系,推动智能体持续进化。配套设计了模块化、服务化的训练架构和上下文管理器,支持多轮复杂交互及长时记忆管理,具备良好扩展性和环境兼容性。实验证明,AgentEvolver在AppWorld和BFCL v3等长时、多步骤工具交互任务上,较传统GRPO基线显著提升任务完成率,7B和14B模型规模均实现30%以上性能跃升,验证了合成任务数据、经验指导探索和归因奖励的有效性。此外,细致的消融分析揭示各机制的独立贡献及交互效应。未来,AgentEvolver将聚焦挑战性应用扩展、更大规模模型适配及实现LLM级别的自我进化,推动智能体从环境感知、任务生成、经验积累到策略优化的全流程内生提升,迈向更高效、可扩展和持续进化的智能系统。更多详情请访问:arxiv.org/abs/2511.10395