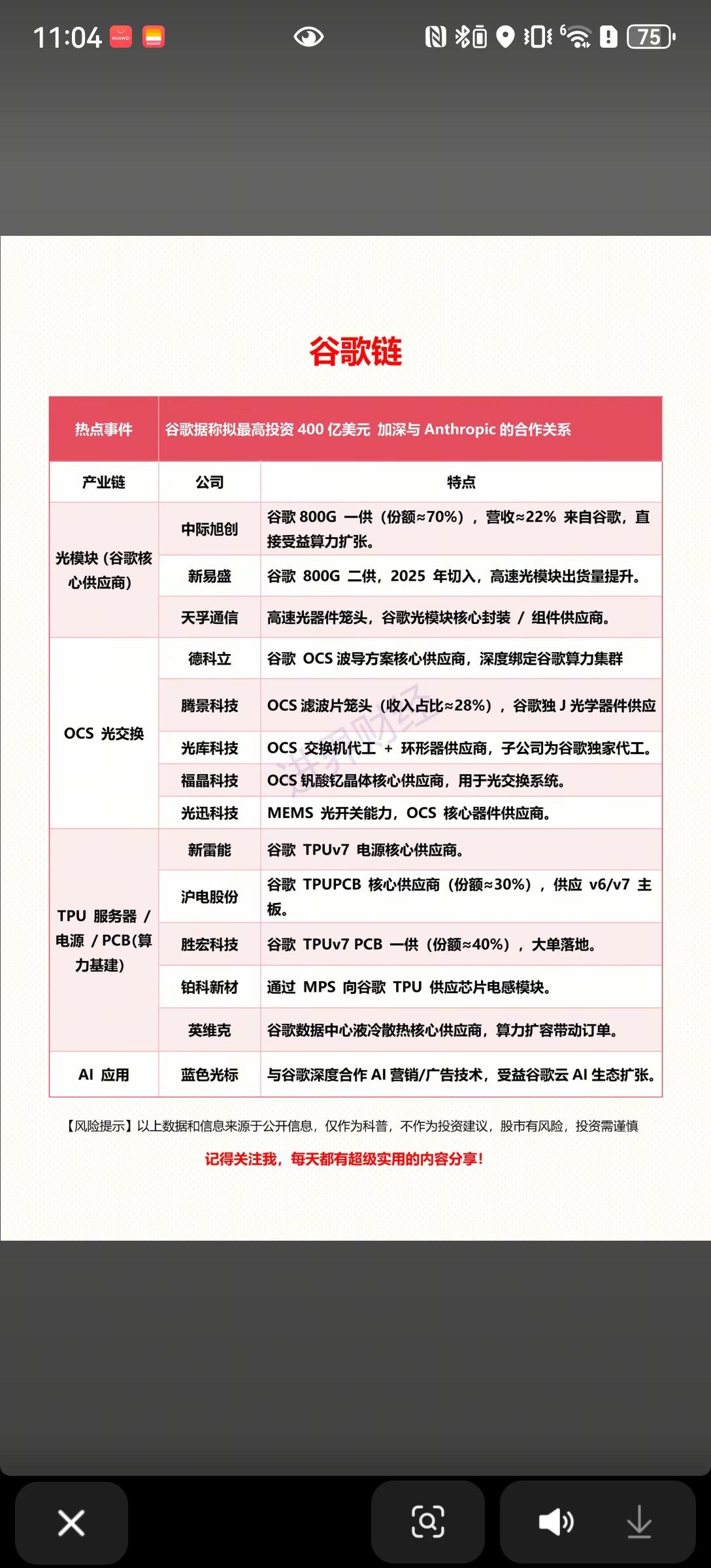
谷歌 TPU v8 解读
谷歌把 AI 芯片一刀切成两半,一块专门用于训练大模型,一块专门用于运行推理,因为这两项任务所需的硬件架构和核心需求已经完全不同。
训练芯片(8t):追求极致规模
一口气可串联 13.4 万颗芯片进行大模型训练,最大规模还可进一步扩展至 100 万颗。
首次支持 4-bit 计算(FP4),在同等算力规模下,运算速度实现翻倍提升。
存储读取速度相比上一代产品快 10 倍,彻底解决芯片等待数据传输的核心痛点,实现数据与计算的高效匹配。
推理芯片(8i):追求极致低延迟
芯片内部集成了 3 倍大的缓存,在 AI 对话等实时交互场景中,无需反复远距离调取数据,显著提升响应速度。
新增同步加速器(CAE),让多颗芯片协同工作时,彼此间的等待时间缩短 80%,大幅提升集群协作效率。
最关键的创新:互联拓扑重构
将传统的"邻居串门"式互联拓扑,升级为全员直连模式。
针对 MoE 模型,每个 token 可能需要调用任意专家模块,不再需要逐跳跳转,最多 7 跳即可到达任意芯片,传输效率比之前提升一倍。
核心突破并非单纯算力提升,而是架构分叉 —— 训练芯片(8t)采用 Torus 架构追求极致规模,推理芯片(8i)则通过 Boardfly 架构 + 同步加速器 + 大容量 SRAM,专攻低延迟需求。
MoE 模型改变了传统通信模式,推理集群全面采用 OCS 全互联技术。
隐藏关键细节:推理芯片的光路交换机(OCS)
推理芯片的"全员直连"互联,核心依赖光路交换机(OCS)。
光路交换机直接通过光信号进行连接切换,无需电信号转换,实现极低延迟传输。
此前光路交换机仅在训练集群使用,如今推理集群也全面部署,直接推动相关产业链市场空间翻倍。
谷歌第八代 TPU 对比上一代 Ironwood 核心提升
训练性价比提升 2.7 倍,推理性价比提升 1.8 倍,整体能效实现翻倍。
存储访问速度快 10 倍,片上缓存容量大 3 倍,多芯片协作等待时间缩短 5 倍。
芯片间互联带宽翻倍,数据中心骨干网带宽最高翻 4 倍。
全互联通信跳数从 16 跳降至 7 跳,减少 56% 的通信损耗。
推理芯片 HBM 容量从 216GB 提升至 288GB,带宽从 6528GB/s 提升至 8601GB/s。
集群规模从数万颗芯片扩展至 13.4 万颗,最大可连接 100 万颗芯片。
对英伟达的核心影响
若谷歌对外售卖 TPU,将对英伟达形成显著冲击,但真正威胁并非来自 TPU 产品本身。
核心威胁是 TPU 验证的"训练 / 推理分叉"路线,将被行业广泛采用。
行业共识显示,推理算力需求是训练的 3-5 倍,若推理市场被自研 ASIC 芯片逐步蚕食,英伟达的可触达市场规模将大幅缩水。
行业连锁反应
CSP 厂商纷纷开启自研芯片布局,达子(高端芯片)的稀缺性逐渐稀释,不再是唯一核心选择。
推理 ASIC 芯片迎来发展机遇,芯原和翱捷(刚成立子公司)将迎来业务发展的黄金时期。
工艺层面核心受益:天孚通信
推理芯片的 OCS 全互联技术,直接利好 OCS 产业链,其中天孚通信是核心受益标的。
OCS 核心部件为 MEMS 微镜阵列,天孚通信负责微镜的封装与光纤耦合工艺。
FAU 光纤阵列为天孚通信自产核心产品,OCS 的每个端口均需配备该部件。
天孚通信最新公告
公司配合客户开发 CPO 配套 FAU、ELS 产品,并持续增加产能,其核心客户即为谷歌、英伟达等全球顶尖科技企业。
公司 1.6T 光引擎已处于量产状态,目前因个别物料缺料暂未达到预期产量,正积极协调供应商,争取增加产品交付量。
其他 OCS 产业链受益标的
腾景、赛微、光库等企业,同样具备 OCS 产业链受益逻辑,将同步分享行业发展红利。